
python实现mysql的读写分离及负载均衡

Oracle数据库有其公司开发的配套rac来实现负载均衡,目前已知的最大节点数能到128个,但是其带来的维护成本无疑是很高的,并且rac的稳定性也并不是特别理想,尤其是节点很多的时候。
但是,相对mysql来说,rac的实用性要比mysql的配套集群软件mysql-cluster要高很多。因为从网上了解到情况来看,很少公司在使用mysql-cluster,大多数企业都会选择第三方代理软件,例如MySQL Proxy、Mycat、haproxy等,但是这会引起另外一个问题:单点故障(包括mysql-cluster:管理节点)。如果要解决这个问题,就需要给代理软件html" target="_blank">搭建集群,在访问量很大的情况下,代理软件的双机或三机集群会成为访问瓶颈,继续增加其节点数,无疑会带来各方面的成本。
那么,如何可以解决这个问题呢?
解决上述问题,最好的方式个人认为应该是在程序中实现。通过和其他mysql DBA的沟通,也证实了这个想法。但是由此带来的疑问也就产生了:会不会增加开发成本?对现有的应用系统做修改会不会改动很大?会不会增加后期版本升级的难度?等等。
对于一个架构设计良好的应用系统可以很肯定的回答:不会。
那么怎么算一个架构设计良好的应用系统呢?
简单来说,就是分层合理、功能模块之间耦合性底。以本人的经验来说,系统设计基本上可以划分为以下四层:
1. 实体层:主要定义一些实体类
2. 数据层:也可以叫SQL处理层。主要负责跟数据库交互取得数据
3. 业务处:主要是根据业务流程及功能区分模块(或者说定义不同的业务类)
4. 表现层:呈现最终结果给用户
实现上述功能(mysql的读写分离及负载均衡),在这四个层次中,仅仅涉及到数据层。
严格来说,对于设计良好的系统,只涉及到一个类的一个函数:在数据层中,一般都会单独划分出一个连接类,并且这个连接类中会有一个连接函数,需要改动的就是这个函数:在读取连接字符串之前加一个功能函数返回需要的主机、ip、端口号等信息(没有开发经历的同学可能理解这段话有点费劲)。
流程图如下:
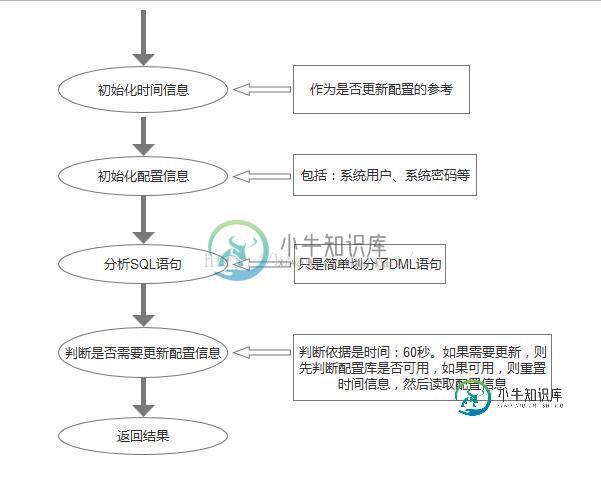
代码如下:
import mmap
import json
import random
import mysql.connector
import time
##公有变量
#dbinfos={
# "db0":{'host':'192.168.42.60','user':'root','pwd':'Abcd1234','my_user':'root','my_pwd':'Abcd.1234',"port":3306,"database":"","role":"RW","weight":10,"status":1},
# "db1":{'host':'192.168.42.61','user':'root','pwd':'Abcd1234','my_user':'root','my_pwd':'Abcd.1234',"port":3306,,"database":"":"R","weight":20,"status":1}
# }
dbinfos={}
mmap_file = None
mmap_time=None
##这个函数返回json格式的字符串,也是实现初始化数据库信息的地方
##使用json格式是为了方便数据转换,从字符串---》二进制--》字符串---》字典
##如果采用其它方式共享dbinfos的方法,可以不用此方式
##配置库的地址
def get_json_str1():
return json.dumps(dbinfos)
##读取配置库中的内容
def get_json_str():
try:
global dbinfos
cnx = mysql.connector.connect(user='root', password='Abcd.1234',
host='192.168.42.60',
database='rwlb')
cursor = cnx.cursor()
cmdString="select * from rwlb"
cnt=-1
cursor.execute(cmdString)
for (host,user,pwd,my_user,my_pwd,role,weight,status,port,db ) in cursor:
cnt=cnt+1
dict_db={'host':host,'user':user,'pwd':pwd,'my_user':my_user,'my_pwd':my_pwd,"port":port,"database":db,"role":role,"weight":weight,"status":status}
dbinfos["db"+str(cnt)]=dict_db
cursor.close()
cnx.close()
return json.dumps(dbinfos)
except:
cursor.close()
cnx.close()
return ""
##判断是否能正常连接到数据库
def check_conn_host():
try:
cnx = mysql.connector.connect(user='root', password='Abcd.1234',
host='192.168.42.60',
database='rwlb')
cursor = cnx.cursor()
cmdString="select user()"
cnt=-1
cursor.execute(cmdString)
for user in cursor:
cnt=len(user)
cursor.close()
cnx.close()
return cnt
except :
