《搜狐面经》专题
-
ElasticSearch阻止html标签可搜索
问题内容: 我有一个由其他应用程序标记的文本。我不希望查询这些标签时返回查询。 我尝试使用html_strip,但仍可以搜索这些标签。 标签的示例可能有所不同,但与相似。我也尝试过,在两个结果中,我都可以搜索 span 或 PERSON 并获得结果,而这些词不会出现在其他任何地方。 我究竟做错了什么? 索引映射: 询问 响应: 问题答案: 你这里有几个问题。首先,应该是,并且在声明映射时丢失了类型
-
MySQL搜索逗号列表[重复]
问题内容: 这个问题已经在这里有了答案 : MySQL查询以逗号分隔的字符串查找值 (11个答案) 2年前关闭。 我有一个MySQL字段,该字段引用另一个表,其中id保存为逗号分隔列表,例如: 代表另一个表中的值。我知道这是很不好的做法,但是错了,但这来自上面,我对此无能为力。现在的问题是,我想使用以下查询在该字段中进行搜索: 现在的问题显然是在此示例查询中几乎可以找到所有条目,因为最常见的ID在
-
部分匹配的GAE搜索API
问题内容: 使用GAE搜索API是否可以搜索部分匹配项? 我正在尝试创建自动完成功能,其中该术语将是部分单词。例如。 b bui 构建 都将返回“建筑物”。 GAE怎么可能? 问题答案: 尽管全文搜索不支持LIKE语句(部分匹配),但是您可以修改它。 首先,为所有可能的子字符串标记数据字符串(hello = h,he,hel,lo等) 使用标记化的字符串构建索引+文档(搜索API) 执行搜索,然后
-
使用InnoDB进行全文搜索
问题内容: 我正在开发一个高容量的Web应用程序,其中的一部分是讨论帖子的MySQL数据库,该数据库需要平稳地增长到2000万+行。 我本来打算对表使用MyISAM(用于内置的全文本搜索功能),但是由于单个写入操作而使 整个表 被锁定的想法使我陷入困境。行级锁具有更大的意义(更不用说InnoDB在处理大型表时的其他速度优势)。因此,基于这个原因,我决心使用InnoDB。 问题是… InnoDB没有
-
在MySQL中搜索“全字匹配”
问题内容: 我想编写一个SQL查询,该查询在文本字段中搜索关键字,但是仅当它是“全字匹配”时(例如,当我搜索“ rid”时,它不应该与“ arid”匹配,但是应该匹配“摆脱”。 我正在使用MySQL。 幸运的是,在该应用程序中性能并不是至关重要的,并且数据库大小和字符串大小都非常小,但是我更喜欢在SQL中而不是在PHP中驱动它。 问题答案: 您可以使用和和字边界标记: 2020年更新:(实际上是2
