
Zebra 读写分离接入
GroupDataSource是Zebra提供的读写分离数据源,主要提供主从分离, 就近路由,端到端监控等功能。 如果你还不理解读写分离的概念,请参考Zebra读写分离介绍。
2.准备
2.1远程配置中心接入(zookeeper)
(1)zookeeper配置文件
需要在项目中的src/main/resource目录下面添加zookeeper.properties文件,指定zookeeper的地址
zkserver=localhost:2181
(2)应用名
需要在项目中的src/main/resource目录下面添加app.properties文件,指定应用名
app_name=zebra_ut
(3)就近读取功能的机房配置 在zookeeper中路径 /zebra/zebra-router/region/config下添加center配置(一般一个城市作为一个region, 多个机房组成1个idc),eg.
{
"regions" : [
{"region" : "region1", "centers" : [
{"center":"center1","priority":2, "idcs":[
{"idc" : "idc1", "desc" : "机房1"},
{"idc" : "idc2", "desc" : "机房2"},
{"idc" : "idc3", "desc" : "机房3"}
]},
{"center":"center2","priority":1,"idcs":[
{"idc" : "idc4", "desc" : "机房4"}
]}
]},
{"region" : "region2", "centers" : [
{"center":"center3","priority":1,"idcs":[
{"idc" : "idc5", "desc" : "机房5"},
{"idc" : "idc6", "desc" : "机房6"}
]}
]}
]
}
在zookeeper中路径 /zebra/zebra-router/idc/config 下添加idc(机房一般包含多个网段)的配置, eg.
{
"regions" : [
{"region" : "region1", "idcs" : [
{"idc" : "idc1", "net" : ["192.1", "192.2"], "desc" : "机房1"},
{"idc" : "idc2", "net" : ["192.3", "192.4"], "desc" : "机房2"},
{"idc" : "idc3", "net" : ["192.5"], "desc" : "机房3"},
{"idc" : "idc4", "net" : ["192.6"], "desc" : "机房4"}
]},
{"region" : "region2", "idcs" : [
{"idc" : "idc5", "net" : ["192.10", "192.11"], "desc" : "机房5"},
{"idc" : "idc6", "net" : ["192.20", "192.21"], "desc" : "机房6"}
]}
]
}
(4)以上信息添加完成后,使用zebra的管理平台进行读写分离配置的注册,得到一个jdbcref,参考zebra管理平台使用
(5)配置完成后请跳至下文 3.使用说明 进行后续接入
2.2本地配置接入
(1)应用名
同样需要在项目中的src/main/resource目录下面添加app.properties文件,指定应用名
app_name=zebra_ut
(2) 机房信息 机房信息配置在本地文件中, 在src/main/resource目录下创建region目录,其中包含2个文件:center.json和idc.json
center.json
{
"regions" : [
{"region" : "region1", "centers" : [
{"center":"center1","priority":2, "idcs":[
{"idc" : "idc1", "desc" : "机房1"},
{"idc" : "idc2", "desc" : "机房2"},
{"idc" : "idc3", "desc" : "机房3"}
]},
{"center":"center2","priority":1,"idcs":[
{"idc" : "idc4", "desc" : "机房4"}
]}
]},
{"region" : "region2", "centers" : [
{"center":"center3","priority":1,"idcs":[
{"idc" : "idc5", "desc" : "机房5"},
{"idc" : "idc6", "desc" : "机房6"}
]}
]}
]
}
idc.json
{
