《分奖金》专题
-
1.3.3.5 分布分析
1. 简介 分布分析报告可以帮助您查看事件在不同区间的发生频次,从而判断用户的使用习惯和活跃情况。除了次数,您还能够查看其它事件指标的用户数量分布。 分布分析能够帮助您洞察这些问题: · 对比不同来源渠道的用户在站点的行为次数分布,如浏览页面1-3次,3-10次,10次以上,不同区间的用户数量有多少 · 上周推广活动客单价的人数分布情况 · 改版后,用户的每日启动次数是否增加 2. 使用说明 2
-
 分库分表:ShardingSphere
分库分表:ShardingSphere主要内容:1.ShardingSphere概念,2.功能列表,3.项目状态,4.分库分表_结果归并1.ShardingSphere概念 ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由、和 这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务 和 数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。 Apache ShardingSphere 旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现
-
Facebook受众网络广告(有奖、横幅、间隙广告)未在发布模式下显示
我有一个应用程序,应该在调试模式下使用Facebook观众网络显示一些广告。但在发布模式下,即使相同的代码正在运行调试版本,也不会发生任何事情。在发布模式下(从Google playstore下载),它会在logcat中显示以下错误 错误:Interstival-'Interstival ad加载失败:ad请求中的显示格式与为此放置指定的显示格式不匹配。每个放置只能用于一种显示格式。您可以创建多个
-
句子分类(分类)
问题内容: 我一直在阅读有关文本分类的文章,并找到了几种可用于分类的Java工具,但我仍然想知道:文本分类与句子分类一样! 有没有专门针对句子分类的工具? 问题答案: “文本分类”和“句子分类”之间没有形式上的区别。毕竟,句子是一种文本。但是总的来说,当人们谈论文本分类时,恕我直言,他们指的是更大的文本单元,例如文章,评论或演讲。将政治人物的讲话归类为民主人士或共和党人比对推文进行分类要容易得多。
-
Elasticsearch分析百分比
问题内容: 我正在使用Elasticsearch 1.7.3累积用于分析报告的数据。 我有一个包含文档的索引,其中每个文档都有一个名为“ duration”的数字字段(请求花费了几毫秒)和一个名为“ component”的字符串字段。可能有许多具有相同组件名称的文档。 例如。 我想生成一份报告,说明每个组件: 此组件的所有“持续时间”字段的总和。 此总和在 所有 文档的总期限中所占的百分比。在我的
-
7 分页和分段
分页: 用户程序的地址空间被划分成若干固定大小的区域,称为“页”,相应地,内存空间分成若干个物理块,页和块的大小相等。可将用户程序的任一页放在内存的任一块中,实现了离散分配。 分段: 将用户程序地址空间分成若干个大小不等的段,每段可以定义一组相对完整的逻辑信息。存储分配时,以段为单位,段与段在内存中可以不相邻接,也实现了离散分配。 分页与分段的主要区别 页是信息的物理单位,分页是为了实现非连续分配
-
html分区与分区
我正在制作一个web组件,一个导航栏(或navbar)。里面有四个部分,标志,菜单,切换器,和额外。 问题是,我应该对每个部分使用 还是 ? 还是有更合适的元素类型? 插图是这样的: 匿名用户 这是一个很棒的问题,并且与语义HTML相关。根据MDN,当没有其他标记真正相关或合适时,我们应该使用section标记。如果意图是一个实际的节,那么它还应该包括一个节头。 HTML 元素表示文档的一个通用的
-
主成分分析 PCA