-
Spring搜索中的存储字段
问题内容: 在文档中,某些类型(例如数字和日期)指定存储默认为no。但是该字段仍然可以从json中检索。 令人困惑。这是否表示_source? 有没有办法根本不存储字段,而只是对其建立索引并进行搜索? 问题答案: 默认情况下,不存储任何字段类型。只有领域。这意味着您始终可以取回发送给搜索引擎的内容。即使您要求特定的字段,elasticsearch也会为您解析该字段并将其退还给您。 您可以根据需要禁
-
python中的模糊文本搜索
问题内容: 我想知道是否有任何Python库可以进行模糊文本搜索。例如: 我有三个关键字 “ letter” , “ stamp” 和 “ mail” 。 我想要一个功能来检查这三个词是否在同一段落(或一定距离,一页)内。 另外,这些词必须保持相同的顺序。在这三个词之间出现其他词也很好。 我已经尝试过解决不了我的问题。另一个库看起来很强大,但是我找不到合适的功能… 问题答案: {1} 您可以在中执
-
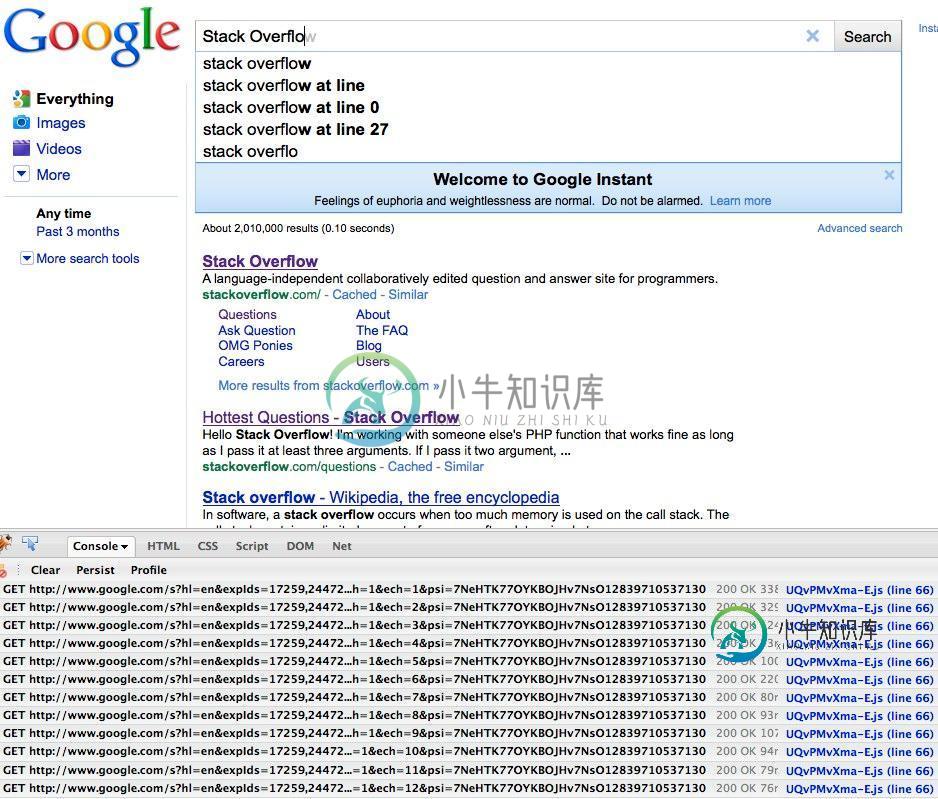 Google即搜即得如何工作?
Google即搜即得如何工作?问题内容: 关于新的Google即时搜索的工作原理有什么想法?似乎只是AJAX对旧搜索的调用,但是要简化这么多Google很难。有人猜测吗? 编辑:我知道每次按键都发送AJAX,但这是可预测的吗?还是您认为这只是常规的Google搜索? 问题答案: 更新: Google刚刚在幕后发布了一篇名为Google Instant 的博客文章。这是一个有趣的读物,并且显然与此问题有关。例如,您可以阅读他们如
-
不区分大小写的搜索
问题内容: 我正在尝试使用JavaScript中的两个字符串进行不区分大小写的搜索。 通常情况如下: 该标志将不区分大小写。 但是我需要搜索第二个字符串。没有标志,它可以完美地工作: 如果我在上面的示例中添加标志,它将搜索searchstring而不是变量“ searchstring”中的内容(下一个示例不起作用): 我该如何实现? 问题答案: 是的,使用而不是。调用的结果将返回匹配自身的实际字符
-
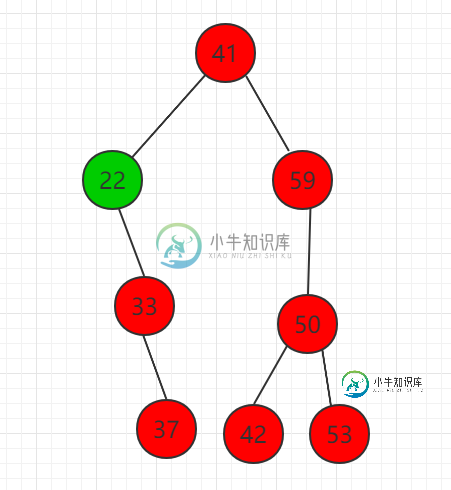 二分搜索树节点删除
