
Zebra 流量控制
1 背景
在系统访问量较大时,某些库的负载可能非常高,或者因为临时故障或系统bug导致大量异常SQL打到某个库上。为了防止数据库被这些异常流量打垮,需要在数据库访问层上对MySQL进行保护,因此zebra需要提供对某些特定SQL或某个库进行限流的功能。(SQL限流只是用于临时解决问题,事后还需业务方进行优化或扩容)
2 目标
- 动态限流,可动态配置限流策略与流量大小
- 支持限制某个数据源上的某些特定的SQL(sqlId)或者某些类型的SQL
- 支持对事务的限流优化(特定条件下生效)
3 架构
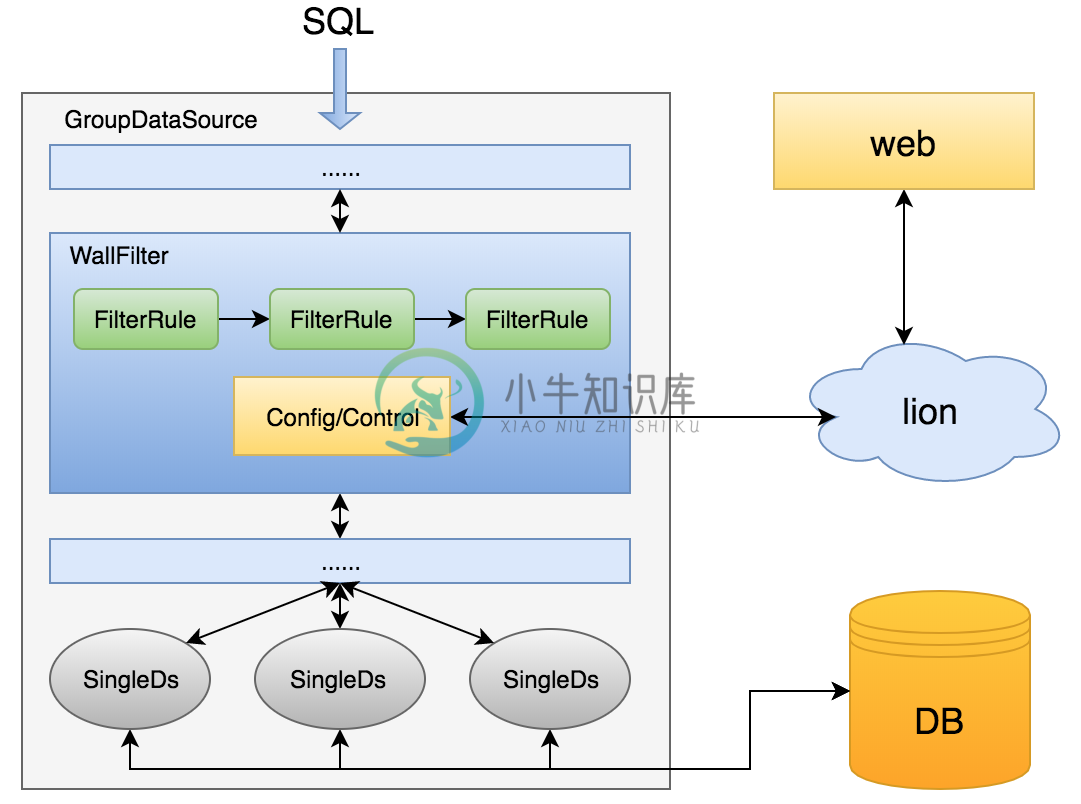

zebra提供按照sqlId限制某些特定SQL或者限制某种类型的SQL两种限流方式,并且可动态配置。
应用在启动时或策略变更后,解析并根据与本机有关的配置修改filter。在限流开启后,要执行的SQL依次通过多个rule,如果某条SQL被判断为需要限制,则进行拦截并向上层服务抛出异常。
4 配置
zebra-flow.jdbcref.config
{
"rules": [
{
"enable": false, // 规则是否有效
"type": "SqlId", // 规则是否有效
"config": {
"id1": 10, // 某个sqlId及对应允许通过的百分比
"id2": 20
},
"dbIp": "10.1.2.3", // 要限制的数据库ip
"appIp": "10.72.*,10.73.*" // 要限制的应用ip
},
{
"enable": false,
"type": "AutoControl",
"config": {
"strategy": "Connection", // 通过连接请求失败率来进行限流(暂时不需配)