目录 综述 01 使用梯度上升法求解主成分 demean 梯度上升法 02 获得前n个主成分 03 从高维数据向低维数据的映射 04 scikit-learn中的PCA 05 使用PCA降噪 手写识别例子 人脸识别 06 特征脸 特征脸 综述 “明道若昧;进道若退;夷道若颣;大方无隅;大器免成;大音希声;大象无形。” 本文采用编译器:jupyter 主成分分析 是一个非监督的机器学习算法
-
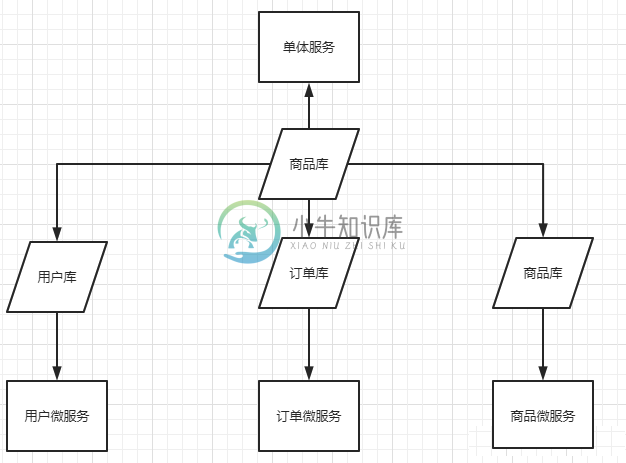 分库分表-入门
分库分表-入门主要内容:1.数据库瓶颈,2.垂直切分,3.水平切分,4.数据分片规则,5.分库分表带来的问题1.数据库瓶颈 不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务Service来看就是,可用数据库连接少甚至无连接可用。 (并发量、吞吐量、崩溃)。 1.1 IO瓶颈 第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 -> 分库和垂直分表。 第二种:网络IO瓶颈,请求的数据太多,
-
1.12 第十一部分 主成分分析
第十一部分 主成分分析(Principal components analysis) 前面我们讲了因子分析(factor analysis),其中在某个 $k$ 维度子空间对 $x \in R^n$ 进行近似建模,$k$ 远小于 $n$,即 $k \ll n$。具体来说,我们设想每个点 $x^{(i)}$ 用如下方法创建:首先在 $k$ 维度仿射空间(affine space) ${\Lambda
-
 23秋招东方财富提前批前端一面 二面 hr面主管更新已开奖
23秋招东方财富提前批前端一面 二面 hr面主管更新已开奖已意向的可以私聊进群 9.1更新主管面 其实早就面完了忙着没打开过牛客😂 主管面很简单 流程是二十个人等待三个不同面试官,时间从七八分钟到二十分钟不等,HR小姐姐一直强调时长跟评价无关,是面试官特性 问学校以及学校经历 科目 社团经历 比赛经历 这些经历除了技术你收获了什么 为什么就业不考研 为什么选前端 是兴趣还是观察到前景 个人建议自我介绍可以略过技术栈枚举 多点学校经历丰富多说点 一面 自
-
为什么在Facebook Audience Network的创建位置中没有显示奖励视频广告类型?
我有一个游戏应用程序,我正在使用admob进行调解。对于横幅广告和插页广告,我使用admob和Facebook观众网络。但对于奖励广告,我也想使用Facebook奖励视频广告。但当我尝试创建一个位置时,没有奖励类型的广告。它显示在下面的广告类型1)原生2)横幅3)中间4)中等矩形 没有奖励广告单元。问题是什么?Admob doc显示FAN支持奖励视频https://developers.googl
-
C#中分部方法和分部类分析
本文向大家介绍C#中分部方法和分部类分析,包括了C#中分部方法和分部类分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了C#中分部方法和分部类。分享给大家供大家参考。 具体代码如下: 希望本文所述对大家的C#程序设计有所帮助。
-
1.13 第十二部分 独立成分分析
第十二部分 独立成分分析(Independent Components Analysis ) 接下来我们要讲的主体是独立成分分析(Independent Components Analysis,缩写为 ICA)。这个方法和主成分分析(PCA)类似,也是要找到一组新的基向量(basis)来表征(represent)样本数据。然而,这两个方法的目的是非常不同的。 还是先用“鸡尾酒会问题(cocktai
-
分页与分段比较
分页与分段比较,如下表所示 - 编号 分页 分段 1 非连续的内存分配 非连续的内存分配 2 分页将程序分成固定大小的分页。 分段将程序分成可变大小的段。 3 由操作系统负责 由编译器负责。 4 分页比分段更快 分段比分页慢 5 分页更接近操作系统 分段更接近用户 6 它会遭受内部碎片问题 它会遭受外部碎片问题 7 没有外部碎片 没有外部碎片 8 逻辑地址分为:页码和页码偏移 逻辑地址分为:分段号