《同花顺2023春招交流讨论》专题
-
如何在Spark Kafka直接流中手动提交偏移?
-
Python字典:keys()和values()是否总是相同的顺序?
问题内容: 看起来字典的和方法返回的列表始终是一对一映射(假设在调用这两种方法之间字典没有改变)。 例如: 如果你没有在调用keys()和调用之间更改字典values(),那么假设上述for循环将始终显示True是否错误?我找不到任何证明文件。 问题答案: 发现了这一点: 如果,, ,和 被称为中间没有修改的字典,列表会直接对应。 在2.x文档和3.x文档上。
-
Python-如何保持keys/values与声明的顺序相同?
问题内容: 我有一本按照特定顺序声明的字典,并希望一直保持该顺序。实际上不能根据它们的值按顺序保留,我只希望按声明的顺序保留。 因此,如果我有字典: 如果我查看它或遍历它,则不是按此顺序进行的,有什么方法可以确保Python保持我声明键/值的显式顺序? 问题答案: 从Python 3.6开始,标准类型默认会保留插入顺序。 定义 将产生字典,字典中的键按源代码中列出的顺序排列。 这是通过对稀疏哈希表
-
不同的顺序通过在一个雄辩的查询
我在表格的列中有。状态为,,,,。我还有一个字段。我想根据日期对,,进行排序,它们将首先排序,但将基于日期和之后的状态,并且始终在最后。 我已经做了什么 但这将导致状态的优先级,所以它将首先按状态排序,然后按日期排序。 我想要的输出 原始mysql查询或雄辩的查询都可以。谢谢
-
同步或顺序提取服务辅助程序[重复]
我需要发送一系列的PUT 要求: 给定请求方法、url和JSON正文,发送请求 如果成功(
-
在Elasticsearch中搜索结果的顺序每次都不同
查询:{“explain”:true,“size”:500,“Query”:{“query_string”:{“query_string”:{“query_string”:“((names.name:(BANK AMERICA\\)”)^50或(names.name:(BANK AMERICA\))^30或(name_pair:\“BANK AMERICA\\\)^30或(name_name:(B
-
在流上使用Collections.toMap()时,如何保持List的迭代顺序?
问题内容: 我创建一个从如下: 我想保持与中相同的迭代顺序。如何使用该方法创建一个? 问题答案: 在2个参数的版本采用的是: 要使用4参数版本,您可以替换: 与: 为了使它更简洁,请编写一个新方法并使用该方法:
-
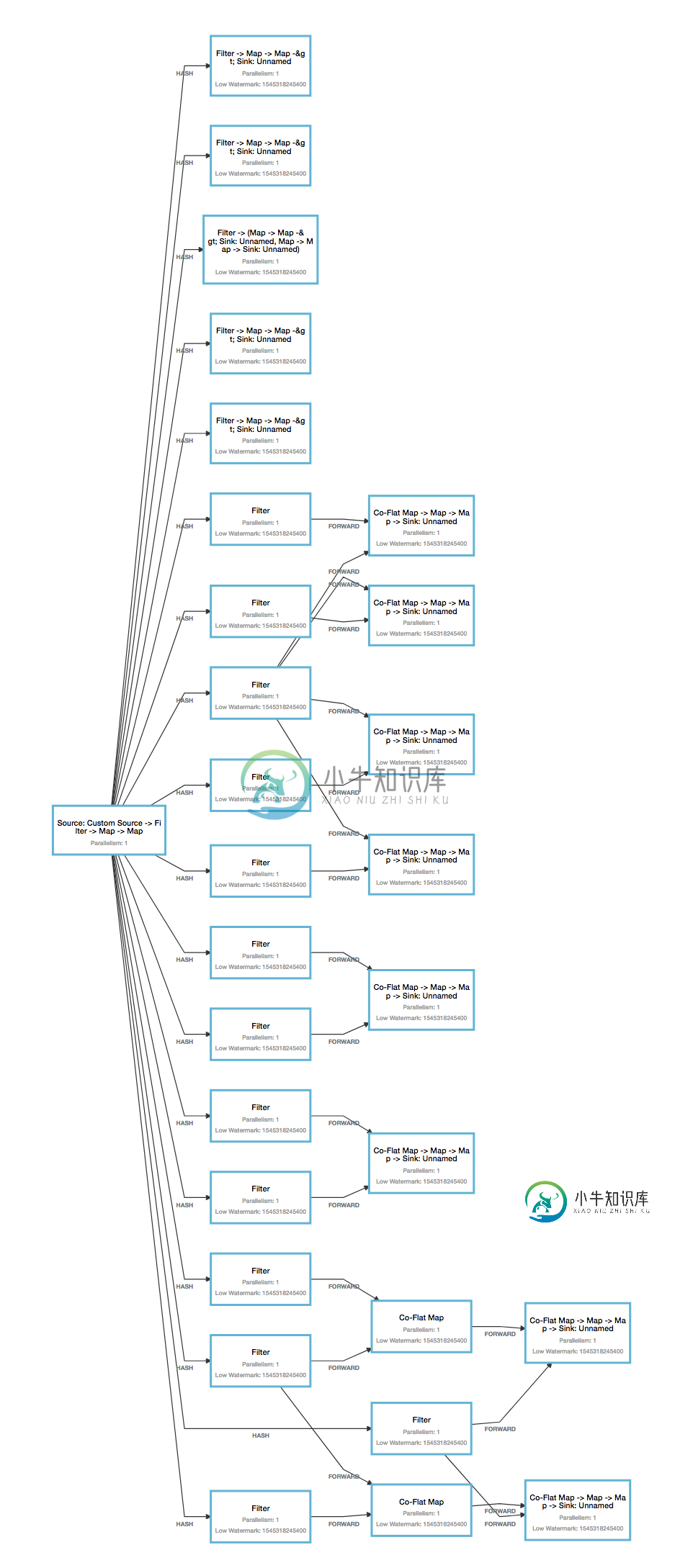 Apache Flink:使用keyby/connect维护流中的消息输入顺序
Apache Flink:使用keyby/connect维护流中的消息输入顺序我正在使用apache flink构建一个相当复杂的数据流网络。其思想是,用Flink实现一个规则引擎。 作为应用程序的基本描述,它应该是这样工作的: 数据由kafka消费者源接收,并用多个数据流处理,直到最终发送到kafka生产者接收器。传入的数据包含具有逻辑键(“object-id”)的对象,传入的消息可能引用相同的object-id。对于每个给定的object-id,必须在整个应用程序中保留