"threshold": 10, // 失败率超过百分之十是开始限流
"floor": 50, // 流量下限是百分之五十
"reduce": "linear:5/fast", // 流量限制策略
"recovery": "linear:5/exponential:2", // 流量恢复策略
"window":60, // 统计时间窗口(选配,默认60s,最大300s)
"total":100 // 窗口内请求总量>=total且失败率 >=threshold时限流生效(选配,默认100个)
},
"dbIp": "10.1.2.3",
"appIp": "10.72.*,10.73.*"
},
{
"enable": false,
"type": "ForceControl",
"config": {
"floor": 50 // 流量下限百分比(针对连接,开启后会直接降到 floor,优先级高于AutoControl)
},
"dbIp": "10.1.2.3",
"appIp": "10.72.*,10.73.*"
}
]
}
限流配置为JdbcRef级别,zebra启动时会在WallFilter内记录应用中所有的JdbcRef,并初始化配置,配置可动态修改。
- rules:可以配置多个限流规则,每个可以针对sqlId或全部限流
- enable:JdbcRef限流规则的开关
- type: 限流规则类型,SqlId指限制特定Id的SQL,AutoControl指失败率达到阈值后自动限流,ForceControl指强行限流
- config: 对应限流策略的具体配置
- dbIp: 要限流的实例Ip(可以配置多个;"xx.xx."表示以xx.xx开头的实例;""表示所有实例)
