
Intel Skylake上存储循环的双峰性能出乎意料的差

我看到一个简单的存储循环的性能出乎意料的差,它有两个存储:一个是16字节的前进步幅,另一个总是在同一个位置1,如下所示:
volatile uint32_t value;
void weirdo_cpp(size_t iters, uint32_t* output) {
uint32_t x = value;
uint32_t *rdx = output;
volatile uint32_t *rsi = output;
do {
*rdx = x;
*rsi = x;
rdx += 4; // 16 byte stride
} while (--iters > 0);
}
在程序集中,此循环3可能如下所示:
weirdo_cpp:
...
align 16
.top:
mov [rdx], eax ; stride 16
mov [rsi], eax ; never changes
add rdx, 16
dec rdi
jne .top
ret
当访问的内存区域在L2中时,我希望它在每次迭代中运行少于3个周期。第二个商店只是不断击中相同的位置,应该增加大约一个循环。第一个存储意味着从L2引入一行,因此每4次迭代也会逐出一行。我不确定如何评估L2成本,但即使保守地估计L1每个周期只能执行以下操作之一:(a)提交一个存储或(b)从L2接收一行或(c)将一行逐出到L2,对于stride-16存储流,您将得到1+0.25+0.25=1.5个周期。
实际上,注释掉一个存储,第一个存储的每次迭代只有1.25个周期,第二个存储的每次迭代只有1.01个周期,所以每次迭代2.5个周期似乎是保守的估计。
然而,实际的表现是非常奇怪的。下面是测试工具的一个典型运行:
Estimated CPU speed: 2.60 GHz
output size : 64 KiB
output alignment: 32
3.90 cycles/iter, 1.50 ns/iter, cpu before: 0, cpu after: 0
3.90 cycles/iter, 1.50 ns/iter, cpu before: 0, cpu after: 0
3.90 cycles/iter, 1.50 ns/iter, cpu before: 0, cpu after: 0
3.89 cycles/iter, 1.49 ns/iter, cpu before: 0, cpu after: 0
3.90 cycles/iter, 1.50 ns/iter, cpu before: 0, cpu after: 0
4.73 cycles/iter, 1.81 ns/iter, cpu before: 0, cpu after: 0
7.33 cycles/iter, 2.81 ns/iter, cpu before: 0, cpu after: 0
7.33 cycles/iter, 2.81 ns/iter, cpu before: 0, cpu after: 0
7.34 cycles/iter, 2.81 ns/iter, cpu before: 0, cpu after: 0
7.26 cycles/iter, 2.80 ns/iter, cpu before: 0, cpu after: 0
7.28 cycles/iter, 2.80 ns/iter, cpu before: 0, cpu after: 0
7.31 cycles/iter, 2.81 ns/iter, cpu before: 0, cpu after: 0
7.29 cycles/iter, 2.81 ns/iter, cpu before: 0, cpu after: 0
7.28 cycles/iter, 2.80 ns/iter, cpu before: 0, cpu after: 0
7.29 cycles/iter, 2.80 ns/iter, cpu before: 0, cpu after: 0
7.27 cycles/iter, 2.80 ns/iter, cpu before: 0, cpu after: 0
7.30 cycles/iter, 2.81 ns/iter, cpu before: 0, cpu after: 0
7.30 cycles/iter, 2.81 ns/iter, cpu before: 0, cpu after: 0
7.28 cycles/iter, 2.80 ns/iter, cpu before: 0, cpu after: 0
7.28 cycles/iter, 2.80 ns/iter, cpu before: 0, cpu after: 0
这里有两件事很奇怪。
Skylake被记录为在L1和L2之间具有64B/Cycle吞吐量,远高于这里观察到的吞吐量(慢速模式下约2字节/Cycle)。
如何解释低吞吐量和双峰性能,我能避免它吗?
我也很好奇这是否能在其他的建筑上复制,甚至在其他的Skylake盒子上复制。请随意在评论中包含本地结果。
您可以在GitHub上找到测试代码和harness。对于Linux或类似UNIX的平台有makefile,但在Windows上构建它也应该相对容易。如果您想运行asm变体,您需要为程序集4运行nasm或yasm-如果您没有这些,您可以尝试C++版本。
这里有一些可能性,我考虑过,并在很大程度上排除了。许多可能性都被这样一个简单的事实消除了,即您在基准测试循环的中间看到性能的随机转变,而许多事情根本没有改变(例如,如果它与输出数组对齐有关,那么它在运行的中间就无法改变,因为整个时间都使用同一个缓冲区)。我将在下面把它称为缺省消除(即使是缺省消除的东西,也经常要做另一个论证)。
-
null
我使用了toplev.py,它实现了Intel的自顶向下分析方法,毫不奇怪,它将基准识别为store绑定:
BE Backend_Bound: 82.11 % Slots [ 4.83%]
BE/Mem Backend_Bound.Memory_Bound: 59.64 % Slots [ 4.83%]
BE/Core Backend_Bound.Core_Bound: 22.47 % Slots [ 4.83%]
BE/Mem Backend_Bound.Memory_Bound.L1_Bound: 0.03 % Stalls [ 4.92%]
This metric estimates how often the CPU was stalled without
loads missing the L1 data cache...
