《数据人的面试交流地》专题
-
 深入理解Vue 单向数据流的原理
深入理解Vue 单向数据流的原理本文向大家介绍深入理解Vue 单向数据流的原理,包括了深入理解Vue 单向数据流的原理的使用技巧和注意事项,需要的朋友参考一下 单向数据流是什么 单向数据流指只能从一个方向来修改状态。下图是单向数据流的极简示意: 单向数据流的极简示意 与单向数据流对对应的是双向数据流(也叫双向绑定)。在双向数据流中,Model(可以理解为状态的集合) 中可以修改自己或其他Model的状态, 用户的操作(如在输入框
-
从Kinesis中的两个不同流获取数据?
我正试图成为一个动觉消费者客户。为了解决这个问题,我阅读了《Kinesis开发人员指南》和AWS文档http://docs.aws.amazon.com/kinesis/latest/dev/kinesis-record-processor-implementation-app-java.html. 我想知道是否有可能从两个不同的流中获取数据并进行相应的处理。 假设我有两个不同的流,分别是流1和流
-
GCP数据流是否支持python中的kafka IO?
我正在尝试使用Kafka从Kafka主题中读取数据。python代码中的ReadFromKafka()方法。我的代码如下所示: 但下面是错误消息。
-
确定数据流中的关键路径[重复]
在《计算机系统:程序员的视角》一书中,练习5.5显示了一段计算多项式值的代码 本练习假设双精度浮点加法和乘法所需的时钟周期分别为3和5。读者被要求解释为什么测量的CPE(每元素周期)值为5。 根据练习答案,在每次迭代中,我们需要更新变量xpwr和result,我们需要的操作是浮点加法(对于结果)和浮点乘法(对于xpwr),因此后者控制延迟,导致最终CPE为5。 但我认为数据流应该是这样的: 所以最
-
Gevent与流服务器的数据库连接池
我使用PythonGevent的流服务器与另一台机器(远程)进行通信,该机器发送并发TCP/IP请求(平均每秒钟60个请求)。这种通信的本质主要是IO绑定的(短文本,然后是音频流)。我打算使用Postgresql存储每次通信的结果(例如:从远程服务器接收的文件名)。 我认为为Streamserver中生成的每个greenlet调用一个新的db连接是个坏主意(池大小为90所以90 req/sec m
-
数据流中的自定义Apache Beam Python版本
我想知道是否有可能在Google数据流中运行一个定制的Apache Beam Python版本。在公共存储库中不可用的版本(撰写本文时为0.6.0和2.0.0)。例如,ApacheBeam的官方存储库中的HEAD版本,或该问题的特定标记。 我知道可以按照官方文件中的说明包装定制包装(例如,私人本地包装)。这里有一些关于如何为其他脚本执行此操作的问题。甚至有一个要点指导这一点。 但是,我还没有获得当
-
Flink流媒体示例,生成自己的数据
早些时候,我问了Flink一个简单的hello world示例。这给了我一些很好的例子! 然而,我想问一个更“流”的例子,我们每秒生成一个输入值。这在理想情况下是随机的,但即使每次都是相同的值也可以。 目标是获得一个无需/最少外部接触就能“移动”的流。 因此,我的问题是: 我发现如何显示这与外部生成数据和写入Kafka,或听一个公共源,但是我试图解决它与最小的依赖性(像在Nifi与Generate
-
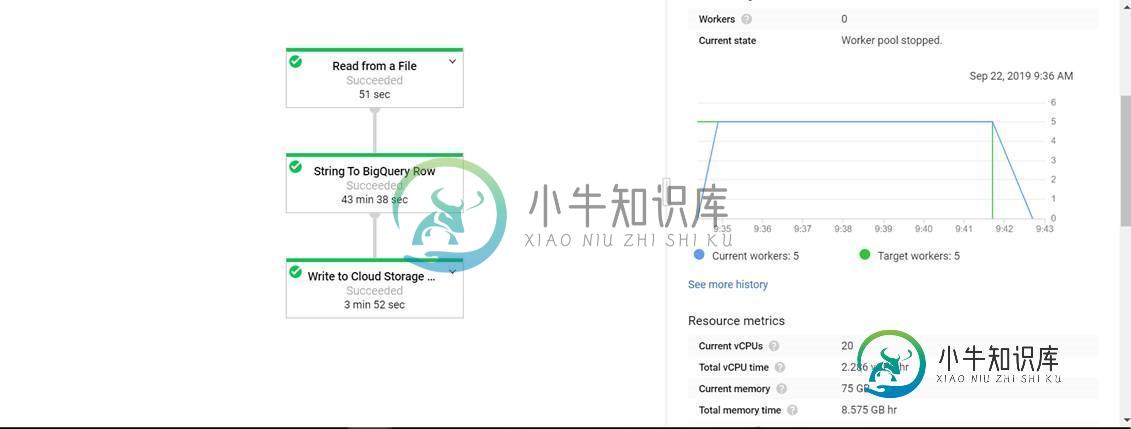 写入BigQuery时的云数据流性能问题
写入BigQuery时的云数据流性能问题我试图用Cloud Dataflow(Beam Python SDK)将它读写到BigQuery。 读写2000万条记录(约80 MBs)几乎需要30分钟。 查看dataflow DAG,我可以看到将每个CSV行转换为BQ行花费了大部分时间。