- appIp: 在某些机器上开启限流(可以配置多个;"xx.xx."表示以xx.xx开头的机器;""表示所有机器)
5 按SqlId限流
SqlId的计算规则:
sqlId = MD5(/*appName*/sqlName).subString(0, 8)
其中appName为应用名;sqlName指的是Mybatis中每一个mapper方法名。通过以上的算法,会给应用中的每一个SQL都生成一个8位的ID。

在接入了zebra-dao后,zebra可以给通过PreparedStatement执行的SQL算出一个唯一的ID,这个ID会拼接到每个SQL的前面一起发往数据库。一旦数据库发生故障,DBA可以抓取到这个SQL的ID,那么就可以根据这个ID进行流量控制了。
在管理端上进行配置后,lion会将配置推送到监听了该配置的客户端上。WallFilter收到配置后首先会检查限流是否开启且是否是本机Ip需要限流,然后根据配置创建过滤规则。在processSQL中计算每条SQL的Id,发现可以匹配时,利用随机数根据设定的流量比例进行控制,被拒绝的SQL会向上层服务配SQLException。
注意:根据SqlId限流时无法针对事务进行优化。
6 自动限流
开启自动限流策略后,zebra会维护一个时间窗口(窗口大小默认60s,可通过配置修改),统计过去一段时间内的状态,统计指标包括:
- 失败连接请求数:滑动窗口内,拿连接失败的请求数
- 总连接请求数:滑动窗口内,一共请求拿了多少次连接(总请求中不包括被限流的连接)
在滑动窗口内,失败率=失败连接请求数/总连接请求数,当失败率超过阈值时便触发自动限流,限制请求拿连接池中的连接。
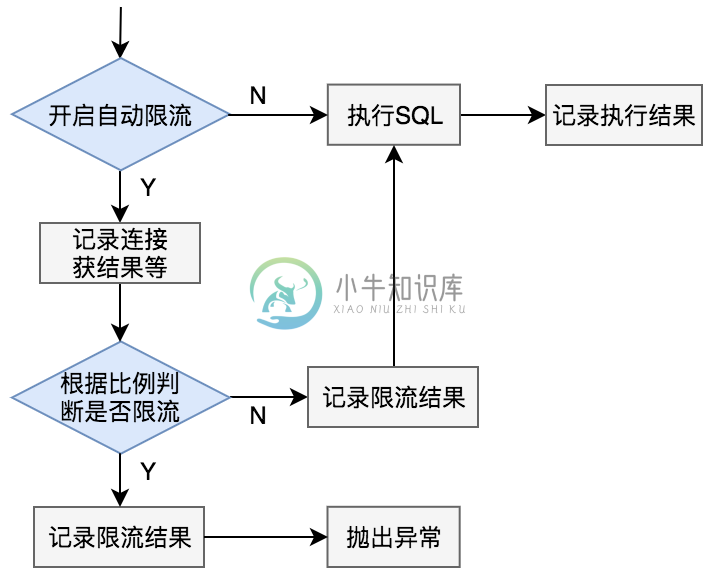
