《分奖金》专题
-
分区分布不均匀
我们在AWS上运行16个节点kafka集群,每个节点是m4. xLargeEC2实例,具有2TB EBS(ST1)磁盘。Kafka版本0.10.1.0,目前我们有大约100个主题。一些繁忙的话题每天会有大约20亿个事件,一些低量的话题每天只有数千个。 我们的大多数主题在生成消息时使用UUID作为分区键,因此分区分布相当均匀。 我们有相当多的消费者使用消费群体从这个集群消费。每个使用者都有一个唯一的
-
1.3.4.3 行为分析分群
用户分群是一种用户运营和用户分析手段,通过对特定用户进行定向投放实现精细化运营,通过对某一个用户群体分析发现不同用户的特征以及偏好。HubbleData的分群区别于传统的标签体系,支持产品策划或者运营人员通过行为数据指定用户,具体使用场景包括: 策划,交互或者视觉同事,通过对比不同分群用户对产品的使用,发现用户特征以优化产品设计 运营通过用户分群定向投放,实现用户的精细化运营 HubbleData
-
 thinkphp3.2.3 分页代码分享
thinkphp3.2.3 分页代码分享本文向大家介绍thinkphp3.2.3 分页代码分享,包括了thinkphp3.2.3 分页代码分享的使用技巧和注意事项,需要的朋友参考一下 对于thinkphp分页的实现效果,两种调用方法,一种调用公共函数中的函数方法(参考http://www.cnblogs.com/tianguook/p/4326613.html),一种是在模型中书写分页的方法 1、在公共函数Application/C
-
按母体分区分硒
试图找到“一个href”的链接元素。代码段: null 谁能告诉我,我如何首先获得父div,然后找到div中的内容(从顶部到底部)
-
分部分解密文件
所以我有这些大文件(6GB+),我需要在32位计算机上解密。我以前使用的一般过程是读取内存中的整个文件,然后将其传递给解密函数,然后将其全部写回一个文件。由于内存限制,这实际上不起作用。我尝试将文件分成几部分传递给decrypt函数,但在将文件发送给decrypt函数之前,它似乎会在分解文件的边界附近搞乱。 以下是我的解密函数/我尝试部分解密。
-
Cassandra分区vs NoSql分区
我理解了与Cassandra分区键、复合键、集群键的区别。但是没有找到足够的信息来理解cassandra中如何处理分区 在cassandra中,分区密钥的范围像分区/碎片一样存储在节点上。我的理解是否正确 每个分区键在数据库中是否有不同的文件(在系统级别)。。?如果是这样的话,读取速度不是会变慢吗 如果每个分区键在数据库中没有不同的文件。怎么处理的。。?
-
1.5.3.2.13.3 选址分区分析
选址分区分析是为了确定一个或多个待建设施的最佳或最优位置,使得设施可以用一种最经济有效的方式为需求方提供服务或者商品。选址分区不仅仅是一个选址过程,还要将需求点的需求分配到相应的新建设施的服务区中,因此称之为选址与分区。 设置选址分区分析参数,包括交通网络分析通用参数、途径站点等。 //设置设施点的资源供给中心 var supplyCenterType_FIXEDCENTER = SuperMap
-
Zebra 分库分表接入