-
Oracle12.2数据库中CLOB的JDBC流编码错误
对于Oracle12.2,输出如下: JDBC驱动程序错误地自动检测字符集为UTF-8,但流实际上是在ISO8859-15中。在JDBC8中不能显式设置字符集。从数据库返回的流是在Oracle 12.1下用UTF-8编码的
-
StackDriver:来自特定数据流PCollection输出的ElementCount
我有一个dataflow工作,它从几个Google Pub/Sub主题中提取消息,对这些消息中包含的单个元素进行一些并行处理,然后将集合传递给各种资源进一步使用。我想把一个Stackdriver仪表板放在一起,显示每个主题处理了多少个单独的元素。每个ParDo步骤输出一个pCollection。 我已经使用ElementCount设置了一个仪表板,但我只能按作业进行筛选,而不能按步骤进行筛选。如果
-
气流异常:数据流失败,返回代码为2
我正在尝试执行一个DataflowPython文件,该文件使用DataFlowPythonOperator通过气流DAG从GCS存储桶读取文本文件。我已经能够独立地执行python文件,但是当我通过airflow执行它时,它失败了。我正在使用服务帐户对默认gcp连接进行身份验证。我在执行作业时遇到的错误是: 我的脚本: 我的数据流python文件(1readfromgcs.py)包含以下代码: 感
-
 游戏业务数据指标体系面试题1
游戏业务数据指标体系面试题1面试高频题1: 题目:游戏业务中有哪些常用指标? 答案解析 比较关键的指标,流量相关的有用户量、用户转化率、留存率,内容相关的有用户在线时长、有效游戏时长,收入相关指标有用户付费率、LTV、ROI等。 面试高频题2: 题目:怎么制定游戏业务的目标 制定目标可以套用SMART原则 SMART是一个目标设定原则,能够帮助我们以及团队设置具体的、可衡量的、可实现的、相关的和有时间期限的目标,从而提高工作
-
 游戏业务数据指标体系面试题2
游戏业务数据指标体系面试题2面试高频题4: 题目:怎么衡量你在业务部门的贡献 业务部门是数据分析师分析所服务的相关方,包括产品、运营等 答案解析: 数据分析师比较像游戏中的辅助角色,也是非常关键的 所以,衡量标准为: 能否驱动业务提供方向和结论,并有明显业务效益的提升 能否理解业务并提供专业的意见,从而解决了业务方的一些难题 能否对业务充分理解,并能高效做出取数和数据报表等操作,提升业务方效率 拿日常工作详细举例: 比起零散
-
 电商业务数据指标体系面试题1
电商业务数据指标体系面试题1面试高频题1: 题目:电商业务中有哪些常用指标? 答案解析: 1、流量指标 (1)UV (2)PV (3)访问人数 (4)新访问占比 (5)实例数 (6)访问深度 (7)停留时间 (8)跳出率 (9)退出率 (10)产品页转化率 (11)加入购物车转化率 (12)结算转化率 (13)购物车内转化率 2、商品数据化运营指标 (1)订单量和商品销售量 (2)GMV (3)商品销售额和订单金额 (4)平
-
 快手电商数据分析实习面试(凉经)
快手电商数据分析实习面试(凉经)快手电商面试好难啊,面试官是个特别好的小哥,不过问的问题还是暴露了我能力不足啊感觉凉了啊。 首先是他自我介绍,快手电商用户买家提升部门的,然后介绍了面试环节。首先是自我介绍;接着是简历问题,要求我介绍下在Kaggle上的项目经历;接下来是问题环节,首先问我ABtest流程,幸好我之前恶补了说完之后他的评价是还行,如果有具体场景应该能更清楚,但是接下来就是一个我完全没记住的问题了,计算最小样本量需要