《差旅壹号》专题
-
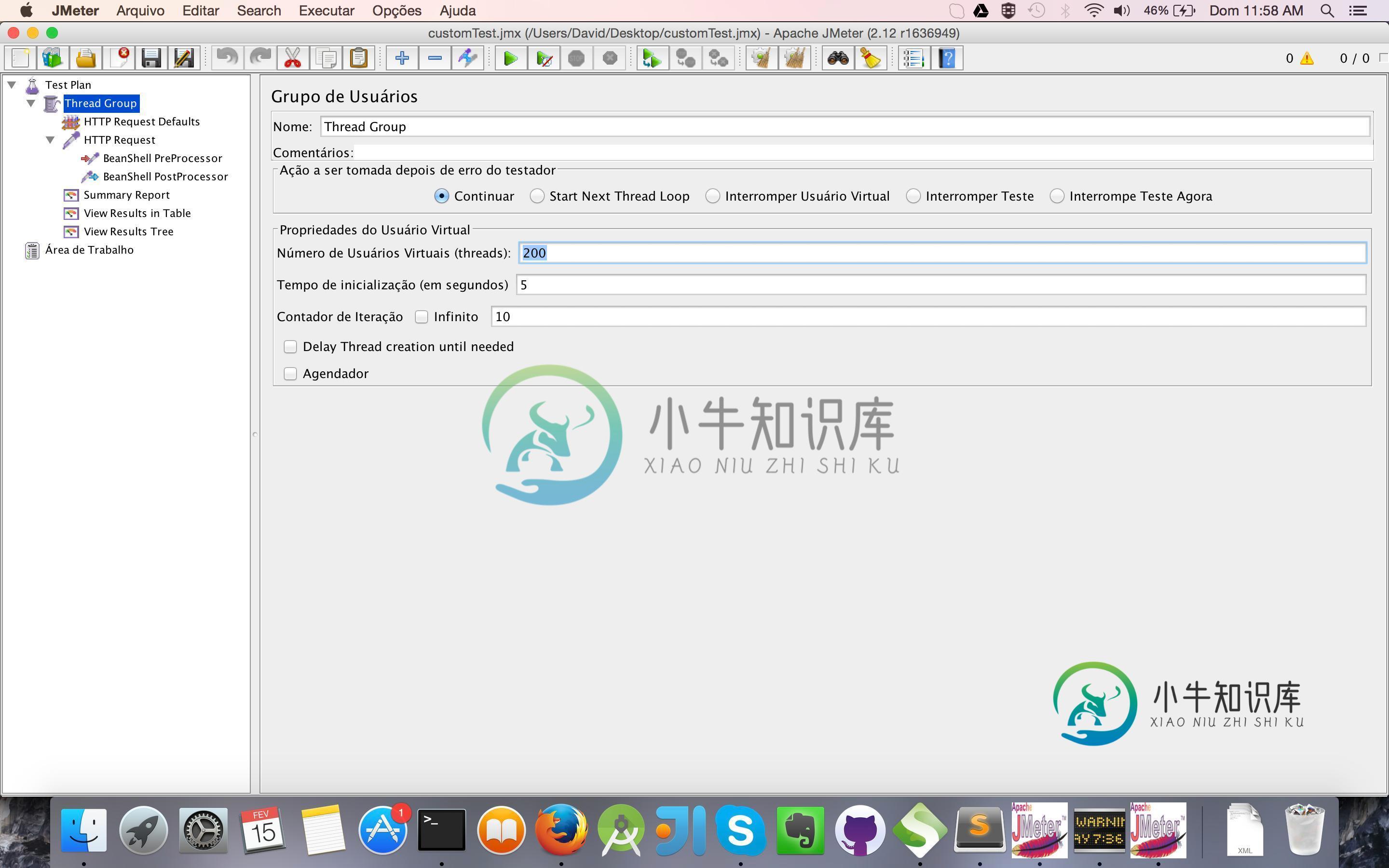 jmeter响应时间与我在日志文件中看到的差异
jmeter响应时间与我在日志文件中看到的差异我已经搜索了堆栈溢出,但没有找到任何接近我需要的东西,所以如果它是重复的,告诉我,我会删除这篇文章。 我有一个web应用程序,它是一个单一的REST服务,只执行一个Thread.Sleep(10000)。如果方法只Hibernate10秒,那么我的所有请求都应该有10-11秒的平均响应时间,对吗? 要在JMeter上测试它,通常我使用200个线程和5秒的斜坡。当测试开始时,我的平均响应时间保持在1
-
将整数列表分区,以最小化它们总和的差异
给定一个整数列表,我如何将其划分为两个列表和,使得最小。我知道这个问题是NP完全的,所以我正在寻找一个伪多项式时间算法,即其中。我看了维基百科,但是算法是把它分成精确的两半,这是我要找的一个特例... 编辑:为了澄清,我正在寻找确切的分区和,而不仅仅是产生的最小差异 概括地说,什么是伪多项式时间算法,将一个数字列表划分成组,使得S=[和(g1),和(g2),...和(gk)]
-
计算两个相邻数字之间的最大和最小差值
具有矩阵A的: 我想计算所有行中两个相邻数字之间的最大和最小差异。然后过滤以仅限制相邻数字min小于4和7之间的行,最大值在6和12之间的行。输出应该返回无行。 对于以下矩阵: 结果应该是第1行
-
 PromQL中具有时间偏移的两个指标之间的差异
PromQL中具有时间偏移的两个指标之间的差异我有一个度量(量规),它有标签,该标签设置为模块的名称。模块在成功执行“更新”(无论它是什么意思)后,现在将其设置为UTC。其中一个模块(称为“main”)必须在任何其他模块更新后的10分钟内执行更新。 尝试#1从“主要”指标中提取所有其他指标的最大值: 它部分有效。在“其他”指标已更新,但“主要”指标尚未更新的时间段内,它会失败: 尝试#2 选择具有10分钟偏移量的“其他”度量,因此我们总是将“
-
如何逐行比较和统计两个文件之间的差异?