"regions" : [
{"region" : "region1", "idcs" : [
{"idc" : "idc1", "net" : ["192.1", "192.2"], "desc" : "机房1"},
{"idc" : "idc2", "net" : ["192.3", "192.4"], "desc" : "机房2"},
{"idc" : "idc3", "net" : ["192.5"], "desc" : "机房3"},
{"idc" : "idc4", "net" : ["192.6"], "desc" : "机房4"}
]},
{"region" : "region2", "idcs" : [
{"idc" : "idc5", "net" : ["192.10", "192.11"], "desc" : "机房5"},
{"idc" : "idc6", "net" : ["192.20", "192.21"], "desc" : "机房6"}
]}
]
}
(3)机房信息创建完成后,开始进行ds的配置
在src/main/resources目录下创建数据库的配置文件(zebra抽象为jdbcRef,并根据jdbcref找到数据库相关配置,访问数据库),文件名必须以jdbcRef.properties格式命名,例如jdbcRef="sample",那么创建sample.properties配置文件
zebra.group.sample=<groupConfig>\
<singleConfig>\
<name>sample-n1</name>\
<writeWeight>0</writeWeight>\
<readWeight>-1</readWeight>\
</singleConfig>\
<singleConfig>\
<name>sample-n2</name>\
<writeWeight>-1</writeWeight>\
<readWeight>1</readWeight>\
</singleConfig>\
</groupConfig>
zebra.ds.sample-n1=<dsConfig>\
<url>jdbc:mysql://127.0.0.1:3306/sample?characterEncoding=UTF8&socketTimeout=60000</url>\
<driverClass>com.mysql.jdbc.Driver</driverClass>\
<active>true</active>\
<username>root</username>\
<properties>idleConnectionTestPeriod=80&acquireRetryAttempts=50&acquireRetryDelay=300&maxStatements=1</properties>\
<password>123456</password>\
</dsConfig>
zebra.ds.sample-n2=<dsConfig>\
<url>jdbc:mysql://127.0.0.1:3306/sample?characterEncoding=UTF8&socketTimeout=60000</url>\
<driverClass>com.mysql.jdbc.Driver</driverClass>\
<active>true</active>\
<username>root</username>\
<properties>idleConnectionTestPeriod=80&acquireRetryAttempts=50&acquireRetryDelay=300&maxStatements=1</properties>\
<password>123456</password>\
</dsConfig>
(4)以上配置完成后,进入下文使用说明
特别注意: 使用本地的配置时,GroupDataSource的configManagerType配置需要设置为local
3.使用说明
3.1 第一步:添加依赖
版本选择请参考Zebra版本更新记录,并配合数据监控组件zebra-cat-client一起使用
<dependency>
<!--核心依赖:数据源-->
<groupId>com.dianping.zebra</groupId>
<artifactId>zebra-client</artifactId>
<version>${version}</version>
</dependency>
<dependency>
<!--可选依赖:cat监控-->
<groupId>com.dianping.zebra</groupId>
<artifactId>zebra-cat-client</artifactId>
<version>${version}</version>
</dependency>
