《搜狐面经》专题
-
搜索引擎报告简介
使用指南 - 数据报告 - 来源分析 - 搜索引擎报告简介 【搜索引擎】报告可以让您了解不同搜索引擎给您网站带来的流量情况。根据各搜索引擎给您的网站带来的流量数据,您可以及时了解到哪种搜索引擎能够给您的网站带来更多访客,以及哪种搜索引擎带来的访客更关注您的网站,您可以将更多推广预算分配到能够给您网站带来更多访客且访客关注度更高的搜索引擎;对于带来较少访客或者访客关注度不高的搜索引擎,您可以结合业务
-
练习46:三叉搜索树
我打算向你介绍的最后一种数据结构就是三叉搜索树(TSTree),它和BSTree很像,除了它有三个分支,low、equal和high。它的用法和BStree以及Hashmap基本相同,用于储存键值对的数据,但是它通过键中的独立字符来控制。这使得TSTree具有一些BStree和Hashmap不具备的功能。 TSTree的工作方式是,每个键都是字符串,根据字符串中字符的等性,通过构建或者遍历一棵树来
-
练习40:二叉搜索树
二叉树是最简单的树形数据结构,虽然它在许多语言中被哈希表取代,但仍旧对于一些应用很实用。二叉树的各种变体可用于一些非常实用东西,比如数据库的索引、搜索算法结构、以及图像处理。 我把我的二叉树叫做BSTree,描述它的最佳方法就是它是另一种Hashmap形式的键值对储存容器。它们的差异在于,哈希表为键计算哈希值来寻找位置,而二叉树将键与树中的节点进行对比,之后深入树中找到储存它的最佳位置,基于它与其
-
练习35:排序和搜索
这个练习中我打算涉及到四个排序算法和一个搜索算法。排序算法是快速排序、堆排序、归并排序和基数排序。之后在你完成基数排序之后,我打算想你展示二分搜索。 然而,我是一个懒人,大多数C标准库都实现了堆排序、快速排序和归并排序算法,你可以直接使用它们: #include <lcthw/darray_algos.h> #include <stdlib.h> int DArray_qsort(DArray
-
第十六章 布尔搜索
在本章中,我展示了上一个练习的解决方案。然后,你将编写代码来组合多个搜索结果,并按照它与检索词的相关性进行排序。 16.1 爬虫的答案 首先,我们来解决上一个练习。我提供了一个WikiCrawler的大纲;你的工作是填写crawl。作为一个提醒,这里是WikiCrawler类中的字段: public class WikiCrawler { // keeps track of where w
-
练习 23:三叉搜索树
我们将研究的最后一个数据结构称为三叉搜索树(TSTree),它可以在一组字符串中快速查找字符串。它类似于BSTree,但是它有三个子节点,而不是两个,每个子节点只是一个字符而不是整个字符串。在BSTree中,左子节点和右子节点是树的“小于”和“大于”的分支。在TSTree中,左子节点,中子节点和右子节点是“小于”,“等于”和“大于”的分支。这可以让你选取一个字符串,将其分解成字符,然后遍历TSTr
-
练习 20:二叉搜索树
在本练习中,我将让你将数据结构的中文描述翻译成工作代码。你已经知道如何使用“大师复制”方法,分析算法或数据结构的代码。你还可以了解如何阅读算法的伪代码描述。现在你将结合二者,并学习如何拆分一个相当松散的二进制搜索树的英文描述。 我打算马上开始,并提醒你,当你做这个练习的时候,不要访问维基百科页面。维基百科的二进制搜索树描述拥有可以工作的 Python 代码,因此它会使此练习失败。如果你卡住了,那么
-
搜索关键词广告(SEM)
