《同花顺2023春招交流讨论》专题
-
使用Flink同步处理2个流
我有两个流A和B。 我开始同时吃A和B。 流A仅在每分钟的第59秒获得记录。 流B在每分钟的任何一秒都有记录。 我希望处理使两个流同步。 示例:在10:01:59之后从流A中,我将在10:02:59收到一条记录,直到10:02:59,我也不想从流B中读取任何内容。 这可以在Flink中实现吗?
-
按相同元素分组的Java流
我有一个单词流,我想根据相同元素的出现对它们进行排序。 例如:{hello,world,hello} 至 你好,{你好,你好} 谢谢你
-
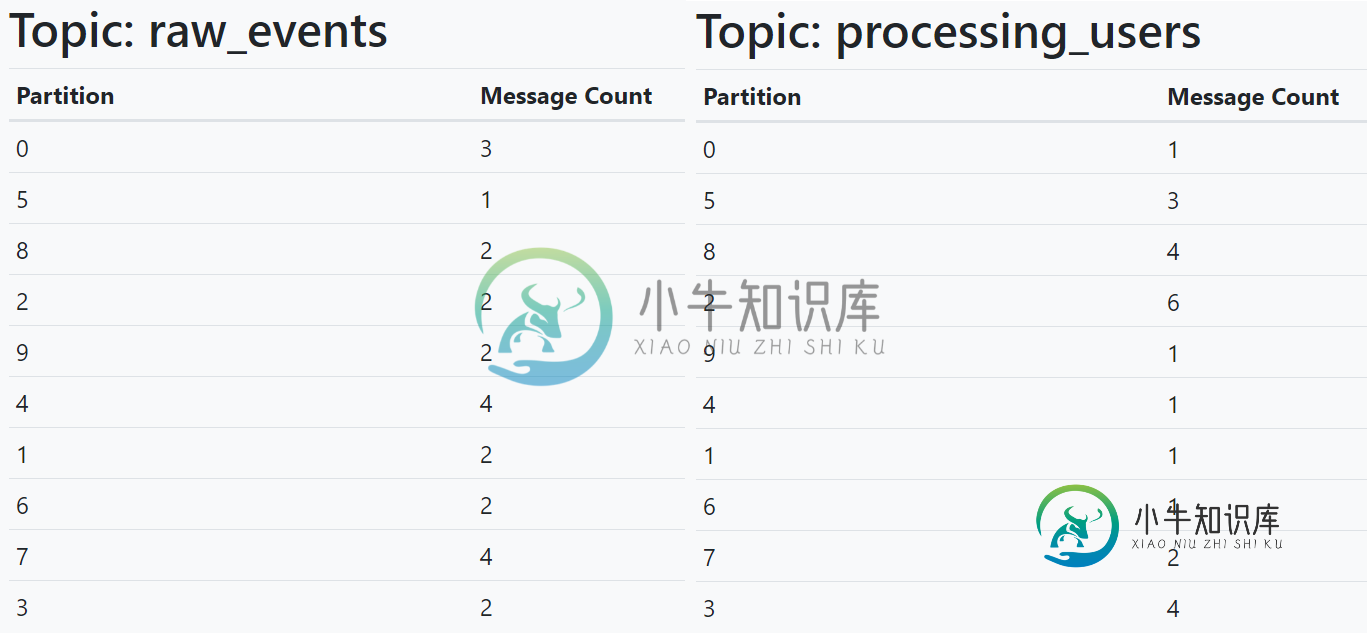 同键主题未能加入Kafka流
同键主题未能加入Kafka流我最近在一个streams应用程序中遇到了一个以前没有遇到过的问题,它很难跟踪与键控/连接相关的问题(以及更新后的分区问题)。 我有两个主题(raw_events和processed_users),这两个主题的密钥相同,但是当我试图对这两个主题执行连接时,尽管密钥相同,但只有一些连接是成功的。 为简洁起见,应用程序的基本工作流程如下: null 问题本身是在步骤5中产生的。由于主题和主题之间的连接
-
 字节跳动2023秋招研发第五场笔试【后端方向】题解
字节跳动2023秋招研发第五场笔试【后端方向】题解没想到9月底了我还在做字节笔试…… T1 拓扑排序就可以了。构造完图,找到入度为0的就是第一代,题目数据保证了第一代只有一个。 T2 其实就是找一个长度为k+1的子数组,数组中每一项*2都大于它的前一项。 只需要记录满足a[i]2>a[i-1]的连续次数,只要这个次数>k,说明可以组成一项。如果发现某一个位置a[i]2<a[i-1],那么要重新开始计数。因为要求是子数组,那么只要这个位置不满足,任
-
 字节跳动2023秋招研发第五场笔试【后端方向】凉经
字节跳动2023秋招研发第五场笔试【后端方向】凉经题型:4道编程题 ,通过率20%,ac,20%,18.18% 1.根据子族谱,第一行是子族谱的个数,然后是n行子族谱,如A B C,代表B是C的父亲,A是B的父亲,要求输出第一代的名字和第n代的人数,不会,寄了 2.要求输出数组中满足要求的字串数, 如an < 2an+1 < 4an+2,用暴力解法做的 3.求各组满足要求的最小步数,每个相邻的步数的值相差+-1或者0,第一步和最后一步的步长必须是
-
 2023届秋招正式批-深信服-前端开发(深圳)二面-凉经
2023届秋招正式批-深信服-前端开发(深圳)二面-凉经笔者非科班出身 1. 前言 关于深信服的一面,请参考我之前的文章 深信服前端一面。 一面结束后的当天下午就收到了二面通知,二面持续约一小时。 2. 内容 (1)自我介绍。 (2)为什么选择前端这一行业呢? (3)聊了些简历里的项目内容:做练手的项目有什么收获?有没有遇到什么意想不到的问题?…… (4)一道编程题:给定一个树结构(不是二叉树)类型的数组,其中的每个元素是一个对象,每个对象有 id、n
-
为什么在Java 8中按顺序收集并行流
