《数据人的面试交流地》专题
-
尝试使用JQuery加载本地JSON文件以在html页面中显示数据
问题内容: 嗨,我正在尝试使用JQuery加载本地JSON文件以显示数据,但出现一些奇怪的错误。我可以知道如何解决这个问题吗? 我只是在提醒JSON数据的数量。我的JSON文件与该html文件位于同一目录中,并且JSON字符串格式如下所示。 JSON文件名priority.json,错误为 未定义未捕获的Referenceerror优先级 问题答案: 就像jQuery API所说的:“使用GET
-
获取数字流的范围
问题内容: 给定一个,我可以做,但不能两者都做,因为它们中的任何一个都会消耗流。 现在假设我有 如何获得信息流的范围?(除以外) 问题答案: 您可以调用的方法。它返回一个包含最小值和最大值以及其他一些统计信息的对象:平均值,计数和总和。 并有类似的方法。
-
Kafka流:存储中的行数
我需要获取存储中的行数,存储在低级处理器API中维护。我看到,方法“近似数字条目()”可以在此存储中提供键值映射的近似计数。你能澄清一下准确度的%吗,这意味着如果商店里有100行,我们会得到95行作为近似计数吗?或者它有时会低于50行吗?只是想了解影响计数准确性的因素。 注意:假设流应用程序使用单个主题并在单个实例上运行。存储是通过低级处理器API访问的,不确定默认情况下是否应用了任何缓存。提交频
-
AWS Lambda函数外的NodeJS流
我们正在尝试将我们的 zip 微服务从节点js Express 中的常规应用程序迁移到与 AWS Lambda 集成的 AWS API 网关。 我们当前的应用程序向我们的API发送请求,获取附件列表,然后访问这些附件并将其内容以zip存档的形式传回给用户。它看起来像这样: 除了必须将内容从Lambda函数中流出来的部分,我已经设法完成了所有的工作。< br >我认为可能的解决方案之一是使用aws-
-
 滴滴-国际化数据部-大数据开发面经
滴滴-国际化数据部-大数据开发面经2023春招找实习的同学跟我分享了他的面试经历,在这里我进行了一些总结梳理,然后发出来供大家学习 注意这是日常实习!!! 1.自我介绍 2.刷题 冒泡排序 3.八股文 3.1 JVM JVM的内存结构 类的加载过程 静态代码块和代码块初始化的顺序,以及静态代码块在哪个阶段被加载【初始化】 垃圾回收器 一个方法报错了,怎么进行分析,比如A方法调用B方法,B方法调用C方法....【没太懂】 3.2 并
-
前端 - vue3+ts项目中提交表单数据如何通过邮件或者手机号或者微信提醒通知有人提交信息了?
vue3+ts项目中提交表单数据如何通过邮件或者手机号或者微信提醒通知有人提交信息了?
-
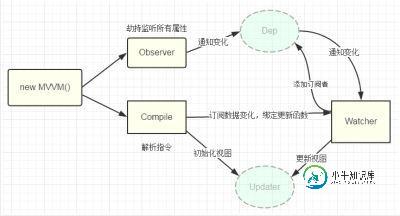 使用Vue如何写一个双向数据绑定(面试常见)
使用Vue如何写一个双向数据绑定(面试常见)本文向大家介绍使用Vue如何写一个双向数据绑定(面试常见),包括了使用Vue如何写一个双向数据绑定(面试常见)的使用技巧和注意事项,需要的朋友参考一下 1、原理 Vue的双向数据绑定的原理相信大家也都十分了解了,主要是通过 Object对象的defineProperty属性,重写data的set和get函数来实现的,这里对原理不做过多描述,主要还是来实现一个实例。为了使代码更加的清晰,这里只会实现
-
 网易互娱大数据研发工程师面试经验分享
网易互娱大数据研发工程师面试经验分享本人社招,面试大数据研发工程师岗位,一共三轮面试。 1、一面(技术面),约40分钟,面试题如下: (0)自我介绍,别照着简历说,补充说些简历上没有的,比如哪里人、兴趣爱好、优势有哪些等。 (1)笔试,编程题,语言自选,题目:输入一个字符串,找出其中的整数,按升序排序后输出,多个相连的数字为一个整数,排序可用类库自带方法。 实现很简单,这里就不提供答案了。 (2)笔试,SQL编程,
-