我需要逐行比较两个文件。在每个文件中,行只有1或-1,所以如果行相同,就不要计数,如果行不同,就计数=+1。 例如:
-
分支预测和分支目标预测之间的性能差异?
我正在编写一些音频代码,其中基本上所有内容都是一个小循环。据我所知,分支预测失败是一个足够大的性能问题,我很难保持代码分支的自由。但是只有这么远的时间才能带我,这让我想知道不同类型的分支。 在 c 中,固定目标的条件分支: 并且(如果我正确理解这个问题),无条件分支到变量目标: 是否存在性能差异?在我看来,如果这两种方法中的一种明显快于另一种,编译器只需将代码转换为匹配即可。 对于那些分支预测非常
-
在MATLAB中生成给定均值和标准差的随机数据?
我有有限的数据RV,我可以找到平均mu和标准差sigma。现在我想生成更多的数据点保持相同的mu和sigma。在MATLAB中我怎么做呢?我做了以下工作,但是当我绘制生成的数据(mu_2)的平均值时,它不匹配MU...
-
与单元测试控制器和服务方法的差异[重复]
我想从控制器和服务层测试相同的方法。问题是:为什么我必须在控制器中使用注释,为什么不为使用注释。对于服务,同样的问题是,为什么我需要存储库,为什么不使用?你能告诉我这两者的区别吗? 这里是控制器: 这里是服务类: 服务测试: 控制器测试:
-
Jmeter-线程组和循环控制器在性能方面的差异
我对JMeter是新手。这里有一件事让我困惑 我正在测试两个使用Jmeter计算性能数字的场景 具有1个线程组集且循环计数设置为50,并且具有一个https采样器。 具有循环计数仅为1的1个线程组,但使用循环计数设置为50的循环控制器。在本例中,我的https采样器位于循环计数中。 在这两种情况下,https采样器都运行了50次,但我注意到了很多性能差异。 问题是为什么我会看到这种差异。理想情况下
-
使用java[duplicate]以秒为单位查找日期之间的差异
我被困在java之间。时间世俗的ChronoUnit和java。时间世俗的暂时的直到。它们是如何工作的??
-
通过权重和偏差在keras中记录学习速率计划
我正在训练keras模型,并为优化器使用自定义学习速率调度程序(类型为tf.keras.optimizers.schedules.LearningRateSchedule),我希望通过权重记录学习速率的变化
-
康达创建环境中康达列表与pip列表的差异
我使用的是conda版本4.5.11,python 3.6.6和Windows 10。 我使用conda创建了一个虚拟环境 当我检查已安装的软件包时 它是(如预期的那样),为空。 但是 相当长。 问题#1:为什么?-当我使用 点数列表为空。 当我不在激活的虚拟环境中时,那么 也相当长,但它与pip列表不同(*请参见下文的后续内容)。通常,pip列表是conda列表的一个子集。至少有一个例外(“表”
-
Java 8-reduce(0,integer::sum)与reduce(0,(a,b)->a+b)之间的差异
-
DateTime.now()。toUtc()。difference和DateTime.now()。在飞镖中,差异产生相同的结果
基本上是标题。我想得到日期时间和当前时间之间的差异。日期以UTC为单位,我首先将当前时间转换为UTC,然后找到差异。但在两种情况下,转换为UTC或不转换为UTC的差异是相同的,但不应如此。 结果是 内/扑动 (20796): 2020-07-01 15:33:46.221975Z I/颤动 (20796): 2020-07-01 21:03:46.222207 I/颤振 (20796): 361
-
如何计算Pandas中滚动窗口中的波动率(标准差)