-
如何使用Speedment[duplicate]按相反顺序对流进行排序
我有一个数据库表,我想对其进行筛选,然后按相反(降序)顺序进行排序。我如何在类似于以下内容的速度流中表达: 我希望我的SQL查询能够通过速度优化,因此我不能使用匿名lambda。
-
收集器的合并器功能可以用于顺序流吗?
示例程序: 所以,为了简化这里的问题,没有最终的转换,所以得到的代码非常简单。
-
难道不能保证从列表派生的并行流总是像其顺序对应的流一样提供相同的、可预测的输出吗?
以下代码打印100次true: 当然,100次并不能保证。但是,即使这里使用的标识不符合文档中的“......对于所有u,combiner.apply(标识,u)等于u”的要求,我们仍然可以说从列表或任何其他固有有序结构派生的并行流的行为就像减少()中的顺序流一样返回相同的输出吗?
-
 知乎春招补录|Web前端开发工程师|一面二面三面(已oc)
知乎春招补录|Web前端开发工程师|一面二面三面(已oc)事后回忆的,好多常见的八股问题忘了。三个面试官都问的很仔细,问的比较基础,但会根据我的回答进行探讨,不是单纯的问八股。并且每轮面完1-2个工作日都都有回应,不养鱼,面试体验感拉满。 一面 (一小时) 一面问了好多八股,只记得这些了。 -react子组件给父组件传值 -useimprerativeHandle -http1.0/1.1/2区别 -http2多路复用原理,双方深入讨论了一下。 -htt
-
 滴滴出行春招补录|Web前端开发工程师|一面二面(已挂)
滴滴出行春招补录|Web前端开发工程师|一面二面(已挂)国际化部门下的出行,负责国外打车。 # 一面 (一小时) 一个漂亮姐姐面的,挺温柔的。 实习干了什么 常规的八股.. 手写:promise.all 手写:promise按顺序请求,第一个状态改变了再去请求第二个 面试官评价:写的挺快,基础可以。 # 二面 (一小时) 一个短头发的女面试官,看上去像大leader,面试过程中一直在撩她的头发额.. -实习干了什么,你leader是xxx吗 -那项目里
-
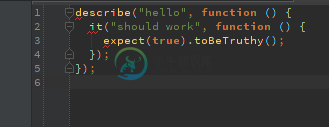 WebStorm茉莉花集成-JSHint无法识别茉莉花
WebStorm茉莉花集成-JSHint无法识别茉莉花我使用文件在 Webstorm 8.0.4 中设置了茉莉花集成 这与语法突出显示的工作方式一样,我可以跳转到声明,文档显示正确。所以连接看起来很好。然而,JSHint仍然为每个关键字抱怨它没有被定义,例如 另请参见以下屏幕截图。正如您所看到的,语法突出显示很好,但我仍然收到一个错误。
-
火花SQL:为什么火花不一直做广播
我在aws s3和emr上使用Spark 2.4进行项目,我有一个左连接,有两个巨大的数据部分。火花执行不稳定,它经常因内存问题而失败。 集群有10台m3.2xlarge类型的机器,每台机器有16个vCore、30 GiB内存、160个SSD GB存储。 我有这样的配置: 左侧连接发生在 150GB 的左侧和大约 30GB 的右侧之间,因此有很多随机播放。我的解决方案是将右侧切得足够小,例如 1G