二分搜索树节点删除主要内容:src/runoob/binary/BSTRemove.java 文件代码:本小节介绍二分搜索树节点的删除之前,先介绍如何查找最小值和最大值,以及删除最小值和最大值。 以最小值为例(最大值同理): 查找最小 key 值代码逻辑,往左子节点递归查找下去: ... // 返回以node为根的二分搜索树的最小键值所在的节点 private Node minimum (Node node ) { if ( node. left == null ) retu
-
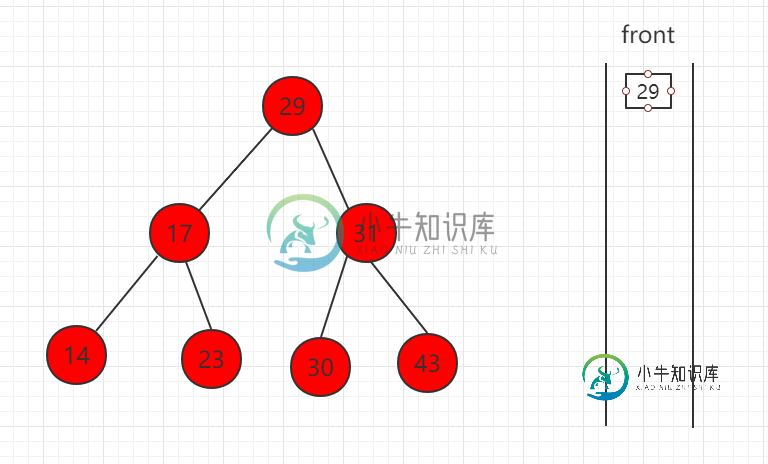 二分搜索树层序遍历
二分搜索树层序遍历主要内容:src/runoob/binary/LevelTraverse.java 文件代码:二分搜索树的层序遍历,即逐层进行遍历,即将每层的节点存在队列当中,然后进行出队(取出节点)和入队(存入下一层的节点)的操作,以此达到遍历的目的。 通过引入一个队列来支撑层序遍历: 如果根节点为空,无可遍历; 如果根节点不为空: 先将根节点入队; 只要队列不为空: 出队队首节点,并遍历; 如果队首节点有左孩子,将左孩子入队; 如果队首节点有右孩子,将右孩子入队; 下面依次演示如下步骤: (1)先取出
-
碎片和副本弹性搜索
假设在创建索引时,我没有为此设置任何副本,如果我使用update settings API进行更新,并且将副本状态更改为1。如果我有2个节点,那么应该在第二个节点上创建副本,因为在主节点侧,由于集群状态显示黄色,碎片没有分配给node2,所以不会创建副本,即使我们将副本启用为1。 请分享为什么副本碎片没有分配到Node2? 但在集群启动时,节点显示它们检测到并相互连接。
-
弹性搜索盘空间计算
如何计算弹性搜索服务器磁盘空间,每天4TB日志需要多少节点。 需要多少磁盘空间存储在弹性搜索索引中? 如何计算节点数? 索引是否压缩? 在LogStash的行格式中存储10G日志需要多少磁盘空间? 索引是否压缩? 如果节点配置为使用5个碎片,则以下是真还是假,以及为什么 存储10G日志需要50G磁盘空间来存储5个分片节点吗?
-
什么是弹性搜索指数?
它们在ES术语表中没有提及。 它们与其他ES实体(碎片/节点/索引)的关系是什么?
-
 如何在VSCode中搜索方法?
如何在VSCode中搜索方法?VSCode中是否有任何与CTRL R类似的功能?