
Apache Flink:使用keyby/connect维护流中的消息输入顺序

我正在使用apache flink构建一个相当复杂的数据流网络。其思想是,用Flink实现一个规则引擎。
作为应用程序的基本描述,它应该是这样工作的:
数据由kafka消费者源接收,并用多个数据流处理,直到最终发送到kafka生产者接收器。传入的数据包含具有逻辑键(“object-id”)的对象,传入的消息可能引用相同的object-id。对于每个给定的object-id,必须在整个应用程序中保留其传入消息的顺序。整个消息的顺序可以是任意的。
-
null
这将导致n个加入的流,其中n对应于规则的数量。加入的流将有一个map函数附加到它们,它标记消息,这样我们就知道匹配了一个规则。
每个连接的/result流可以独立于其他结果向kafka生产者发布其结果(“Rule xyz Matched”),因此在这一点上,我可以将接收器附加到流。
因为两个流(“condition”-子流)的.connect必须只传递一条消息,如果它在两个流上都收到了(^=两个条件都匹配),所以我需要一个带有键控状态的RichCoflatMapFunction,它可以处理“仅当它在另一端已经收到时才传递”。
然而,问题是,流是由object-id键控的。那么,如果同一个对象的两条消息通过网络运行并到达.connect().map(新RichCoflatMapFunction...)会发生什么呢?这将导致错误的输出。在进入网络时,我需要为每条传入消息分配一个唯一的ID(UUID),因此我可以在.connect().map()..联接中使用这个键(而不是object-id)。但同时,我需要通过object-id对流进行键控,以便按顺序处理相同对象的消息。怎么办?
为了解决这个问题,我使用keyby(_.objectid)保留了输入流,但是stream-join中的RichCoflatMapFunction不再使用keyed-state。相反,我使用了一个简单的运算符状态,它保持传递对象的映射,但实现了相同的逻辑,只是使用手动键/值查找。
这似乎是有效的,但我不知道这是否引入了更多的问题。
flink GUI将呈现此图像,该图像包含14条规则,共23个条件(有些规则只有一个条件):
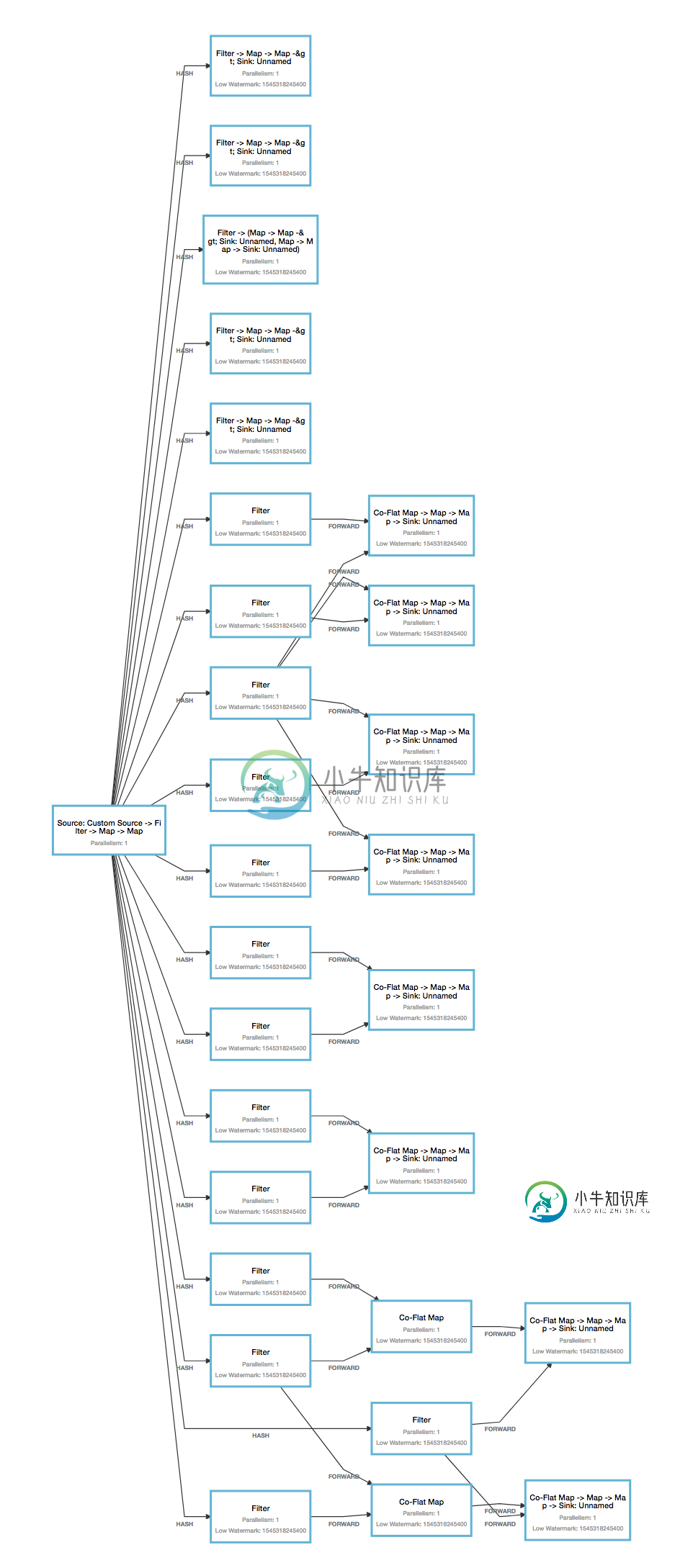
网络的创建是使用以下代码实现的:
val streamCache = mutable.Map[Int,DataStream[WorkingMemory]]()
val outputNodesCache = ListBuffer[DataStream[WorkingMemory]]()
if (rules.isEmpty)
return
// create partial streams for all conditions (first level)
// cache the sub-stream with the hashcode of its condition as key (for re-use)
for (rule <- rules if rule.checks.nonEmpty ;
cond <- rule.checks if !streamCache.contains(cond.hashCode()))
streamCache += cond.hashCode -> sourceStream.filter(cond.matches _)
// create joined streams for combined conditions (sub-levels)
for (rule <- rules if rule.checks.nonEmpty)
{
val ruleName = rule.ruleID
// for each rule, starting with the rule with the least conditions ...
if (rule.checks.size == 1)
{
// ... create exit node if single-condition rule
// each exit node applies the rule-name to the objects set of matched rules.
outputNodesCache += streamCache(rule.checks.head.hashCode).map(obj => { obj.matchedRule = ListBuffer((ruleName, rule.objectType.mkString(":"), rule.statement)) ; obj })
}
else
{
// ... iterate all conditions, and join nodes into full rule-path (reusing existing intermediate paths)
var sourceStream:DataStream[WorkingMemory] = streamCache(rule.checks.head.hashCode)
var idString = rule.checks.head.idString
for (i <- rule.checks.indices)
{
if (i == rule.checks.size-1)
{
// reached last condition of rule, create exit-node
// each exit node applies the rule-name to the objects set of matched rules.
