《内存》专题
-
如何永久增加java堆内存?
我在java堆内存方面有一个问题。我用java开发了一个客户机服务器应用程序,作为windows服务运行,它需要超过512MB的内存。我有2GB的RAM,但当我运行我的应用程序时,它抛出一个异常 内存不足错误:Java堆空间 但是我已经在java控制面板中设置了堆大小(最大值为512MB),我仍然得到相同的错误。我不能通过命令行设置堆大小,因为我的应用程序是作为windows服务运行的,所以如何增
-
踏频内存管理如何工作?
我想了解cadence-client如何为长期运行的工作流管理内存。假设一个工作流运行了6个月,但它在整个持续时间内都不处于活动状态。当客户端接收到与此工作流相关的信号,执行一些活动,然后再次变为空闲时,它将变为活动状态。我正在使用java库提供的< code>Workflow.await方法来实现这一点。 我的问题是,节奏如何管理这些空闲工作流(以及此工作流创建的所有状态变量)?由于工作流尚未完
-
 链接哈希地图内存消耗
链接哈希地图内存消耗用户上传一个由一百万字组成的巨大文件。我解析文件并将文件的每一行放入< code>LinkedHashMap中 我需要按键访问和删除O(1)。此外,我需要保留访问顺序,从任何位置迭代并排序。 内存消耗是巨大的。我启用了的重复数据删除功能,该功能出现在Java 8中,但事实证明,消耗了大部分内存。 我找到了< code>LinkedHashMap。Entry占用40个字节,但是只有2个指针——一个指
-
内存分配/解除分配?[关闭]
-
Google Maps Android API v2 SupportMapFragment内存泄漏
使用2个简单的活动。第一个活动,它只包含一个按钮来启动第二个活动,它包含地图: 主要活动: 映射活动: 映射活动的XML布局:
-
Quarkus。负载测试和内存利用
我创建了一个简单的服务,它执行4个HTTP调用和4个db调用来收集一些数据,并将其作为< code>JSON传递给< code>HTTP响应。 当我启动应用程序(本机,没有docker)时,我看到它消耗,有时,有时30MB。好。 当我开始加载测试它时,每10毫秒发送1个请求,总共100个请求。 我注意到内存消耗立即达到200MB。然后经过5-6次以上的测试到400MB。(就像Spring启动版本一
-
HttpURLConnection上的Tomcat内存泄漏警告
Tomcat 8.5中有以下警告,我不确定是否可以忽略 它发生在以下代码中的: 我是否应该在关闭
-
释放stringBuilder内存的最快方法
释放stringbuilder内存的最快方法是什么。 下面是我试图尽快释放内存并使对象符合垃圾收集条件的代码片段 备选案文1: 根据我的理解,stringBuilder中的所有数据都将被删除,对象一旦被踢入,就有资格获得垃圾回收机制,但stringBuilder占用的文本内存将被释放。它的字符串值也会从堆中删除,还是会存储在字符串池中? 选项2: 这将重置字符串生成器的长度,但不会被垃圾收集 选项
-
Nokia S40 Asha 305内存不足错误
在诺基亚s40 Asha 305设备中加载不同的网址时摆脱内存错误,但我的相同代码在Asha501中运行良好... 我必须做什么??任何人都可以帮助我。我已经添加了我的数据检索代码用于网络响应
-
使用Lodash memoize“JavaScript堆内存不足”
从Node.js heap out memory中我了解到,Node的标准内存使用量是1.7GB,我认为这应该足够了。有什么想法,为什么记忆版本不工作,以及如何修复它?
