《OD综合面试》专题
-
latex 百合池
本文向大家介绍latex 百合池,包括了latex 百合池的使用技巧和注意事项,需要的朋友参考一下 示例 可以通过lilypond-book命令将LilyPond注释雕刻机与LaTeX一起使用。首先,我们创建一个LaTeX文档(文件扩展名为.lytex),将我们的音乐嵌入到: 然后,我们创建我们的LilyPond文件(.ly),包括lilypond-book-preamble.ly文件(LilyP
-
Rails Elasticsearch聚合
问题内容: 我似乎无法以某种方式收到包含我的聚合的响应… 使用curl可以按预期工作: 我得到答复: 但是在rails中使用代码: 并在浏览器中呈现 我得到一个空的答复: 如何在这里打印出卷曲的聚集体? 问题答案: 我也在为此而苦苦挣扎,但是现在我发现了如何获得聚合结果。 如果您将 elasticsearch-rails 与 elasticsearch-model gem一起使用,则在 模型上 运
-
休眠合并
问题内容: 我正在测试休眠并将此查询提供给 我在命令行中得到这些查询: 我使用的是“合并不保存”,所以为什么休眠要更新我的对象,所以不应该更新。对吗 怎么了 问题答案: 我将尝试使用一个更具体的示例进行解释。假设您有以下情况: 尝试重新附加分离的对象时发生异常,userA。 为了解决上述问题,使用了merge(),如下所示:
-
Scala Collection(集合)
Scala提供了一套很好的集合实现,提供了一些集合类型的抽象。 Scala 集合分为可变的和不可变的集合。 可变集合可以在适当的地方被更新或扩展。这意味着你可以修改,添加,移除一个集合的元素。 而不可变集合类,相比之下,永远不会改变。不过,你仍然可以模拟添加,移除或更新操作。但是这些操作将在每一种情况下都返回一个新的集合,同时使原来的集合不发生改变。 接下来我们将为大家介绍几种常用集合类型的应用:
-
组合模式
主要内容:介绍,实现,Employee.java,CompositePatternDemo.java组合模式(Composite Pattern),又叫部分整体模式,是用于把一组相似的对象当作一个单一的对象。组合模式依据树形结构来组合对象,用来表示部分以及整体层次。这种类型的设计模式属于结构型模式,它创建了对象组的树形结构。 这种模式创建了一个包含自己对象组的类。该类提供了修改相同对象组的方式。 我们通过下面的实例来演示组合模式的用法。实例演示了一个组织中员工的层次结构。 介绍 意图:将对象组合
-
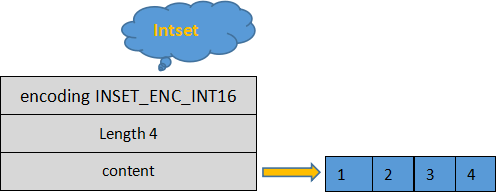 Redis set集合
Redis set集合主要内容:认识set集合,命令汇总,命令演示Redis set (集合)遵循无序排列的规则,集合中的每一个成员(也就是元素,叫法不同而已)都是字符串类型,并且不可重复。Redis set 是通过哈希映射表实现的,所以它的添加、删除、查找操作的时间复杂度为 O(1)。集合中最多可容纳 2^32 - 1 个成员(40 多亿个)。 Redis set 使用以下方式向集合中添加一个成员,语法格式如下: key:指定一个键 member:集合中要存储
-
Python frozenset集合
set 集合是可变序列,程序可以改变序列中的元素;frozenset 集合是不可变序列,程序不能改变序列中的元素。set 集合中所有能改变集合本身的方法,比如 remove()、discard()、add() 等,frozenset 都不支持;set 集合中不改变集合本身的方法,fronzenset 都支持。 我们可以在交互式编程环境中输入 来查看 frozenset 集合支持的方法: >>> d
-
Python set集合