3.2 第二步:添加连接池配置
zebra目前支持的数据源有c3p0,tomcat-jdbc,druid,hikaricp, dbcp和dbcp2。zebra使用的配置是基于c3p0的,zebra会自动把c3p0的连接池配置转化成其他类型的连接池配置,对于不能转的配置,zebra会自动给默认值。
基本参数
<bean id="dataSource" class="com.dianping.zebra.group.jdbc.GroupDataSource" init-method="init" destroy-method="close">
<!-- 必配。指定唯一确定数据库的key-->
<property name="jdbcRef" value="sample" />
<!-- 选配。指定底层使用的连接池类型,支持"c3p0","tomcat-jdbc","druid","hikaricp","dbcp2"和"dbcp",推荐使用"druid"或者"dbcp2" -->
<property name="configManagerType" value="zookeeper" />
<property name="poolType" value="hikaricp" />
<!-- 选配。指定连接池的最小连接数,默认值是5。 -->
<property name="minPoolSize" value="5" />
<!-- 选配。指定连接池的最大连接数,默认值是20。 -->
<property name="maxPoolSize" value="20" />
<!-- 选配。指定连接池的初始化连接数,默认值是5。 -->
<property name="initialPoolSize" value="5" />
<!-- 选配。指定连接池的获取连接的超时时间,默认值是1000。 -->
<property name="checkoutTimeout" value="1000" />
</bean>
全部参数列表
很多时候,zebra提供的默认连接池参数对业务已经足够使用了,但如果不能够覆盖业务的特殊场景,也能够支持业务按照需要定制底层连接池参数,具体请参考:Zebra读写分离属性列表
代码中直接使用Zebra
如果业务不是在Spring环境中使用zebra的,也可以通过以下代码进行初始化
GroupDataSource dataSource = new GroupDataSource("sample");
//Set other datasource properties if you want
dataSource.init();
//Now dataSource is ready for use
Connection conn = dataSource.getConnection();
//Must destory datasource if not use
dataSource.close();
SpringBoot接入Zebra
本案例介绍:springboot 1.5.9、zebra-client 2.9.1、zebra-dao 0.2.1如何进行整合。
注意:业界ORM框架mybatis提供了mybatis-spring-boot-starter,以便于mybatis与springboot的整合。由于zebra-dao对mybatis进行了封装,这个starter已经无法起作用,因此这里并不使用。
项目目录结构如下所示: 
pom.xml核心依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>com.dianping.zebra</groupId>
<artifactId>zebra-client</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>com.dianping.zebra</groupId>
<artifactId>zebra-cat-client</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>com.dianping.zebra</groupId>
<artifactId>zebra-dao</artifactId>
<version>0.2.1</version>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<!--Import dependency management from SpringBoot-->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>1.5.9.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
DataSourceConfig.java
