《同花顺2023春招交流讨论》专题
-
 【华为OD机试2023】相同数字的积木游戏1(Python)
【华为OD机试2023】相同数字的积木游戏1(Python)题目描述: 小华和小薇一起通过玩积木游戏学习数学。 他们有很多积木,每个积木块上都有一个数字,积木块上的数字可能相同。 小华随机拿一些积木挨着排成一排,请小薇找到这排积木中数字相同且所处位置最远的2块积木块,计算他们的距离。 小薇请你帮忙替解决这个问题。 输入描述: 第一行输入为N,表示小华排成一排的积木总数。 接下来N行每行一个数字,表示小华排成一排的积木上数字。 输出描述: 相同数字的积木的位
-
 23交互秋招|蔚来 - 体验设计- 一面面经
23交互秋招|蔚来 - 体验设计- 一面面经八月简历挂的宝们可能会被再次捞回。蔚来反馈迅速,面完后3个工作日出结果。 一面面经 业务面,30Min。 「交互能力类」 1. 自我介绍 2. 分享作品集两个项目 (仅倾听,无细节盘问) 「车企理解/HMI积累类」 1. 为何选择蔚来/从互联网跨行车企 2. 对蔚来的理解 3. 特斯拉/蔚来等新能源车,有何了解?最喜欢哪个,WHY?是否试驾? 4. 对蔚来或其他头部车企的HMI设计有何看法? 5.
-
 23届秋招美团交互设计 - 快驴事业部
23届秋招美团交互设计 - 快驴事业部#设计人的面试记录# 概述:第一次捞我的是美团到店,业务蛮感兴趣的,就是三面后共享了emmm,后来快驴捞我,二面后由可靠消息说快驴的设计这块不是很推荐,就直接终止流程了。 问的问题: 1. 一面 (1)自我介绍 (2)作品集介绍 + 深挖 一面主要就是挖作品集,其他问题也问的不多 2. 二面: 二面就是直接问的测试题,可以看出来面我的应该是一位leader,对于测试题里的细节挖得非常非常细致。包括
-
 23交互秋招|蔚来 - 体验设计- 一面面经
23交互秋招|蔚来 - 体验设计- 一面面经一面面经,业务面,30Min。 「交互能力类」 1. 自我介绍 2. 分享作品集两个项目 (仅倾听,无细节盘问) 「车企理解/HMI积累类」 1. 为何选择蔚来/从互联网跨行车企 2. 对蔚来的理解 3. 特斯拉/蔚来等新能源车,有何了解?最喜欢哪个,WHY?是否试驾? 4. 对蔚来或其他头部车企的HMI设计有何看法? 5. 反问 面试复盘 「行业积累」 1. 面完就清晰知道失败结果。面试官直接反
-
 交互/体验设计秋招情况+经验分享(一)
交互/体验设计秋招情况+经验分享(一)情况分析一:面试中讲作品集的逻辑混乱,逢面必挂 经验: 1、从岗位描述/面经中了解某公司岗位的所需能力点,据此有针对性地确定要讲述的作品,再确定讲稿,然后根据讲稿来逐页修改作品集内。 2、按照此流程,你就能透过作品集来展示你拥有的与岗位匹配能力点,并且你面试讲述的内容能和作品集展示页一一对应,也方便面试官在你讲述时从作品集里找对应内容,使他信服你提到的能力点。 情况分析二:简历投出去石沉大海,不知
-
 22秋招字节跳动游戏交互设计面经
22秋招字节跳动游戏交互设计面经一面: (专业面 男性面试官是一位在游戏行业深耕了13年的前辈,为人比较亲和,说老婆跟我是老乡还唠了半天家常) 1.自我介绍 2.聊了一下对我笔试的看法。说我作品集和笔试逻辑性全局观之类的比较好,但界面上一些层级关系还是要加强(因为面试官是原画出身对视觉方面还是挺在意的),并且一些设计规范的问题,手机屏幕适配等等。 3.为什么从产品或普通交互转游戏交互。 4.目前投了哪些公司我怎样去考量有什么打算
-
 留学生校招|字节交互设计一面面经
留学生校招|字节交互设计一面面经一、用户体验五要素是哪些? 二、对于交互设计的理解? 三、我看你之前主要是做U和视觉的,怎么想到转做交互了? 四、讲作品集,然后进行提问: 1.我看你做了用户画像,你是怎么确定用户人群,怎么对你的用户人群进行分层。然后进行调研的? 2.你最终产出的这个用户画像,怎么确定它是有效的,代表大多数人的? 3.根据你们的人群特点,你产出的设计方案似乎并没有解决这个问题? 4.可用性测试,我看你对结果打分了
-
 23届秋招|百度提前批|交互设计三面
