《OD综合面试》专题
-
与symfony合作的Mercure不与vue合作
我在vue的Symfony下配置merure时遇到了问题。在. env文件中,我将mercureurls更改为使用超文本传输协议,因为它导致我的证书错误(包括在symfony中)。 . env 当我通过在示例中打开symfony应用程序http://localhost:8000并在控制台中添加此脚本进行测试时: 它正在工作,我可以在其他选项卡中发布一些更改。但当我在位于上的vue应用程序中执行相同
-
Elasticsearch:NEST中具有基数的复合聚合
我使用复合和术语聚合来获得基于给定字段的分组结果。我还使用基数聚合来获取聚合桶的总计数。 下面是我发送的请求查询,以获得相应的响应: 请求: 答复: 我使用Kibana检查查询,它对我来说很好。 但是,我不确定如何在我的NEST对象语法中使用这个基数聚合器。 这是我的代码: 我将非常感谢任何帮助。
-
RxJava将对象与列表合并/合并
我有两个可观测值,一个返回1个元素,另一个返回多个元素。我的目标是在不阻塞的情况下将它们合并在一起,以构建如下对象: 我试过压缩、合并和合并,但似乎都不是解决方案。
-
双向合并排序和合并排序
双向合并排序与递归合并排序有何不同? 假设在合并排序中有5个数字需要排序8,9,1,6,4,我们按如下步骤1进行划分:{8,9,1}{6,4} 步骤2:{8,9}{1}{6}{4} 步骤3:{8}{9}{1}{6}{4} 现在合并 步骤4:{8,9}{1}{4,6} 步骤5:{1,8,9}{4,6} 第六步:{1,4,6,8,9} 但在双向合并排序中,我们将数组分为两个元素(但根据维基百科,在合并
-
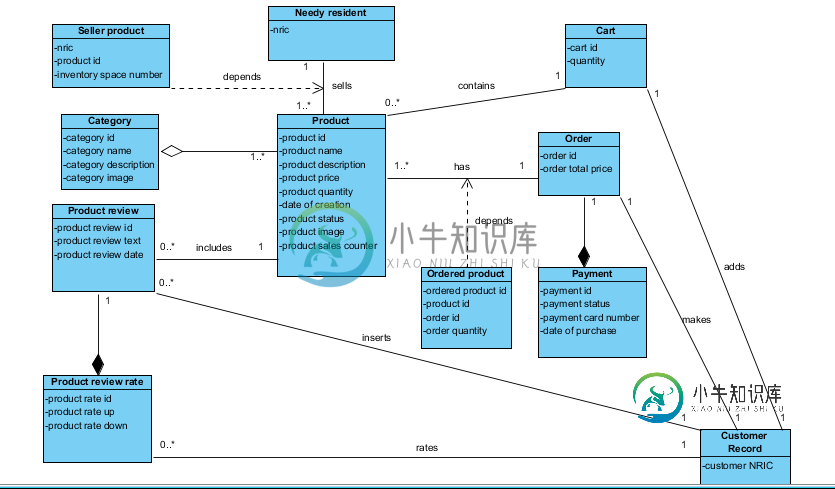 UML图中的关联、聚合和合成
UML图中的关联、聚合和合成因此,我对UML图中的关联、聚合和组合有一些疑问。以下是一些场景: > 产品评审对产品评审的评级组成。这意味着对于每一个产品评审等级必须有产品评审?如果产品评审不存在,评审评级就没有意义。 客户NRIC协助推车和订货。我们不能使用聚合,因为如果客户不存在,购物车和订单也不存在。 有人能帮我检查一下我的关系是否正确吗?因为我对聚合和关联有点困惑,所以用关联来链接所有的表是好的吗。我不知道什么时候该用
-
不同类型集合的集合重载
我知道重载是在编译时决定的,但当我试图运行下面的示例时,它给出了我无法理解的结果 当我每次运行这个代码片段时,我都会得到“Collection”的输出,这意味着调用参数为Collection的classify方法。 请解释
-
在C++中用`{}`聚合初始化联合
-
有序集合操作 - 评分的聚合
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX] 例如: 127.0.0.1:6379> zrangebyscore votes -inf inf withscores 1) "sina" 2) "1" 3) "google" 4) "5" 5) "baidu" 6) "10
-
集合操作 - 集合间移动元素
smove srckey dstkey member 从srckey对应set中移除member并添加到dstkey对应set中,整个操作是原子的。成功返回1,如果member在srckey中不存在返回0,如果key不是set类型返回错误
-
模型选择、欠拟合和过拟合
在前几节基于Fashion-MNIST数据集的实验中,我们评价了机器学习模型在训练数据集和测试数据集上的表现。如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不一定更准确。这是为什么呢? 训练误差和泛化误差 在解释上述现象之前,我们需要区分训练误差(training error)和泛化误差(generalization error)。通俗来讲,
-
指向新合同版本的国家仍然试图废除旧合同?
我有一个场景,我已经将我的义务从V1升级到V2,并成功指向正确的V2合约。接下来,我试图对这些升级后的V2国家做一个< code>SettleObligation。当在< code > CollectSignatureFlow 中形成并发送事务时,在我的< code>isGreaterThan方法中发现了一个< code > Java . lang . nosuchmethoderror ,该方法
-
深度测试与α融合
大家都知道立方体的顶点数据经过顶点着色器、光栅、片元着色器等渲染管线单元处理后会得到立方体每个面的片元数据, 每个片元不仅包含RGB像素值,还有透明度分量A,片元的深度值Z,屏幕坐标(X,Y)等数据。 屏幕坐标(X,Y) 屏幕坐标指的是每一个片元的像素值在显示器canvas画布上的显示位置,如果一个网页上有多个canvas画布,或者打开多个包含canvas画布的网页窗口, 每一个引入WebGL的c
-
5.10 测试合约及交易
测试合同和交易 通常,您需要采取低级别策略来测试和调试合约及交易。本节介绍一些可以使用的调试工具和实践。为了在不产生实际影响的情况下测试合约和交易,你最好在一个私人的块上测试它。这可以通过配置备用网络ID(选择唯一的整数)和/或禁用peer来实现。测试时推荐您使用备用数据目录和端口,这使得您甚至不会意外与现场运行的节点冲突(假设使用默认值运行)。使用带有性能分析的VM调试模式开启你的geth,推荐
-
使用符合合并条件的动态行数合并postgresql中的行
我有一个有许多记录的表。它有以下结构: 表(col1、col2、col3、col4、col5、col6): 还有很多很多其他的行。 因此,我想要一张桌子: 表(col1,col2,col3,col4_1,col4_2,col4_3,col5_1,col5_2,col5_3,col6_1,col6_2,col6_3): 换句话说:表中的某些部分具有相同的,但不同的。每个相同的行数在1-3之间变化(事
-
 数梦前端面试一面+二面+hr面
数梦前端面试一面+二面+hr面2022.09.06数梦一面 1. 除了懒加载之外还用了那些性能优化技术 2. 项目中的缓存是由谁决定的? 3. D3.js和ECharts.js的区别? 4. axios是如何做二次封装的 5. 前端是则么打包的? 6. 如何避免css全局污染 7. 输入从URL到页面显示出来 8. SPA SEO解决方案? 反问: 1. 技术栈是什么? react 2022.09.15二面 1. 自我