搜索引擎营销 (SEM)是企业拉新获客常用的市场推广方式之一,SEM专员或负责SEM投放的营销人员在投放搜索引擎广告时,会进行选词/拓词、撰写创意、出价、投放、监控效果等一系列工作。 对关键词、创意的效果进行监控,是SEM营销人员调整和优化营销策略的重要依据。目前,大部分企业的SEM专员主要利用百度、搜狗等搜索广告后台提供的数据报表对投放效果进行监控和评估,主要看的指标是「展现」、「点击」、「花费
-
使用Git Grep进行搜索
用git grep 命令查找Git库里面的某段文字是很方便的. 当然, 你也可以用unix下的'grep'命令进行搜索, 但是'git grep'命令能让你不用签出(checkout)历史文件, 就能查找它们. 例如, 你要看 git.git 这个仓库里每个使用'xmmap'函数的地方, 你可以运行下面的命令: $ git grep xmmap config.c: co
-
搜索用户字幕信息
通过该接口可以根据关键词搜索用户所有视频的字幕信息,音频转写后可用,地址为:http://spark.bokecc.com/api/subtitle/search/user 需要传递以下参数: 参数 说明 userid 用户 id,不可为空 q 查询的关键词,不可为空 num_per_page 返回信息时,每页包含的字幕信息条数 注:允许范围为1~100 page 当前页码 format 返回格式
-
搜索视频字幕信息
通过该接口可以根据关键词搜索单个视频的字幕信息,音频转写后可用,地址为:http://spark.bokecc.com/api/subtitle/search/video 需要传递以下参数: 参数 说明 userid 用户 id,不可为空 videoid 视频 id,不可为空 q 查询的关键词,不可为空 num_per_page 返回信息时,每页包含的字幕信息条数 注:允许范围为1~100 pag
-
 百度搜索前端实习
百度搜索前端实习一面 *. webscoket、socket.io介绍(项目中用到) *. chatgpt、文心一言的服务器端推送方案有了解过吗 *. 移动端web有经验吗 *. css用的多吗; 我: ?; 讲讲css的优先级 *. cookie, 跨域设置cookie *. HTTP缓存介绍, 强缓存和协商缓存各自的缺点 *. 用过哪些打包工具, rollup和webpack对比 *. 性能优化介绍, 在项目
-
搜索附近商店等POI
利用 Google API 实现搜索附近商店、银行、学校等等POI。点击地点的标注(Annotation)会有弹出气泡视图的动画效果。需申请自己的API Key 进行替换使用,详见官方文档:https://developers.google.com/places/documentation/ 。 [Code4App.com]
-
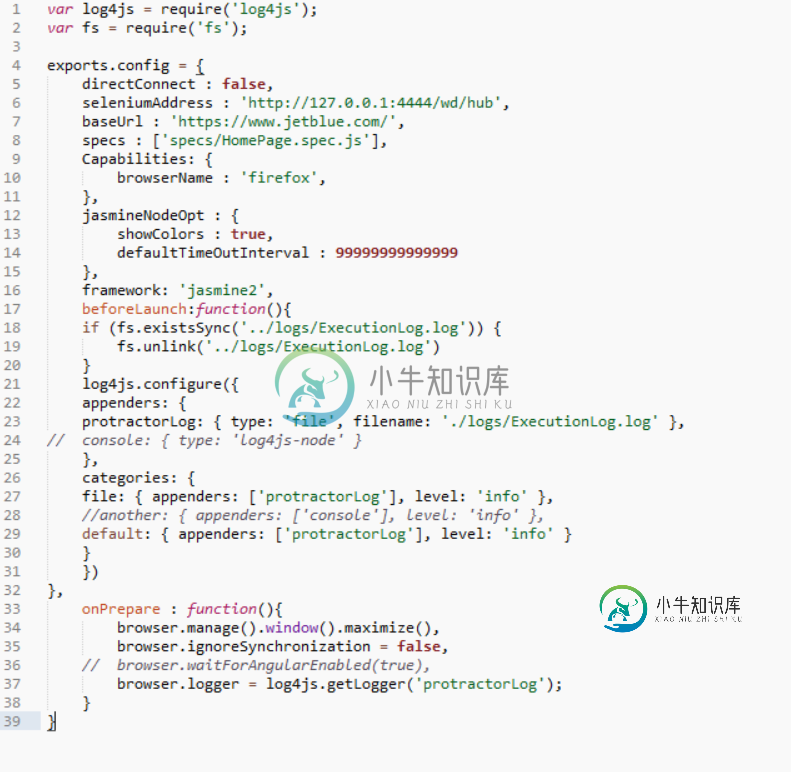 Chrome浏览器打开每次我运行量角器,即使设置火狐浏览器
Chrome浏览器打开每次我运行量角器,即使设置火狐浏览器我在配置文件中将浏览器名设置为firefox。 我启动selenium服务器:webdriver-Manager--gecko start。我有gecko驱动版本0.26.0和火狐版本65。当我运行量角器conf.js时,它仍然会触发Chrome。我尝试运行已弃用的独立服务器。即selenium-独立npm,它仍然会触发Chrome。我还安装了最新的量角器。NodeJS: 10.21.0
-
javascript - JavaScript 强制刷新window.location.reload(true)在火狐浏览器有效,谷歌浏览器无效?
js window.location.reload(true)强制刷新只在火狐浏览器中生效,谷歌浏览不生效 有什么办法可以兼容谷歌、火狐浏览器能在js中调用强制刷新,就像调用ctrl+f5那样 主要是想刷新页面缓存