Sampling events: mem_load_retired.l1_hit:pp mem_load_retired.fb_hit:pp
BE/Mem Backend_Bound.Memory_Bound.Store_Bound: 74.91 % Stalls [ 4.96%] <==
This metric estimates how often CPU was stalled due to
store memory accesses...
Sampling events: mem_inst_retired.all_stores:pp
BE/Core Backend_Bound.Core_Bound.Ports_Utilization: 28.20 % Clocks [ 4.93%]
BE/Core Backend_Bound.Core_Bound.Ports_Utilization.1_Port_Utilized: 26.28 % CoreClocks [ 4.83%]
This metric represents Core cycles fraction where the CPU
executed total of 1 uop per cycle on all execution ports...
MUX: 4.65 %
PerfMon Event Multiplexing accuracy indicator
这并不能说明问题:我们已经知道一定是商店把事情搞砸了,但为什么呢?英特尔对病情的描述并没有说明太多。
以下是一语-二语互动中涉及的一些问题的合理总结。
1这是我的原始循环的一个大大简化的MCVE,它的大小至少是原来的3倍,并且做了很多额外的工作,但表现出与这个简单版本完全相同的性能,在同一个神秘问题上遇到了瓶颈。
3特别是,如果您手工编写程序集,或者使用gcc-o1(版本5.4.1)编译程序集,并且可能使用最合理的编译器(volatile是为了避免在循环外下沉几乎死气沉沉的第二个存储区),则会与此完全相同。
4毫无疑问,您可以将其转换为MASM语法,只需进行一些小的编辑,因为程序集非常简单。已接受拉取请求。
共有1个答案

我目前所发现的。不幸的是,它并没有为性能差提供解释,也没有为双峰分布提供解释,而是为您何时可能看到性能提供了一组规则,并提供了关于如何减轻性能的说明:
- 进入L2的存储吞吐量似乎是每三个周期最多一个64字节的高速缓存线0,这使存储吞吐量达到了每周期21字节的上限。换句话说,在L1中未命中而在L2中命中的系列存储将至少需要三个周期的高速缓存线。
- 当在L2中命中的存储与到不同高速缓存行的存储交错时(无论那些存储是在L1还是L2中命中),超过该基线会有显著的损失。
- 对于附近的存储(但仍不在同一高速缓存行中),损失显然要大一些。
- 双峰性能至少在表面上与上述效应有关,因为在非交错的情况下,它似乎不会发生,尽管我对此没有进一步的解释。
- 如果通过预取或虚拟加载确保缓存行在存储之前已经在L1中,则慢速性能消失,性能不再是双峰的。
原题任意使用了16的步幅,但让我们从可能最简单的情况开始:步幅64,即一个完整的缓存行。结果表明,不同的效果在任何步幅上都是可见的,但是64确保了每一步幅上的L2缓存丢失,因此删除了一些变量。
让我们现在也删除第二个存储--所以我们只是在64K内存上测试一个64字节的跨步存储:
top:
mov BYTE PTR [rdx],al
