《数据人的面试交流地》专题
-
 网易游戏实习交互设计师面试记录
网易游戏实习交互设计师面试记录专业面: -玩过什么游戏,补问了手游,又问了主流手机游戏回答了PC-MMORPG, GBA, NDS, 以及SKY,不太涉及主流手游- 笔试题目介绍 讲了交流系统的实现与对界面设计的影响,问了地图弹窗的设计,又补充了玩家交互;聚焦了图纸建造的交互操作如何实现; 用户体验部门面试: 如何学习交互设计的方法? 在近期读书-设计的软件如何学习? 如何积累交互设计作品?实习,参加设计营,加设计说明- 为什
-
 网易游戏实习交互设计师面试记录
网易游戏实习交互设计师面试记录第一轮是交互设计师面试,算是专业面吧,主要聊作品集,挑一个自己觉得好的描述一下,然后根据你的回答问一些专业相关问题,问的很细。下面是一些问题记录 Q1:你手机中你觉得最好用的app Q2:玩哪些游戏?评价一下 Q3:如何做交互设计? Q4:觉得产品需求必需很清晰吗?不清晰的情况下你怎么做接下来的交互设计? Q5:你的核心驱动力是什么? 第二轮应该是产品开发的负责人面试,问的都不是专业相关,主要是
-
 交互设计实习 面试经验( 北京 ) - 爱奇艺
交互设计实习 面试经验( 北京 ) - 爱奇艺面试形式:电话面试 1对1面试 问题记录: 1、自我介绍 2、作品集讲解,详细介绍每一个。就作品集的作品问 ,设计的创新点是什么 3、交互知识相关问题:如交互规范,为什么这样设计。 4、20分钟的一个小笔试。类似一个小需求,要求画低保真界面 5、自己的优缺点
-
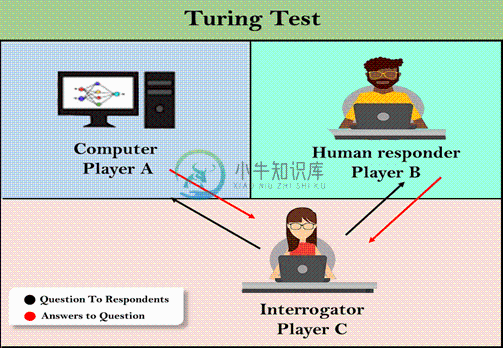 人工智能图灵测试
人工智能图灵测试主要内容:聊天机器人尝试图灵测试,中国室的争论1950年,艾伦·图灵(Alan Turing)介绍了一项测试,以检查机器是否能像人类一样思考,这项测试称为图灵测试。在这个测试中,图灵提出如果计算机可以在特定条件下模仿人类的反应,那么可以说计算机是智能的。 图灵在其1950年的论文“计算机器和智能”中介绍了图灵测试,该论文提出了“机器能想到吗?”的问题。 图灵测试基于派对游戏“模仿游戏”,并进行了一些修改。这个游戏涉及三个玩家,其中一个玩家是计
-
ReactorKafka制作人-无法重试
我已经使用reactor-kafka(kafka的一个功能性Java API)创建了一个KafkaProducer(reactor.kafka.sender.KafkaSender)。使用以下生产者配置, 当我试图发布一个记录到一个无效的主题我得到超时异常 正如所料。但我已经为没有发生的重试进行了配置。我假设在/已过期,每次直到或
-
 巨人网络游戏测试
巨人网络游戏测试1.自我介绍 2.为什么投游戏测试岗位? 3.对游戏测试工作有什么了解? 4.游戏测试都需要做什么? 5.平时玩什么游戏 6.一天会花多长时间在游戏 7.最近玩了什么游戏 8.端游呢? 9.对我们公司有什么了解? 10.对工作的计划? 11.linux操作命令 12.对数据库的增删改查了解吗?删除是什么? 13.sql插入语句 14.能接受加班吗? 15.反问
-
Java8中使用流方式查询数据库的方法
本文向大家介绍Java8中使用流方式查询数据库的方法,包括了Java8中使用流方式查询数据库的方法的使用技巧和注意事项,需要的朋友参考一下 由于关系型数据库操作语言和面向对象语言之间的差异,如今我们仍然需要花费许多时间建立数据库与 Java 应用之间互相沟通的桥梁。通常,我们可以编写自己的映射层(mapping layer),或者使用第三方的 ORM(Object Relational Mappe
-
如何通过带有node.js和socket.io的WebSockets流MP3数据?