 短视频业务数据指标体系面试题与解析 1
短视频业务数据指标体系面试题与解析 1面试高频题1: 题目:短视频业务中有哪些常用指标? 答案解析: 对内容产品来说,第一步就是“有内容”,即内容的生产环节。 不同的内容产品为我们提供了不同的选择,抖音快手的产品类型是短视频,知乎的“产品”是问题,微博的产品是动态,腾讯优酷的产品是电视剧电影。但不论产品的形态如何多变,在观察指标时,都可以考虑从在线、新增、原创、精品、违规等几个指标监控内容产品的丰富度、热度与质量。比如某平台在推广过程
-
 短视频业务数据指标体系面试题与解析2
短视频业务数据指标体系面试题与解析2面试高频题4: 题目:怎么衡量你在业务部门的贡献 业务部门是数据分析师分析所服务的相关方,包括产品、运营等 答案解析: 能否驱动业务提供方向和结论,并有明显业务效益的提升 能否理解业务并提供专业的意见,从而解决了业务方的一些难题 能否对业务充分理解,并能高效做出取数和数据报表等操作,提升业务方效率 拿日常工作详细举例: 比起零散的跑数据,提供有效的数据报表更有效一些 能有一些数据可视化的展示,比纯
-
 【这才是重量级框架】大数据开发面试题【Spark篇】
【这才是重量级框架】大数据开发面试题【Spark篇】115、Spark的任务执行流程 driver和executor,结构式一主多从模式,driver:spark的驱动节点,用于执行spark任务中的main方法,负责实际代码的执行工作;主要负责:将代码逻辑转换为任务、在executor之间调度任务、跟踪executor的执行情况。 Executor:spark的执行节点,是jvm的一个进程,负责在spark作业中运行具体的任务,任务之间相互独立,
-
 2023暑期实习-面试-蚂蚁集团-数据研发工程师
2023暑期实习-面试-蚂蚁集团-数据研发工程师公司:蚂蚁集团 部门:CTO线-数据产品与技术部 岗位:数据研发工程师 形式:电话面试 时长:22分钟 流程: 1、自我介绍。 2、介绍一下实习的工作。 3、这个项目中有几个人? 4、在项目中遇到了什么困难? 5、实习的公司有没有类似数据中台的部门? 6、在数据预处理方面做了哪些事情?怎么保障数据的规范性和准确性? 7、介绍一下建模的工作。 8、学校里有没有学过数据挖掘相关的课程? 9、对于分类和
-
 2023暑期实习-面试-蚂蚁集团-数据研发工程师
2023暑期实习-面试-蚂蚁集团-数据研发工程师公司:蚂蚁集团 部门:信贷事业群-风险管理部 岗位:数据研发工程师 形式:电话面试 时长:31分钟 流程: 1、自我介绍。 2、对数据开发岗有了解吗? 3、实习的时候接触到的数据来自哪里? 4、你是怎么理解数据仓库这个岗位的? 5、你刚才提到了数据沉淀,那你觉得有哪些方法来做数据沉淀? 6、如果让你做数据ETL的话你有兴趣吗? 7、对大数据的技术栈哪些比较熟悉? 8、传统的数据仓库和关系型数据库有
-
带有混合工作负载的数据流作业-流式插入和加载作业(Python)
https://cloud.google.com/blog/products/data-analytics/how-to-how高效处理实时和聚合数据 用例说明步骤: 从pubsub获取流式原始事件。 验证接收的原始事件。 筛选特定类型的事件。 创建筛选事件的字典。 同时,将筛选的事件通过窗口操作传递并聚合。 2种输出类型-原始事件字典、聚合事件字典。 按照上面链接中解释的设计,原始事件字典属于低
-
 我的面试经验
我的面试经验记录2:2.5笔试 1. C++写一个简易的计算器 2. TCP/IP 协议分层及理解 :https://blog.csdn.net/weixin_53695360/article/details/124585802 3. 对象构造和析构顺序 first: 调用父类的构造函数 second: 调用成员变量的构造函数(调用顺序与声明顺序相同) finally: 调用类自身的构造函数 **** 析构函