add rdx,0x40
sub rdi,0x1
jne top
在与上面相同的线束中运行,我得到了3.05个循环/存储2,尽管与我习惯看到的相比有相当多的差异(--你甚至可以在那里找到3.0)。
所以我们已经知道,对于纯L21的持续存储,我们可能不会做得更好。虽然Skylake在L1和L2之间显然有64个字节的吞吐量,但对于存储流的情况,必须共享该带宽,以便从L1逐出并将新线路加载到L1。如果每个周期都需要1个周期来(a)将脏的受害者行从L1移出到L2(b)用来自L2的新行更新L1和(c)将存储提交到L1,那么3个周期似乎是合理的。
当您在循环中对同一高速缓存行(对下一个字节,尽管结果不重要)添加do第二次写入时会发生什么?像这样:
top:
mov BYTE PTR [rdx],al
mov BYTE PTR [rdx+0x1],al
add rdx,0x40
sub rdi,0x1
jne top
下面是上述循环测试线束运行1000次的时间直方图:
count cycles/itr
1 3.0
51 3.1
5 3.2
5 3.3
12 3.4
733 3.5
139 3.6
22 3.7
2 3.8
11 4.0
16 4.1
1 4.3
2 4.4
所以大部分时间都聚集在3.5个周期左右。这意味着这个额外的存储只增加了0.5个周期的定时。这可能是类似于存储缓冲区能够将两个存储排到L1(如果它们在同一行中),但这种情况只发生大约一半的时间。
让我们通过查看第一和第二商店之间的各种偏移来检验这一理论:
top:
mov BYTE PTR [rdx + FIRST],al
mov BYTE PTR [rdx + SECOND],al
add rdx,0x40
sub rdi,0x1
jne top
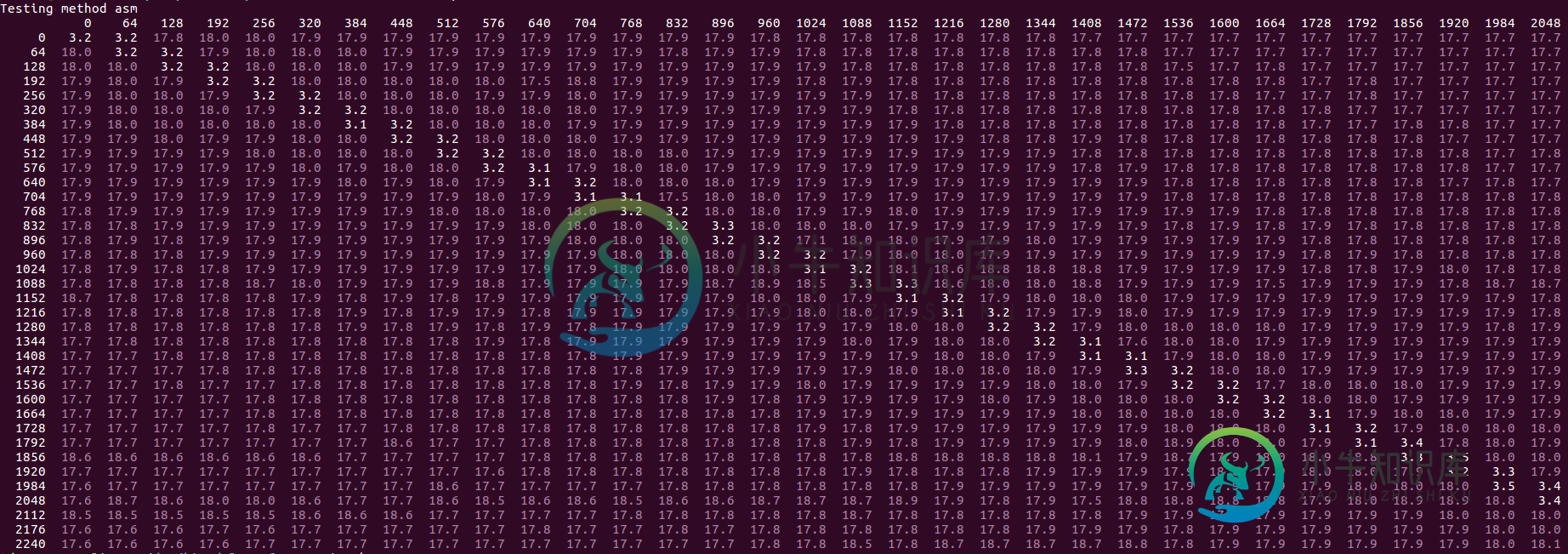
我们尝试first和second的所有值,从0到256,步长为8。结果(垂直轴上的第一值和水平轴上的第二值不同):
我们看到一个特定的模式--白色值是“快速”的(大约是上面讨论的3.0-4.1值,偏移量为1)。黄色值更高,最多可达8个循环,红色最多可达10个循环。紫色异常值是最高的,通常是OP中描述的“慢速模式”启动的情况(通常以18.0个周期/iter的频率计时)。我们注意到以下情况:
紫色的“离群值”从来不会出现在白色区域中,所以显然只限于已经很慢的情况(这里越慢,它就会慢2.5倍:从8到18个周期)。
我们可以放大一点,看看更大的偏移:
相同的基本模式,尽管我们看到随着第二个存储区离第一个存储区更远(在前面或后面),性能有所改善(绿色区域),直到它在大约1700字节的偏移处再次变差。即使在改进的领域,我们也只能达到最多5.8个循环/迭代,仍然比3.5的同行性能差得多。
如果添加任何类型的加载或预取指令,该指令在存储的3之前运行,则整体慢速性能和“慢速模式”异常值都将消失:
您可以将它返回到原来的步长16的问题--在核心循环中进行任何类型的预取或加载,对距离几乎不敏感(即使它实际上落后了),解决了这个问题,您得到2.3个循环/迭代,接近于可能的最佳理想值2.0,并且等于具有单独循环的两个存储的总和。
因此,基本规则是,在没有相应负载的情况下,存储到L2的速度要比软件预取慢得多--除非整个存储流以单个顺序模式访问高速缓存行。这与这样的线性模式从未受益于SW预取的想法相反。
我没有一个具体的解释,但它可以包括以下因素:
