
Zebra 分库分表介绍
读写分离,主要是为了数据库读能力的水平扩展(参考:Zebra读写分离介绍)
一旦业务表中的数据量大了,从维护和性能角度来看,无论是任何的 CRUD 操作,对于数据库而言都是一件极其耗费资源的事情。即便设置了索引, 仍然无法掩盖因为数据量过大从而导致的数据库性能下降的事实 ,这个时候就该对数据库进行 水平分区 (sharding,即分库分表 ),将原本一张表维护的海量数据分配给 N 个子表进行存储和维护。
水平分表从具体实现上又可以分为3种:只分表、只分库、分库分表,下图展示了这三种情况: 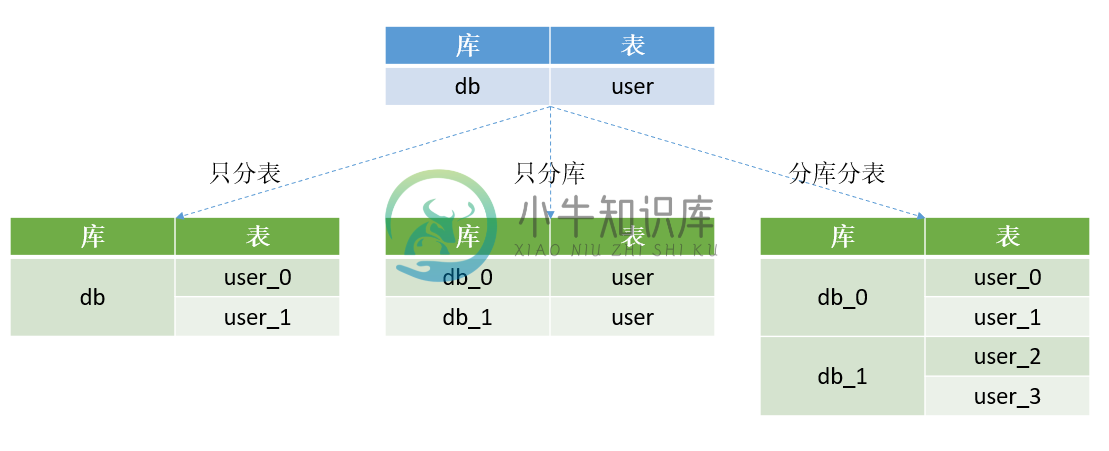
只分表:将db库中的user表拆分为2个分表,user_0和user_1,这两个表还位于同一个库中。
只分库:将db库拆分为db_0和db_1两个库,同时在db_0和db_1库中各自新建一个user表,db_0.user表和db_1.user表中各自只存原来的db.user表中的部分数据。
分库分表:将db库拆分为db_0和db_1两个库,db_0中包含user_0、user_1两个分表,db_1中包含user_2、user_3两个分表。
下图演示了在分库分表的情况下,数据是如何拆分的:假设db库的user表中原来有4000W条数据,现在将db库拆分为2个分库db_0和db_1,user表拆分为user_0、user_1、user_2、user_3四个分表,每个分表存储1000W条数据。 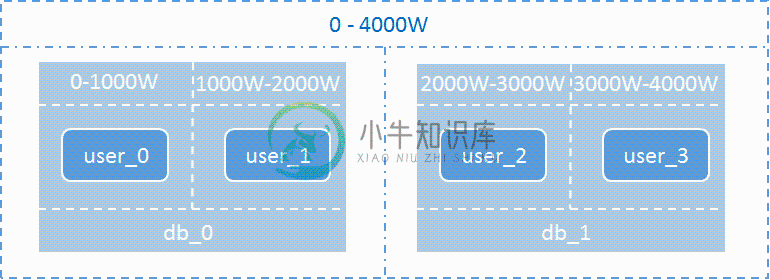
2 分库分表优点
分库的好处: 降低单台机器的负载压力,提升写入性能
分表的好处: 提高数据操作的效率。举个例子说明,比如user表中现在有4000w条数据,此时我们需要在这个表中增加(insert)一条新的数据,insert完毕后,数据库会针对这张表重新建立索引,4000w行数据建立索引的系统开销还是不容忽视的。但是反过来,假如我们将这个表分成4 个table呢,从user_0一直到user_3,4000w行数据平均下来,每个子表里边就只有1000W行数据,这时候我们向一张 只有1000W行数据的table中insert数据后建立索引的时间就会下降,从而提高DB的运行时效率,提高了DB的并发量。除了提高写的效率,更重要的是提高读的效率,提高查询的性能。当然分表的好处还不止这些,还有诸如写操作的锁操作等,都会带来很多显然的好处。
3 Zebra与分库分表
zebra提供了ShardDataSource来完成分库分表功能,主要解决的是分库分表的基本增删改查问题。
关于Zebra分库分表功能设计方式的实现,请参考:主流数据库中间件设计方式
关于分库分表功能接入,请参考:Zebra分库分表接入指南