《创维》专题
-
NumPy创建区间数组
主要内容:1. numpy.arange(),2. numpy.linspace(),3. numpy.logspace所谓区间数组,是指数组元素的取值位于某个范围内,并且数组元素之间可能会呈现某种规律,比如等比数列、递增、递减等。 为了方便科学计算,Python NumPy 支持创建区间数组。 1. numpy.arange() 在 NumPy 中,您可以使用 arange() 来创建给定数值范围的数组,语法格式如下: numpy.arange(start, stop, step, dtype
-
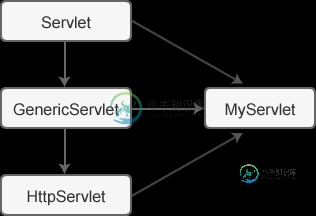 Servlet三种创建方式
Servlet三种创建方式主要内容:Servlet、GenericServlet 、HttpServlet 的关系,Servlet 接口,GenericServlet 抽象类,HttpServlet 抽象类,总结在 Servlet 中,一个动态网页对应一个 Servlet 类,我们可以通过 web.xml 配置文件将 URL 路径和 Servlet 类对应起来。访问一个动态网页的过程,实际上是将对应的 Servlet 类加载、实例化并调用相关方法的过程;网页上显示的内容,就是通过 Servlet 类中的某些方法向浏览器输
-
MySQL创建存储过程
MySQL 存储过程是一些 SQL 语句的集合,比如有时候我们可能需要一大串的 SQL 语句,或者说在编写 SQL 语句的过程中需要设置一些变量的值,这个时候我们就完全有必要编写一个存储过程。 编写存储过程并不是件简单的事情,但是使用存储过程可以简化操作,且减少冗余的操作步骤,同时,还可以减少操作过程中的失误,提高效率,因此应该尽可能的学会使用存储过程。 下面主要介绍如何创建存储过程。 可以使用
-
Python创建包,导入包
主要内容:Python包的导入《Python包》一节中已经提到,包其实就是文件夹,更确切的说,是一个包含“__init__.py”文件的文件夹。因此,如果我们想手动创建一个包,只需进行以下 2 步操作: 新建一个文件夹,文件夹的名称就是新建包的包名; 在该文件夹中,创建一个 __init__.py 文件(前后各有 2 个下划线‘_’),该文件中可以不编写任何代码。当然,也可以编写一些 Python 初始化代码,则当有其它程序文
-
Python type()动态创建类
我们知道,type() 函数属于 Python 内置函数,通常用来查看某个变量的具体类型。其实,type() 函数还有一个更高级的用法,即创建一个自定义类型(也就是创建一个类)。 type() 函数的语法格式有 2 种,分别如下: type(obj) type(name, bases, dict) 以上这 2 种语法格式,各参数的含义及功能分别是: 第一种语法格式用来查看某个变量(类对象)的具体
-
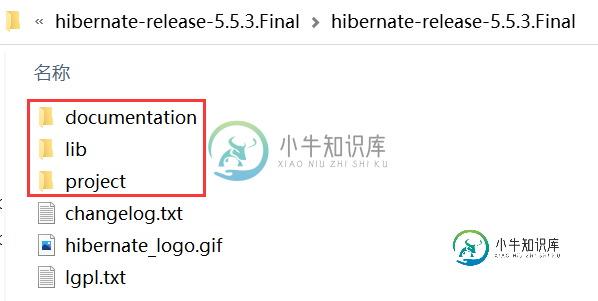 Hibernate项目创建流程
Hibernate项目创建流程主要内容:1. 下载 Hibernate 开发包,2. 新建工程,3. 创建数据库表,4. 创建实体类,5. 创建映射文件,6. 创建 Hibernate 核心配置文件,7. 测试本节我们将演示如何搭建一个 Hibernate 工程。 搭建 Hibernate 工程需要以下 7 步: 下载 Hibernate 开发包 新建工程 创建数据库表 创建实体类 创建映射文件 创建 Hibernate 核心配置文件 测试 1. 下载 Hibernate 开发包 浏览器访问 Hibernate 官网 下载
-
c聚合关系创建
我有以下代码: 在Bouml中,我从这段代码中生成了类图: 图表 我认为 A 和 F 之间的 (https://softwareengineering.stackexchange.com/questions/255973/c-association-aggregation-and-composition) 关系必须产生聚合关系,但它产生了关联关系。如何建立聚合关系?
-
从Dataframe comumn创建数组
我从Python开始。我想创建一个新的数组,它将包含从数据帧中的一个列存储的所有单词。 此列已包含带有单词的数组: 这里有一个例子: 输出: ['p','open','terminal‘,'application','gt','utility','gt','terminal’,'type','p','pre','code','locate','insertfonthere‘,'br','code'
-
尝试创建web服务
我创建了一个将被转换为web服务方法,该方法如下所示: 当我部署和测试此web服务时,我得到以下错误: WS00041:服务调用引发异常,消息为:NULL;有关更多详细信息,请参阅服务器日志异常详细信息:java.lang.reflect.invocationtargetexception javax.servlet.servletexception:java.lang.reflect.invoc
-
Azure Blob到AzureSQL表创建
我正在努力改变信仰 以下是来自Microsoft的参考:https://azure.microsoft.com/en-us/updates/preview-loading-files-from-azure-blob-storage-into-sql-database/ 我的CSV数据看起来像是100,“37415B4EAF943043E1111111A05370E”,“ONT”,“000”,“S”
-
创建hashmapfrom List提供java.lang.ClassCastException
下面是我的代码。任何帮助都很感激。我根本无法阅读列表和创建地图。我将作为函数参数传递到Rest层。在我的服务层中,我需要使用存储在列表中的映射值。 我的列表有前面提到的值 ClassCastException:java.lang.String不能强制转换为java.util.Map
-
创建空数据.框架
我正在尝试初始化一个没有任何行的Data.Frame。基本上,我希望为每个列指定数据类型并命名它们,但不因此创建任何行。 到目前为止,我所能做的最好的事情是: 它创建了一个data.Frame,其中有一行包含我想要的所有数据类型和列名,但也创建了一个需要删除的无用行。 有没有更好的办法做到这一点?
-
Spring Kafka-动态创建流
我需要从配置文件动态创建kafka流,其中包含每个流的源主题名称和配置。应用程序需要有几十个Kafka流和流将是不同的每个环境(例如阶段,prod)。它可能做到这一点与库? 我们可以通过轻松做到这一点: 我们需要实现spring接口,这样所有流都将自动启动和关闭。 是否可以使用做同样的事情?正如我所看到的,我们需要在代码中创建每个Kafka流,我看不到如何使用创建Kafka流列表的可能性。 但是如
-
GraphQLSchema bean未创建-Spring Boot
我在这里遵循这个例子:-http://www.baeldung.com/spring-graphql 对我来说,GraphQL架构bean没有被自动注册。它抛给我这个错误:-没有合格的bean类型'graphql.schema.GraphQL架构'可用 我的Pom文件具有所有需要的Spring Boot依赖项:- 我在应用程序中有以下设置。属性:- 不确定我错过了什么,我是否需要在此页面上明确定义
-
Spring batch尝试创建表