- 在存储缓冲区中具有其他存储可能会降低去往L2的请求的并发性。L1中丢失的存储区何时分配存储区缓冲区并不清楚,但可能发生在存储区即将退出时附近,存储区缓冲区中有一定数量的“lookhead”将位置带入L1,因此L1中不会丢失的其他存储区会损害并发性,因为lookahead无法看到丢失的请求数量。
- 可能L1和L2资源存在冲突,如读写端口、缓存间带宽,这种存储模式更糟。例如,当不同行的存储交错时,它们可能无法从存储队列中迅速排出(参见上面的内容,在某些情况下,每个周期可能排出多个存储)。
McCalpin博士在英特尔论坛上的这些评论也相当有趣。
0大多数情况下只能在禁用L2流光的情况下实现,否则L2上的附加争用会将其减慢到大约每3.5个周期1行。
1将此与存储区进行对比,在存储区中,每次负载几乎正好得到1.5个周期,每个周期的隐含带宽为43字节。这是完全有意义的:L1<->L2带宽为64字节,但假设L1每个周期接受来自L2的线路或服务来自内核的负载请求(但不是两个周期并行),那么您有3个周期用于对不同的L2线路进行两次负载:2个周期用于接受来自L2的线路,1个周期用于满足两次负载指令。
2并关闭预取。结果是,当L2预取器检测到流访问时,它会竞争对L2缓存的访问:即使它总是找到候选行,而不会进入L3,这会减慢代码的速度并增加可变性。在预取开启的情况下,结论通常是成立的,但一切都只是慢了一点(这里有一大块预取开启的结果--您可以看到每加载3.3个周期,但变化很大)。
3它甚至真的不需要在前面--预取后面几行也是有效的:我猜预取/加载只是快速地运行在有瓶颈的存储的前面,所以它们无论如何都能在前面。这样,预取是一种自我修复,似乎与您投入的几乎任何值一起工作。
-
在以前的工作中,我们必须比较项目x和项目x-1以获得大量数据(~10亿行)。由于这是在SQL Server2008R2上完成的,我们必须使用自联接。很慢。 我想我要试验一下滞后函数;如果速度快,这将是非常有价值的。我发现它快了2到3倍,但由于它应该是一个简单的操作,而且它的查询计划/表扫描更简单/大大减少了,所以我非常失望。下面复制的代码。 创建数据库: 返回: 编辑: 根据@vnov的评论,在我
-
问题内容: 因此,我希望它不会被编译,并且不会: 但这确实是: 是什么赋予了?它也不应该编译吗? 另外,由于运算符,这个问题很难找到。 问题答案: Java将工作解释为1加2。请参见Unary运算符部分。
-
注意:我已经在另一篇文章中解决了这个问题,所以在嵌套的Java8并行流操作中使用信号量可能会造成死锁。这是窃听器吗?-,但这篇文章的标题暗示问题与一个信号量的使用有关--这多少分散了讨论的注意力。我创建这个例子是为了强调嵌套循环可能存在性能问题--尽管这两个问题可能有一个共同的原因(也许是因为我花了很多时间来解决这个问题)。(我不认为它是一个重复,因为它强调了另一个症状--但如果你真的这么做了,就
-
(线程:持续时间)-->(1:16)、(2,3:32)、(4,5,6,7:47)、(8,9:31)...(17,18,19,20:16) 该项目有2个项目: 工人阶层: 主类:
-
我正在对大小为50,000个元素的两个向量执行基于元素的操作,并且有不满意的性能问题(几秒钟)。是否存在明显的性能问题,例如使用不同的数据结构?
-
我的Windows批处理文件中出现了“此时转到意外”错误。就像下面一样。我不知道。有人能帮我吗?谢谢