主要内容:Python创建set集合,Python访问set集合元素,Python删除set集合Python 中的集合,和数学中的集合概念一样,用来保存不重复的元素,即集合中的元素都是唯一的,互不相同。 从形式上看,和字典类似,Python 集合会将所有元素放在一对大括号 {} 中,相邻元素之间用“,”分隔,如下所示: {element1,element2,...,elementn} 其中,elementn 表示集合中的元素,个数没有限制。 从内容上看,同一集合中,只能存储不可变的数据类型,
-
Java Map集合
Map 是一种键-值对(key-value)集合,Map 集合中的每一个元素都包含一个键(key)对象和一个值(value)对象。 用于保存具有映射关系的数据。 Map 集合里保存着两组值,一组值用于保存 Map 里的 key,另外一组值用于保存 Map 里的 value, key 和 value 都可以是任何引用类型的数据。Map 的 key 不允许重复,value 可以重复,即同一个 Map
-
Java Set集合
主要内容:HashSet 类,TreeSet 类Set 集合类似于一个罐子,程序可以依次把多个对象“丢进”Set 集合,而 Set 集合通常不能记住元素的添加顺序。也就是说 Set 集合中的对象不按特定的方式排序,只是简单地把对象加入集合。 Set 集合中不能包含重复的对象,并且最多只允许包含一个 null 元素。 Set 实现了 Collection 接口,它主要有两个常用的实现类: HashSet 类和 TreeSet类。 HashSet
-
Java List集合
主要内容:ArrayList 类,LinkedList类,ArrayList 类和 LinkedList 类的区别List 是一个 有序、可重复的集合,集合中每个元素都有其对应的顺序索引。List 集合允许使用重复元素,可以通过索引来访问指定位置的集合元素。List 集合默认按元素的添加顺序设置元素的索引,第一个添加到 List 集合中的元素的索引为 0,第二个为 1,依此类推。 List 实现了 Collection 接口,它主要有两个常用的实现类: ArrayList 类和 LinkedLi
-
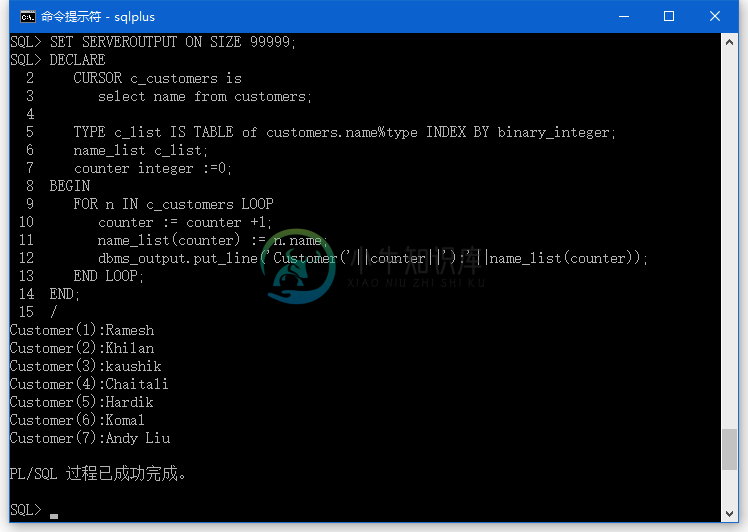 PL/SQL集合
PL/SQL集合主要内容:索引表,示例,嵌套表,集合方法,集合异常在本章中,我们将讨论PL/SQL中的集合。集合是具有相同数据类型的有序元素组。 每个元素都由一个唯一的下标来表示它在集合中的位置。 PL/SQL提供了三种集合类型 - 索引表或关联数组 嵌套的表 可变大小的数组或类型 Oracle的每种类型的集合有以下特征 - 集合类型 元素个数 下标类型 密集或稀疏 在哪创建 是否为对象类型属性 关联数组(或索引表) 无界 字符串或整数 任意一种 只在PL/SQ
-
整合媒体
渲染有吸引力的、易于使用的web表单不仅仅需要HTML -- 同时也需要CSS样式表,并且,如果你打算使用奇妙的web2.0组件,你也需要在每个页面包含一些JavaScript。任何提供的页面都需要CSS和JavaScript的精确配合,它依赖于页面上所使用的组件。 这就是素材定义所导入的位置。Django允许你将一些不同的文件 -- 像样式表和脚本 -- 与需要这些素材的表单和组件相关联。例如,
-
声明合并
TypeScript中有些独特的概念可以在类型层面上描述JavaScript对象的模型。 这其中尤其独特的一个例子是“声明合并”的概念。 理解了这个概念,将有助于操作现有的JavaScript代码。 同时,也会有助于理解更多高级抽象的概念。 对本文件来讲,“声明合并”是指编译器将针对同一个名字的两个独立声明合并为单一声明。 合并后的声明同时拥有原先两个声明的特性。 任何数量的声明都可被合并;不局限
-
Flume 整合 Kafka
一、背景 先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合后的数据输入到 Storm 等分布式计算框架中,可能就会超过集群的处理能力,这时采用 Kafka 就可以起到削峰的作用。Kafka 天生为大数据场景而设计,具有高吞吐的特性,能很好地抗住峰值数据的冲击