问题内容: 我在通过带有node.js和socket.io的WebSocket流MP3数据时遇到问题。一切似乎都可以正常工作,但是解码音频数据对我来说并不公平。 这是我的玩具服务器: 客户端以字符串类型接收数据,但我想将数据提供给解码音频数据,看来它不喜欢字符串。调用encodeAudioData会导致以下错误消息: 我认为解码音频数据需要存储在ArrayBuffer中的数据。有没有办法转换数据?
-
Spring Cloud数据流-无法转换来自Kafka的消息
使用Spring Cloud DataFlow 1.2.2版本,配置如下: 我正在尝试创建一个流,它将从特定主题中读取并将其刷新到长水槽中,如下所示: 查看日志文件,我可以看到以下错误: 我还试图为kafka源代码的消费者/生产者配置一些属性 但我得到的结果是一样的 以下是Spring DataFlow打印的消费者详细信息: 我看到了类似的查询,但没有有效的答案,什么是属性来接受二进制json消息
-
Android中wifi与数据流量的切换监听详解
本文向大家介绍Android中wifi与数据流量的切换监听详解,包括了Android中wifi与数据流量的切换监听详解的使用技巧和注意事项,需要的朋友参考一下 最近在做一个wifi和移动数据的监控功能,来来回回折腾了一阵子,这个模块的主要功能是监听整个APP的wifi与数据流量的切换,让用户使用专用流量,而不是用wifi,给一个弹窗,点击确认,自动切换数据流量,关闭wifi。我的思路是写一个静态广
-
python 连接各类主流数据库的实例代码
本文向大家介绍python 连接各类主流数据库的实例代码,包括了python 连接各类主流数据库的实例代码的使用技巧和注意事项,需要的朋友参考一下 本篇博文主要介绍Python连接各种数据库的方法及简单使用 包括关系数据库:sqlite,mysql,mssql 非关系数据库:MongoDB,Redis 代码写的比较清楚,直接上代码 1.连接sqlite 2.连接mysql 2.1使用mysqldb
-
在带有颤振的Firebase中使用流检索数据
也许这是一个新手问题,但我正在学习颤振和一些东西,如异步、等待、未来,还不适合我的想法。无论如何,我要做的是从“field.documents[index][“name”]”中获取值,并构建一个列表。这是我的代码: 我想让productName在foreach之外。当我打印时,它首先打印null。我也会发布我的整个函数: 谁能帮帮我吗?我知道它与异步编程有关,但我正在学习。谢谢
-
Hadoop对数据流不太大的系统有开销吗?
我计划编写一个批处理分布式计算系统,它将使用大约10-20台计算机。系统某些部分的数据流约为50GB,其他部分的数据流约为1GB。 我正在考虑使用Hadoop。可扩展性并不重要,但我真的很喜欢Hadoop framewok提供的容错和推测运行功能。MPI或gearman等框架似乎不提供这样的机制,我将不得不自己实现它们。 然而,我有一些疑问,因为它似乎是针对更大的数据量和可能更多的计算机进行优化的
-
无法解码Spring Cloud数据流中key:file_name的json类型
我使用Spring Cloud Data Flow设置一个读取CSV文件的流,使用自定义处理器对其进行转换并记录: 文件和csvToMap应用程序工作正常,但在日志应用程序中,我看到这种异常,对于每条记录: 对于file\u relativePath标头,也会引发此异常。我不明白为什么斯普林·Kafka试图将它们解读为JSON。 此外,日志接收器以正确的方式记录我的记录: 出于调试目的,我将kaf
-
使用airflow的DataflowPythonOperator计划数据流作业时出错
我正在尝试使用airflow的DataflowPythonOperator计划数据流作业。这是我的dag操作员: gcp_conn_id已设置,可以正常工作。错误显示数据流失败,返回代码为1。完整日志如下所示。 gcp_dataflow_hook.py似乎有问题,除了这个没有更多的信息。有没有办法解决这个问题,有没有DataflowPython算子的任何例子?)到目前为止,我找不到任何使用案例)