-
Spark分区大小大于executor内存
我有四个问题。假设在spark中有3个worker节点。每个工人节点有3个执行器,每个执行器有3个核心。每个执行器有5 gb内存。(总共6个执行器,27个内核,15GB内存)。如果: > 我有30个数据分区。每个分区的大小为6 GB。最佳情况下,分区的数量必须等于核心的数量,因为每个核心执行一个分区/任务(每个分区执行一个任务)。在这种情况下,由于分区大小大于可用的执行器内存,每个执行器核心将如何
-
JavaFX-加载映像和内存问题
我有一个问题,加载图像到我的应用程序。我正在尝试做一个简单的图像浏览器。在左边我有一个文件夹列表。单击列表上的文件夹名称后,图像应该出现在右侧(流窗格)。每个图像都在带有边框的HBox中。但我很快就会犯这样的错误: 我看任务管理器-如果我只加载6张照片,应用程序占用500MB的内存!还有一件事--如果我更改列表上的文件夹,内存就会被占用。在选择另一个文件夹时,我正在创建新的flowPane 所以包
-
cma缓冲区内存分配失败
我正在尝试为DMA Linux编写驱动程序,但我的驱动程序一直无法执行DMA_CONCENTER_alloc,我已经增加了CMA内存和CONCENTERY_pool。。。 我错过了什么? dmesg在物理CPU 0x0上引导Linux<br>Linux版本4.14.0-xilinx-v2018.2(oe-user@oe-host)(gcc版本7.2.0(gcc))#5 SMP抢占Sun二月17日2
-
IntelliJ中的Grails默认内存设置
谁能给我这个VM配置的位置(上面突出显示),我可以编辑,特别是PermSize和maxpermsize? 更新:注意:a)将它添加到运行目标窗口的VM选项中不会修改它。b)将它添加到IntelliJ executeable(IDEA64.exe.vmOptions)的VM选项中也不会工作。
-
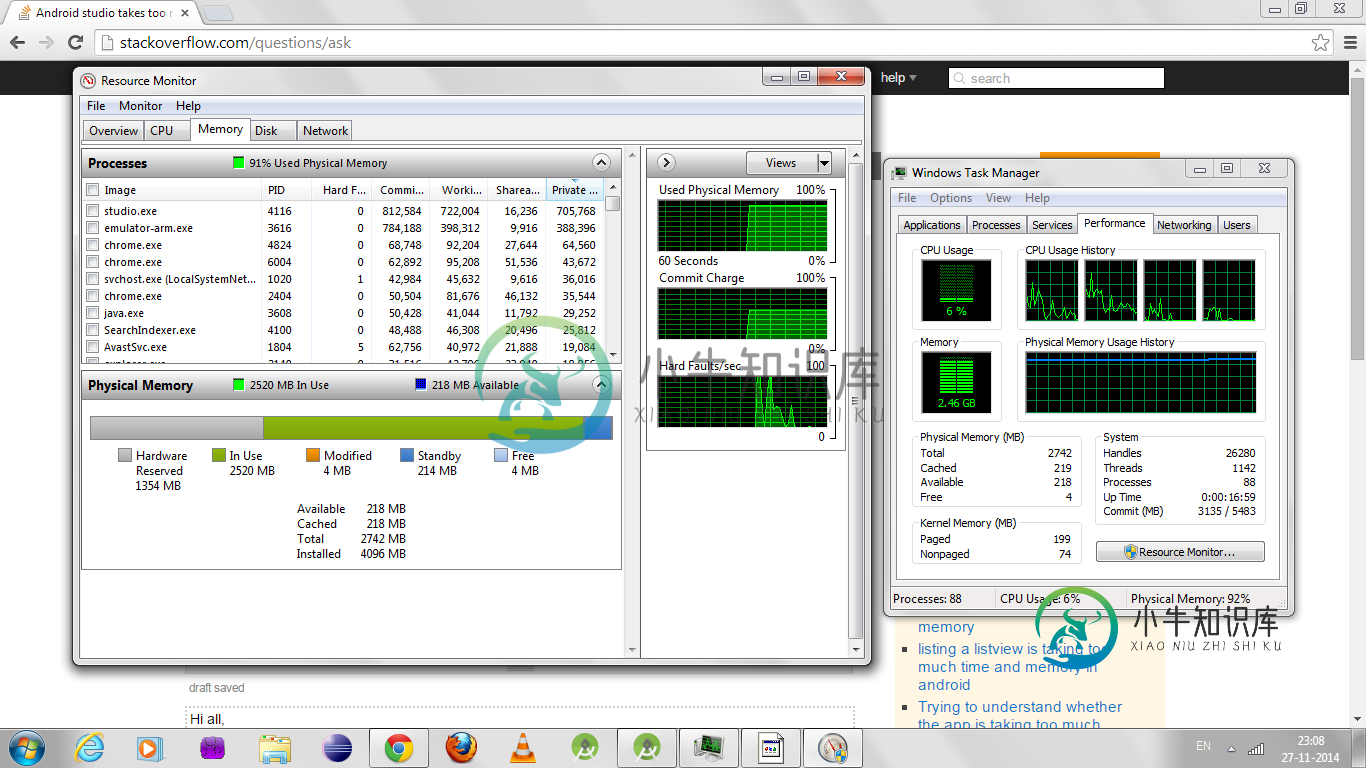 Android工作室占用太多内存
Android工作室占用太多内存