《差旅壹号》专题
-
比较两个xml文件并获得差异
我试图比较两个XML文件。我的要求是比较新旧xml文件,如果有任何差异,将其合并到新的xml文件中。 但我也想要差异。请告诉我怎样才能得到不同之处。 我已经尝试过XMLUnit,但我不想使用它。
-
“make install”和“make altinstall”之间的细节差异
下面是我的案例: 第一次安装的时候,我跑: 这将Python2.7安装到我的系统中。它将在中创建链接“python”,链接到中的。所以当我键入时,系统将为我启动Python 2.7.4,就像键入时一样。 但当我这样安装时: 中的链接“python”仍然存在,并且链接到这是默认的系统版本。当然,我可以移除它并创建一个新的链接到的软链接。 除了中的链接之外,命令“make install”和“make
-
Java指数误差为2^31次方[重复]
-
如何在java中接收地图的差异?
我有两张地图: 我需要得到这些地图之间的差异。是否存在可能是apache utils如何接收这种差异?目前,似乎需要获取每个映射的条目集,并找到diff1=set1-set2和diff2=set2-set1。创建摘要映射=diff1 diff2之后,它看起来非常笨拙。存在另一种方式吗?谢谢
-
LongSerializer和Serdes.LongSerde之间的Kafka序列化差异
序列化程序的主要链接文档:https://kafka.apache.org/11/javadoc/org/apache/kafka/common/serialization/package-frame.html LongSerializer:https://kafka.apache.org/11/javadoc/org/apache/kafka/common/serialization/longS
-
性能差异:map()与peek()使用setter[重复]
我想知道下面两个场景中是否有任何性能差异——peek()和map()带返回: 或 我在stackoverflow上读了几篇关于map()和peek()中setter的文章,我只发现了一个关于性能的信息。它说带有返回的map()会更糟,但没有解释为什么:如何在Stream链中调用setter
-
相对排样误差中的线性排样
//这是线性布局引起的错误 //线性布局结束
-
使用加速器规范化视差图像
我有一个视差图像,我正在使用下面的示例代码对其进行规范化,但速度非常慢。我需要使用一些加速器,比如定制的CIFilter或任何其他技术,但我不知道怎么做?我目前正在用CIContext()运行代码,它正在CPU上运行(不确定)。有没有办法在GPU上运行它并在没有定制CIfilter的情况下加速?以下是当前代码:
-
火花2.0.2和2.1.1之间的缓存差异
如何在2.1.1中存档相同的行为? 谢谢你。
-
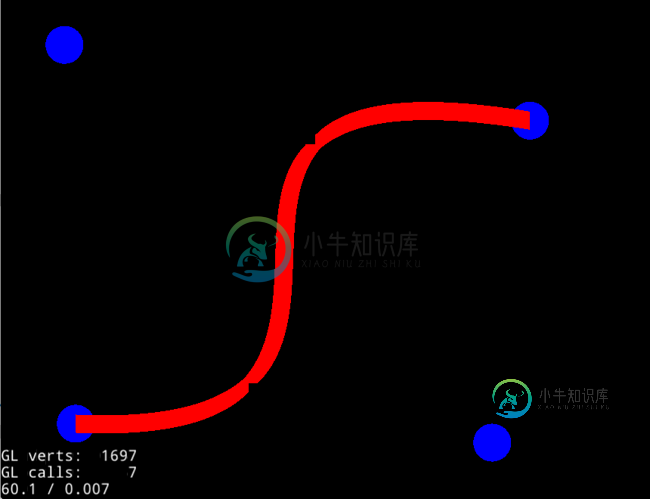 绘制三次bezier曲线的COCOS2D-X-误差
绘制三次bezier曲线的COCOS2D-X-误差我试图画一条具有一定厚度的三次bezier路径,但曲线看起来像是一系列断开的线段(在我的例子中是3段)。这是一张截图(蓝色圆圈是曲线的控制点)。 我注意到在cocos2d-x测试中的“绘制原语”中也出现了同样的效果。不管怎样,我很确定应该有一个变通办法,但我自己找不到。此外,线条受到锯齿效应的影响,我不知道如何应用一个alpha阴影来避免它。 这是我使用的代码:
-
Protégé:DL查询和SPARQL查询结果的差异
这里有一个名为的小本体,由Protégé创建,其中我有类、、、和个体()、()和(也是)。在本体论中,我只声明。 当我在Protégé的DL Query选项卡中请求的实例时,我得到的是(它是,因此是,因此是)。 但当我编写以下SPARQ查询时: 我没有任何例子。当我将替换为时,结果是相同的。只有当我用替换它时,我才会得到所需的结果。 为什么DL查询做推断(允许我获得作为类的实例),而不是SPARQ
-
Android Studio和Intellij Idea之间的插件差异?
我们有一个现有的java代码库,在那里我们使用intellij idea进行开发。 如果我们将Intellij Idea与各种Android支持插件一起使用,这些插件是否与Android Studio中的插件相同?有了这套插件,程序实际上是可以互换的吗? (我确实注意到Android Studio中没有“ant”支持。虽然我所需要的只是一些从IDE调用可执行文件的能力,其中包含一组菜单可配置项,用
-
与 NW.js(原 node-webkit)在技术上的差异
备注:Electron 的原名是 Atom Shell。 与 NW.js 相似,Electron 提供了一个能通过 JavaScript 和 HTML 创建桌面应用的平台,同时集成 Node 来授予网页访问底层系统的权限。 但是这两个项目也有本质上的区别,使得 Electron 和 NW.js 成为两个相互独立的产品。 1. 应用的入口 在 NW.js 中,一个应用的主入口是一个页面。你在 pac
-
E.5. 线程软件包之间的差异
MySQL非常依赖使用中的线程软件包。 所以当为MySQL选择一个好平台的时候,线程软件包就非常重要。 至少有三种线程软件包: 用户线程在单个进程中。线程切换用警报管理,线程库用锁管理所有非线程安全函数。读,写和选择操作通常被线程专有的切换器管理,如果运行中的线程要等待数据,这个切换器就会切换操作到另一个线程。如果用户线程软件包集成在标准库(FreeBSD 和 BSDI 线程软件包)里,这样的线程
-
概率论11 协方差与相关系数
前面介绍的分布描述量,比如期望和方差,都是基于单一随机变量的。现在考虑多个随机变量的情况。我们使用联合分布来表示定义在同一个样本空间的多个随机变量的概率分布。 联合分布中包含了相当丰富的信息。比如从联合分布中抽取某个随机变量的边缘分布,即获得该随机变量的分布,并可以据此,获得该随机变量的期望和方差。这样做是将视线限制在单一的一个随机变量上,我们损失了联合分布中包含的其他有用信息,比如不同随机变量之