@Configuration
public class DataSourceConfig {
private String jdbcref="your_jdbcref_from_dba";
@Bean
public DataSource zebraDataSource() {
GroupDataSource groupDataSource = new GroupDataSource(jdbcref);
groupDataSource.init();
return groupDataSource;
}
@Bean(name="sqlSessionFactory")
public SqlSessionFactoryBean sqlSessionFactory(DataSource dataSource) throws IOException {
SqlSessionFactoryBean ssfb = new SqlSessionFactoryBean();
ssfb.setDataSource(dataSource);
//如果你是将sql写在映射xml文件中,那么需要通过以下方式指定xml文件路径;本案例是直接通过注解来编写sql,因此不需要使用以下配置。
//PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
//ssfb.setMapperLocations(resolver.getResources("classpath*:config/sqlmap/**/*.xml"));
return ssfb;
}
@Bean
public ZebraMapperScannerConfigurer mapperScannerConfigurer() throws IOException {
ZebraMapperScannerConfigurer configurer = new ZebraMapperScannerConfigurer();
configurer.setSqlSessionFactoryBeanName("sqlSessionFactory");
//mapper接口所在包名
configurer.setBasePackage("com.dianping.zebra.springboot.mapper");
return configurer;
}
}
UserMapper.java
public interface UserMapper {
@Select("SELECT * FROM `User` where id = #{userId}")
public UserEntity findUserById(@Param("userId") int userId);
}
UserEntity.java
public class UserEntity {
private int id;
private String name;
private String tel;
private String email;
private String alias;
private int role;
private Date updateTime;
//setters and getters
}
Application.java
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}
SpringBootTest.java
@RunWith(SpringJUnit4ClassRunner. class)
@SpringBootTest(classes = Application.class)
public class ZebraSpringbootTest {
@Autowired
private UserMapper userMapper;
@Test
public void test(){
UserEntity user = userMapper.findUserById(1);
System.out.println(user);
}
}
运行程序之后,控制台输出user内容,则表示成功
注意事项
1.jdbcurl参数
如果需要额外的参数比如zeroDateTimeBehavior=convertToNull或者其他参数,可以通过以下方式修改"extraJdbcUrlParams"参数进行设置或者甚至是覆盖;
如果有大事务或者大查询会超过60s的,请也覆盖掉socketTimeout=60000这个参数。
<bean id="dataSource" class="com.dianping.zebra.group.jdbc.GroupDataSource" init-method="init" destroy-method="close">
<!--添加额外的jdbc url的参数,已param1=value1&m2=value2的方式注入-->