23届秋招|百度提前批|交互设计三面二面完等了一周终于三面了,整体算比较顺利,希望能有好的结果 1、问作品集 2、用户目的是什么,业务目的是什么 3、怎么通过设计达成目的 4、让再讲一个自驱的项目,核心回答做了什么设计,达到什么收益 5、怎么跟团队其他成员协同工作 6、组长在这个设计中起到的作用是什么 7、对公司的了解 8、对部门业务的了解,一、二面后针对这个部门做了什么准备 9、出了具体的设计题目问思路 10、职业规划、工作预期
-
 字节跳动 交互设计岗 秋招一面面经
字节跳动 交互设计岗 秋招一面面经面试流程: 投递—收到设计笔试题—提交笔试题—约面—一面—收到二面邀约 面试过程:面试体验还比较舒服,上来面试官比较客气地介绍了自己的身份,所属的部门,以及在做的项目等。然后就是常规的交互面试内容:自我介绍—作品集—面试官提问—反问。 整理一下几个问题: 比较注重细节,问了我项目里的“金选榜单”界面的星级评判标准,为什么选择金色,为什么选择星星等,还给我了一些设计建议。 讲解笔试题的时候,因为我选
-
 如何基于python实现画不同品种的樱花树
如何基于python实现画不同品种的樱花树本文向大家介绍如何基于python实现画不同品种的樱花树,包括了如何基于python实现画不同品种的樱花树的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了如何基于python实现画不同品种的樱花树,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 动态生成樱花 效果图(这个是动态的): 实现代码: 飘落效果 效果图: 实现代码: 暗色效
-
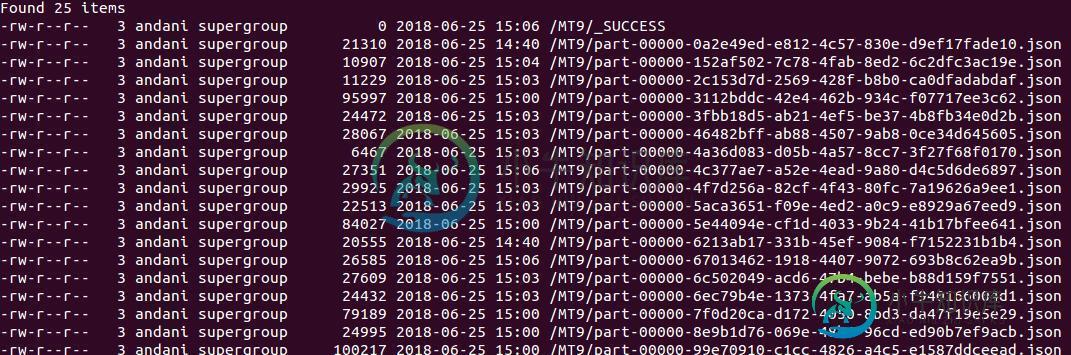 如何在HDFS中附加到相同的文件(火花2.11)
如何在HDFS中附加到相同的文件(火花2.11)我正在尝试使用SparkStreaming将流数据存储到HDFS中,但它会继续在新文件中创建附加到一个文件或几个多个文件中 如果它一直创建n个文件,我觉得效率不会很高 代码 在我的pom中,我使用了各自的依赖项: 火花-core_2.11 火花-sql_2.11 火花-streaming_2.11 火花流-kafka-0-10_2.11
-
火花驱动器和执行器在同一台机器上
在EMR集群或任何集群中,YARN有可能在同一个EC2实例中分配驱动程序和执行器吗?我想知道驱动程序是否可以利用1个EC2实例的存储和处理能力,或者该实例的某个部分将用于服务集群中运行的其他spark作业。这可能会导致我的驱动程序内存不足。 我认为资源管理器是根据集群资源的可用性来决定的?
-
 春招收官,字节跳动offered,前端实习,终于不用面试了
春招收官,字节跳动offered,前端实习,终于不用面试了本人github链接 求follow 春招面经 字节跳动国际化短视频tiktok(base:北京)一面凉 字节处女面竟然给了核心之核心tiktok,呜呜呜,压力极大 介绍项目和过往经历 算法:二叉树的路径总和A 算法:二叉树的所有路径 手写:手撕树型组件 反问感受:tiktok压力很大 字节跳动商业化技术(base: 上海)已offer 一面: 感受:轻松 js原型链 js基本类型 DOM事件机制
-
 多益网络2024年春招 游戏服务端开发 HR面+技术面
多益网络2024年春招 游戏服务端开发 HR面+技术面HR面(17min) 一.自我介绍 二.父母工作情况 三.对游戏服务端有多少了解 四.是否了解互联网公司工作强度 五.考虑是否入职的三个因素 六.了解多益吗,多益哪些方面吸引你 七.家里人支持自己在广州工作吗 八.素质测评的主观题为什么没有写满300字,看到要求了吗 九.是否投递过其他公司并拿到offer,毕业后是否还准备考研/考公 十.理想薪资是多少 十一.有没有抽烟 有反问 技术面(40min
-
Spark结构化流媒体中的拼花数据和分割问题
我正在使用Spark结构化流媒体;我的DataFrame具有以下架构 如何使用Parquet格式执行writeStream并写入数据(包含zoneId、deviceId、TimesInclast;除日期外的所有内容)并按日期对数据进行分区?我尝试了以下代码,但partition by子句不起作用