问题内容: 为什么总是以随机顺序打印数字,而始终从原始顺序收集元素,即使是从并行流中呢? 输出: 问题答案: 这里有两种不同的“排序”,使讨论变得混乱。 一种是 遇到顺序 ,该 顺序 在流文档中定义。考虑这一点的一种好方法是源集合中元素的 空间 顺序或 从左到右的 顺序。如果源是,请考虑将较早的元素放在较后的元素的左侧。 还有文档中未定义的 处理 或 时间 顺序,但这是由不同线程处理元素的时间顺序
-
流星订阅不会更新集合的排序顺序
问题内容: 当我做… 邮政文档被添加并显示在列表的末尾,与我的发布功能中指定的降序相反。关于我在做什么错的任何想法吗? 谢谢! 问题答案: 发布功能确定哪些记录应同步到任何订阅客户端的mini- mongo数据库。因此,使用publish函数对数据进行排序实际上对客户端没有影响,因为客户端数据库可能会以其他方式存储它们。 当然,您可能希望在发布者的目录中使用sort,以将记录数限制为最近的N条-
-
AWS Lambda是否严格按顺序处理DynamoDB流事件?
我正在编写一个Lambda函数,用于处理DynamoDB流中的项。 我认为Lambda背后的部分观点是,如果我有一个大的事件突发,它将启动足够多的实例来同时通过它们,而不是通过单个实例顺序地提供它们。只要两个事件具有不同的键,我就可以不按顺序处理它们。 然而,我刚刚阅读了关于了解重试行为的这一页,上面说: 对于基于流的事件源(Amazon Kinesis Data Streams和DynamoDB
-
DataFlow/Apache Beam-如何按顺序设计流水线操作?
作为DataFlow/Apache Beam的一部分,我希望先从一个源读取,然后再写入一个源,然后再从一个源读取,然后再按此顺序写入。我如何确保下面R->W->R->W的顺序?我相信下面的运行就像一个r->w的并行管道。我不确定是否使用PDone对象来实现这一点。 (在下面的示例中,考虑BIGQUERYVIEWB是一个由TestDataSet1.Table2和其他几个表组成的大查询视图)
-
如何JUnit测试两个list以相同顺序包含相同元素?
的顺序将与为创建对象选择的顺序相同 允许重复的后续字符串组件并按顺序保留 未定义的行为(其他代码保证没有进入工厂) 在对象实例化之后,没有任何方法可以更改组件列表 我正在编写一个简单的测试,该测试从字符串列表创建并检查它是否可以通过返回相同的列表。我立即这样做,但这应该发生在一个现实的代码路径的远处。 这里是我的尝试: null null
-
Java类在使用sbt进行火花提交Scala时未找到异常
这是我用scala编写的代码 使用sbt包编译时收到的错误是hereimage 这是我的build.sbt档案 名称:=“OV” 规模厌恶:=“2.11.8” // https://mvnrepository.com/artifact/org.apache.spark/spark-corelibraryDependencies=“org.apache.spark”%%“spark核心”%%“2.3
-
如何在雪花中基于返回值提交/回滚存储过程?
我有一个返回布尔值javascript存储过程。我希望能够在事务内部调用这个存储过程,并在提交事务之前测试返回值。 如何回滚存储过程中执行的语句?
-
雪花枢轴
-
花纹轮胎
概述 花纹轮胎通常与同步带轮90T一起使用。 参数 材质:硅胶 直径:68.5mm 宽度:22mm 搭建案例