<property name="extraJdbcUrlParams" value="param1=value1&param2=value2" />
</bean>
配置方法参见: zebra读写分离属性列表 中搜索 “extraJdbcUrlParams” 部分内容。
2.utf8mb4支持
A1: 检查连接mysql的版本 如果是mysql5.7或mysqlserver的collation_server为utf8_general_ci, 将mysql-connector-java升级到5.1.33及以上版本后可以直接支持。
A2: 一般情况下,用户在使用这个参数时,都是设置编码方式:"set names utf8mb4"。
要求mysql-connector-java要在5.1.20以上。poolType不能是c3p0,其他的类型都能支持。 推荐使用最新版本。
其他功能说明
1.强制走主从库
Zebra的GroupDataSource是一个读写分离的数据源,根据业务场景有时会有sql强制走(主/从)库的需求。
Zebra提供了不同粒度的强制走主库及数据源粒度的强制走从库逻辑。
强制走主库逻辑优先级: 整个数据源走主库 > 事务 = SQL Hint > api方式
- 事务:在事务中的所有操作均会路由到主库进行操作。
- 单个SQL走主库:使用SQL Hint的方式,SQL前加入Zebra的强制走主Hint /+zebra:w/, 使用后该SQL会强制路由到主库
或者/*+zebra:w*/select * from test/*master*/select * from test - 单次请求所有SQL走主库:使用Zebra提供的一套API 从调用API到清理标记过程中的所有SQL均会走主库 ``` /**
- 使用本地的context来设置走主库,该方式只会影响本应用内本次请求的所有sql走主库,不会影响到pigeon后端服务。
- 调用过该方法后,一定要在请求的末尾调用clearLocalContext进行清理操作。
- 优先级比forceMasterInPiegonContext低。
/ ZebraForceMasterHelper.forceMasterInLocalContext(); xxxDao.insert(); xxxDao.select(); /* - 配合forceMasterInLocalContext进行使用,在请求的末尾调用该方法,对LocalContext进行清理。
*/ ZebraForceMasterHelper.clearLocalContext(); ``` - 整个数据源走主库:一般情况下,除非对主从延迟要求很高,一般应用不建议使用该配置
<bean id="writeDs" class="com.dianping.zebra.group.jdbc.GroupDataSource" init-method="init"> <property name="jdbcRef" value="testjdbcref" /> <property name="routerType" value="master-only" /> </bean> - 整个数据源走从库:
2.路由策略<bean id="writeDs" class="com.dianping.zebra.group.jdbc.GroupDataSource" init-method="init"> <property name="jdbcRef" value="testjdbcref" /> <property name="routerType" value="slave-only" /> </bean>
为了满足高可用的需求,mysql集群和业务服务器集群一般需要进行多机房/多中心部署,为此会产生跨机房/中心访问的问题。 为了平衡跨机房/中心访问带来的延迟问题,需要应用机器能够优先访问部署在同一机房/中心的DB。
示意图如下 这是一个同中心就近读取的例子: 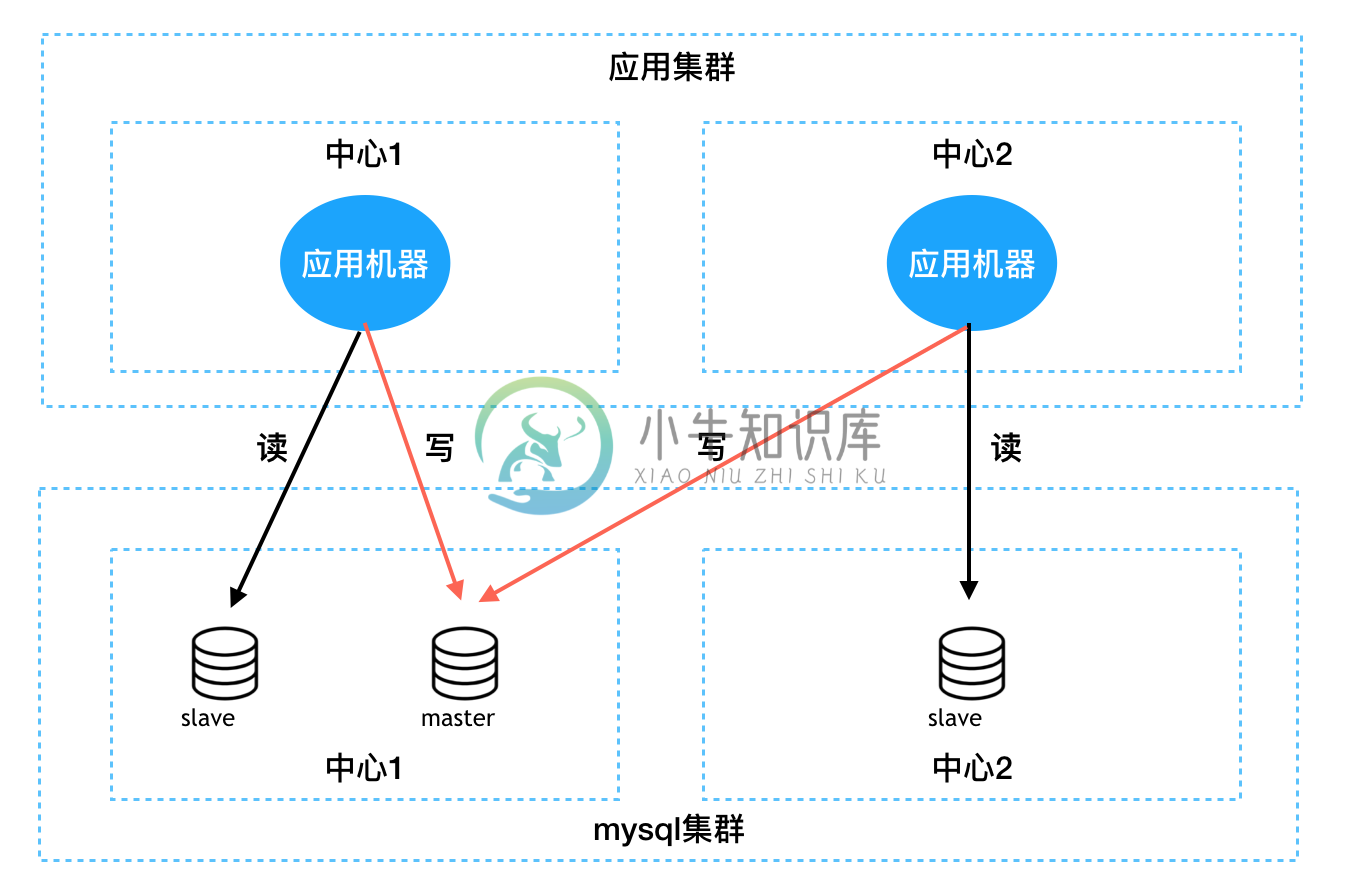
zebra目前提供3种粒度的就行读取策略
- 同机房优先:应用访问DB时会优先选择同一个机房内的DB,适合同机房内部署DB并且对网络延时高的应用。
- 同中心优先:应用访问DB时会优先选择同一个中心内的DB,适合同中心内部署DB并且对网络延时较高的应用。(中心由1个机房或多个机房组成)
- 同地域优先:应用访问DB时会优先选择同一个地域内的DB
这里需要解释一下,这里的读库并不一定是真的读库,而是数据库配置中配置有读流量的库,这个流量也可能在主库上
3.3 第三步:添加监控配置
CAT需要的配置有:在Java项目的src/main/resources/META-INF目录下,新建一个文件app.properties,该文件的内容就只有一行:app.name=${appkey}。
接入了CAT监控后,就可以查看SQL的性能等指标。