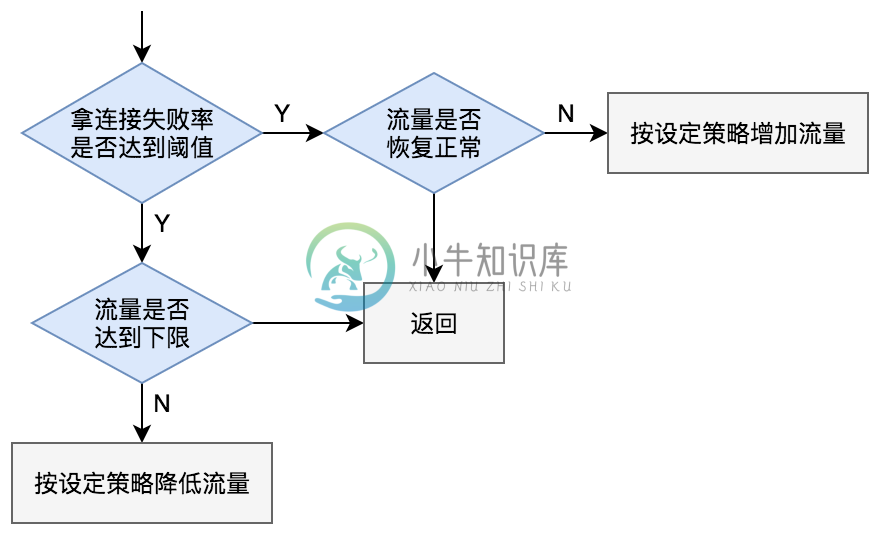
在自动限流触发后,如果失败率超过阈值,zebra需要减小流量,默认为每秒降指定比例的线性策略;当检测到失败率低于阈值时,开始恢复流量,默认也是线性恢复。
流量限制策略(参考上面配置,参数需要具体测试后再调整):
1.linear:n或linear:n,t 例如linear:5表示每秒减少5%的流量,直到达到下限,linear:5,2表示每2秒减少5%的流 量,时间间隔为2s
2.fast 表示出现问题后立即降低到下限,然后失败率小于阈值后再逐步恢复
流量恢复策略:
1.linear:n或linear:n,t 如linear:5表示在失败率小于阈值的时候,每秒增加5%的流量,直到达到完全恢复
2.exponential:n或exponential:n,t 表示以指数的形式恢复,exponential:3第一秒恢复3%的流量,第二秒6%,第三秒12%等等
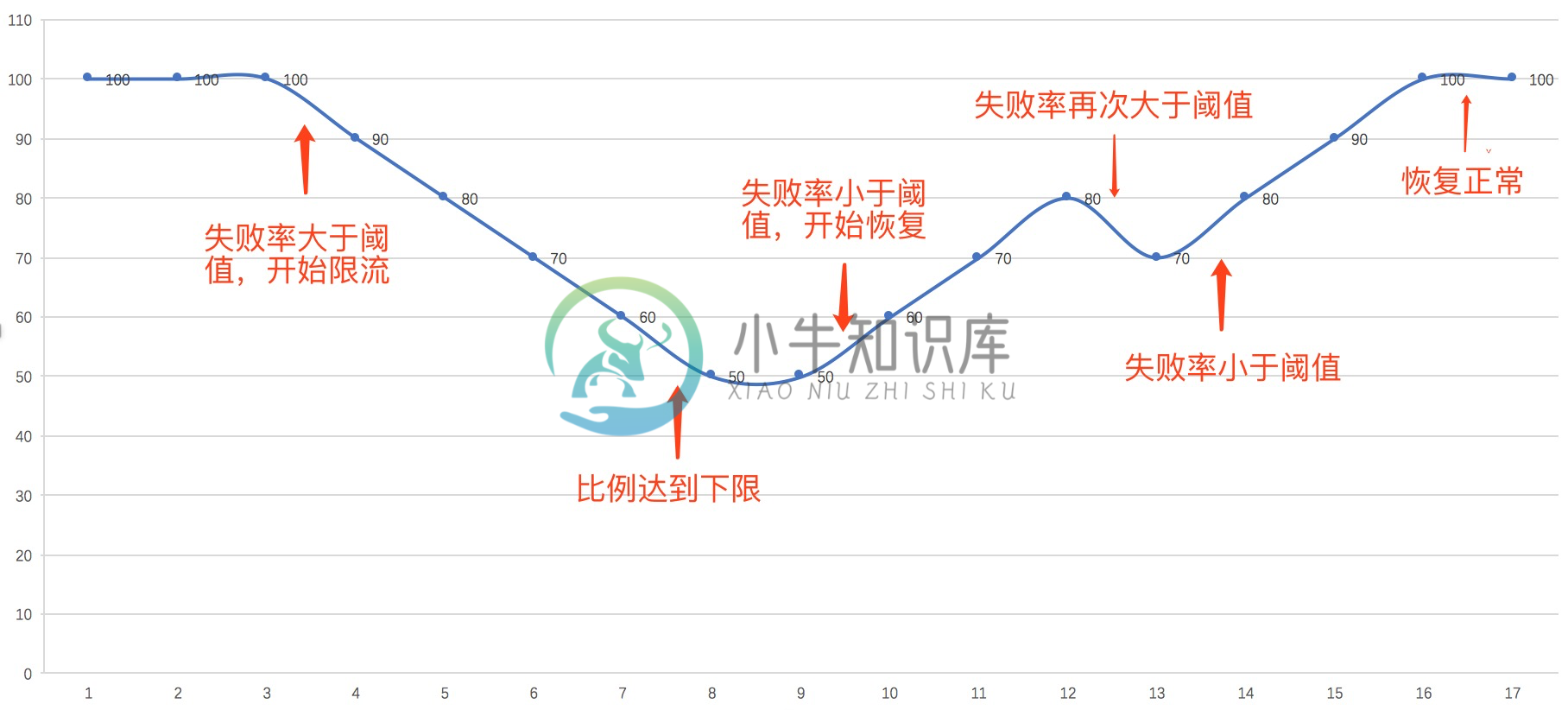
eg.
以流量降低和恢复都是线性策略为例简单介绍下限流及恢复过程,下图中横轴表示时间,纵轴表示允许通过的连接请求比例。
在t=3时开始出现问题,失败率大于阈值,开始限制连接请求,按每秒百分之十的比例降低;在t=8达到设置的下限后不再继续下降;t=9时,失败率小于阈值,开始逐步恢复;t=12时,恢复到百分之八十,这时再次出现失败率大于阈值的情况,继续执行限流;t=13后开始恢复,t=16之后恢复正常。
7 强制限流

开启强制限流后,会对所有连接进行过滤,立即将流量降到下限。需要手动开启,用于在紧急情况下对流量进行快速限流,恢复正常后需要手动关闭(优先级大于自动限流)。