val rn = ruleName
val objectType = rule.objectType.mkString(":")
val statement = rule.statement
outputNodesCache += sourceStream.map(obj => { obj.matchedRule = ListBuffer((rn, objectType, statement)) ; obj })
}
else
{
// intermediate condition, create normal intermediate node
val there = rule.checks(i+1)
val connectStream = streamCache(there.hashCode)
idString += (":" + there.idString)
// try to re-use existing tree-segments
if (streamCache.contains(idString.hashCode))
sourceStream = streamCache(idString.hashCode)
else
sourceStream = sourceStream.connect(connectStream).flatMap(new StatefulCombineFunction(idString))
}
}
}
}
// connect each output-node to the sink
for (stream <- outputNodesCache)
{
stream.map(wm => RuleEvent.toXml(wm, wm.matchedRule.headOption)).addSink(sink)
}
前一段中使用的StateFulCombineFunction:
class StatefulCombineFunction(id:String) extends RichCoFlatMapFunction[WorkingMemory, WorkingMemory, WorkingMemory] with CheckpointedFunction
{
@transient
private var leftState:ListState[(String, WorkingMemory)] = _
private var rightState:ListState[(String, WorkingMemory)] = _
private var bufferedLeft = ListBuffer[(String, WorkingMemory)]()
private var bufferedRight = ListBuffer[(String, WorkingMemory)]()
override def flatMap1(xmlObject: WorkingMemory, out: Collector[WorkingMemory]): Unit = combine(bufferedLeft, bufferedRight, xmlObject, out, "left")
override def flatMap2(xmlObject: WorkingMemory, out: Collector[WorkingMemory]): Unit = combine(bufferedRight, bufferedLeft, xmlObject, out, "right")
def combine(leftState: ListBuffer[(String, WorkingMemory)], rightState: ListBuffer[(String, WorkingMemory)], xmlObject:WorkingMemory, out: Collector[WorkingMemory], side:String): Unit =
{
val otherIdx:Int = leftState.indexWhere(_._1 == xmlObject.uuid)
if (otherIdx > -1)
{
out.collect(leftState(otherIdx)._2)
leftState.remove(otherIdx)
}
else
{
rightState += ((xmlObject.uuid, xmlObject))
}
}
override def initializeState(context:FunctionInitializationContext): Unit = ???
override def snapshotState(context:FunctionSnapshotContext):Unit = ???
}
我不知道在代码的哪一点上顺序被弄乱了,也不知道这些操作是如何分布在线程之间的,所以我不知道如何解决这个问题。
共有1个答案

一些评论...
- 我假设您已经检查了Flink的CEP支持,特别是处理事件时间的延迟。关键的概念是,您可以依赖事件时间(而不是处理时间)来帮助对事件进行排序,但您始终必须确定您愿意容忍的最大迟到量(迟到可能由源和工作流中发生的任何处理引起)。
- 从您提供的Flink作业图来看,您似乎正在通过哈希对传入数据进行分区,但每个规则都需要获取每个传入数据,对吗?因此在这种情况下,您需要广播。
-
我有一个异步执行的查询的输入流。我想确保当我使用时,这些要求的结果将按照输入查询流的顺序收集。 这是我的代码的样子: SQLQueryEngine。执行(查询);返回
-
从示例中,我看到了下面的代码片段,它运行良好。但问题是:我并不总是需要处理输入流并将其生成到接收器。 如果我有一个应用程序,根据某些事件,我必须只发布到kafka主题,以便下游应用程序可以做出某些决定。这意味着,我实际上没有输入流,但我只知道当我的应用程序中发生某些事情时,我需要向kafka的特定主题发布消息。也就是说,我只需要一个接收器。 我查看了示例,但没有找到符合我要求的任何内容。有没有一种
-
当使用Kafka Connect IBM MQ Source Connector使用5个任务的并行级别从IMB MQ读取时,是否可以保留消息顺序(将具有相同键的消息分配给相同的分区)?
-
假设我有一个工作流,在
-
问题内容: 我正在使用JSONObject来删除JSON字符串中不需要的certin属性: 它可以正常工作,但是问题是JSONObject是“名称/值对的无序集合”,我想保持String在通过JSONObject操作之前的原始顺序。 任何想法如何做到这一点? 问题答案: 你不能 这就是为什么我们称其 为名称/值对的无序集合 。 我不确定为什么需要这样做。但是,如果要订购,则必须使用json数组。
-
我有一个业务需求,在积极主动的网站维护消息,我正计划使用Kafka为相同的。生产者将消息放入JMS/MQ,这些消息将由Kafka消费。那么当PRODUER在MQ/JMS中放置100万条消息的批处理消息时,是否可以在地理分布的主动-主动kafka集群中保持消息的顺序呢? (假设每个主题有一个分区和一个使用者) 提前致谢