该文档主要介绍Zebra分库分表ShardDataSource的接入和使用,主要包括分库分表的背景知识、ShardDataSource的配置、分库分表规则的配置等。 2 准备 2.1 背景介绍 在一个业务刚上线时,可能使用某个单表存储数据。随着时间的推移和用户的增加,单表内的数据量会不断变大,总有一天数据量会大到一个难以处理的地步。这时仅仅一张表的数据就可能过亿甚至更多,无论是查询还是修改,对于它
-
Zebra 分库分表介绍
读写分离,主要是为了数据库读能力的水平扩展(参考:Zebra读写分离介绍) 一旦业务表中的数据量大了,从维护和性能角度来看,无论是任何的 CRUD 操作,对于数据库而言都是一件极其耗费资源的事情。即便设置了索引, 仍然无法掩盖因为数据量过大从而导致的数据库性能下降的事实 ,这个时候就该对数据库进行 水平分区 (sharding,即分库分表 ),将原本一张表维护的海量数据分配给 N 个子表进行存储和
-
使用分配分析器
使用分配分析器工具来查找未被正确地垃圾收回收,并继续保留在内存中的对象。 分配分析器如何工作 allocation profiler(分配分析器)结合了堆分析器中快照的详细信息以及Timeline(时间轴)面板的增量更新以及追踪信息。与这些工具相似,追踪对象堆的分配过程包括开始记录,执行一系列操作,以及停止记录并分析。 分配分析器在记录中周期性生成快照(频率为每50毫秒),并且在记录最后停止时也会
-
詹金斯Git积分
我是詹金斯的新手,在我本地的windows机器上安装了它。 禽类
-
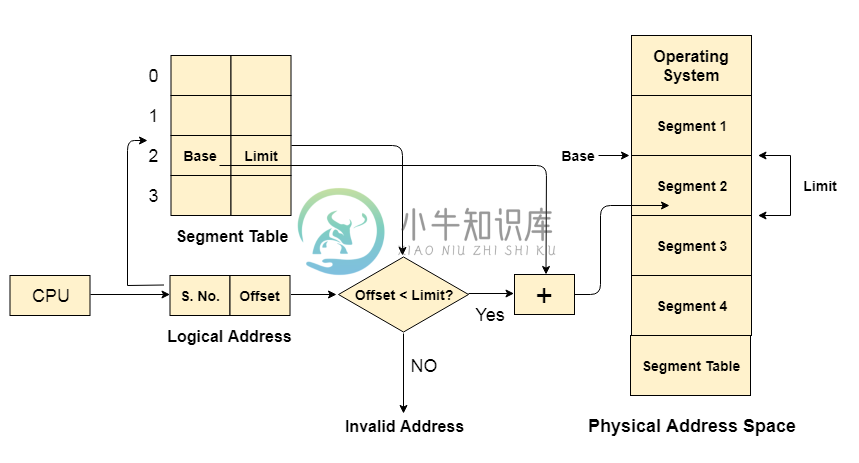 分段
分段主要内容:为什么需要分段?,逻辑地址按段表转换为物理地址在操作系统中,分段是一种内存管理技术,其中内存分为可变大小的部分。 每个部分被称为可以分配给进程的段。 有关每个段的详细信息存储在称为段表的表中。 分段表存储在一个(或多个)分段中。 分段表主要包含两个关于分段的信息: 基:它是细分分段的基地址 限制:它是分段的长度。 为什么需要分段? 到目前为止,我们使用分页作为主要内存管理技术。 分页更接近操作系统而不是用户。 它将所有进程划分为页面形式,而不
-
分页
Django提供了一些类来帮助你管理分页的数据 -- 也就是说,数据被分在不同页面中,并带有“上一页/下一页”标签。这些类位于django/core/paginator.py中。 示例 向Paginator提供对象的列表,以及你想为每一页分配的元素数量,它就会为你提供访问每一页上对象的方法: >>> from django.core.paginator import Paginator >>> o
-
分析
StackExchange.Redis公开了一些方法和类型来启用性能分析。 由于其异步和多路复用 表现分析是一个有点复杂的主题。 接口 分析接口由 IProfiler, ConnectionMultiplexer.RegisterProfiler(IProfiler) ,ConnectionMultiplexer.BeginProfiling(object) , ConnectionMultipl
-
分页
当一次要在一个页面上显示很多数据时,通常需要将其分成几部分, 每个部分都包含一些数据列表并且一次只显示一部分。这些部分在网页上被称为分页。 Yii 使用 yii\data\Pagination 对象来代表分页方案的有关信息。特别地, total count 指定数据条目的总数。 注意,这个数字通常远远大于需要在一个页面上展示的数据条目。 page size 指定每页包含多少数据条目。 默认值为 2