return -1;
##select 属于读操作,其他属于写操作-----这里可以划分的更详细,比如执行存储过程等
def analyze_sql_state(sql):
if "select" in sql:
return "R"
else:
return "W"
##读取时间信息
def read_mmap_time():
global mmap_time,mmap_file
mmap_time.seek(0)
##初始时间
inittime=int(mmap_time.read().translate(None, b'\x00').decode())
##当前时间
endtime=int(time.time())
##时间差
dis_time=endtime-inittime
print("dis_time:"+str(dis_time))
#重新读取数据
if dis_time>10:
##当配置库正常的情况下才重新读取数据
print(str(check_conn_host()))
if check_conn_host()>0:
print("read data again")
mmap_time.seek(0)
mmap_file.seek(0)
mmap_time.write(b'\x00')
mmap_file.write(b'\x00')
get_mmap_time()
get_mmap_info()
else:
print("can not connect to host")
#不重新读取数据
else:
print("do not read data again")
##从内存中读取信息,
def read_mmap_info(sql):
read_mmap_time()
print("The data is in memory")
global mmap_file,dict_db
mmap_file.seek(0)
##把二进制转换为字符串
info_str=mmap_file.read().translate(None, b'\x00').decode()
#3把字符串转成json格式,方便后面转换为字典使用
infos=json.loads(info_str)
host_count=len(infos)
##权重列表
listw=[]
##总的权重数量
wtotal=0
##数据库角色
dbrole=analyze_sql_state(sql)
##根据权重初始化一个列表。这个是比较简单的算法,所以权重和控制在100以内比较好----这里可以选择其他比较好的算法
for i in range(host_count):
db="db"+str(i)
if dbrole in infos[db]["role"]:
if int(infos[db]["status"])==1:
w=infos[db]["weight"]
wtotal=wtotal+w
for j in range(w):
listw.append(i)
if wtotal >0:
##产生一个随机数
rad=random.randint(0,wtotal-1)
##读取随机数所在的列表位置的数据
dbindex=listw[rad]
##确定选择的是哪个db
db="db"+str(dbindex)
##为dict_db赋值,即选取的db的信息
dict_db=infos[db]
return dict_db
else :
return {}
##如果内存中没有时间信息,则向内存红写入时间信息
def get_mmap_time():
global mmap_time
##第二个参数1024是设定的内存大小,单位:字节。如果内容较多,可以调大一点
mmap_time = mmap.mmap(-1, 1024, access = mmap.ACCESS_WRITE, tagname = 'share_time')
##读取有效比特数,不包括空比特
cnt=mmap_time.read_byte()
if cnt==0:
print("Load time to memory")
mmap_time = mmap.mmap(0, 1024, access = mmap.ACCESS_WRITE, tagname = 'share_time')
inittime=str(int(time.time()))
mmap_time.write(inittime.encode())
##如果内存中没有对应信息,则向内存中写信息以供下次调用使用
def get_mmap_info():
global mmap_file
##第二个参数1024是设定的内存大小,单位:字节。如果内容较多,可以调大一点
mmap_file = mmap.mmap(-1, 1024, access = mmap.ACCESS_WRITE, tagname = 'share_mmap')
##读取有效比特数,不包括空比特
cnt=mmap_file.read_byte()
if cnt==0:
print("Load data to memory")
mmap_file = mmap.mmap(0, 1024, access = mmap.ACCESS_WRITE, tagname = 'share_mmap')
mmap_file.write(get_json_str().encode())
##测试函数
def test1():
get_mmap_time()
get_mmap_info()
for i in range(10):
sql="select * from db"
#sql="update t set col1=a where b=2"
dbrole=analyze_sql_state(sql)
dict_db=read_mmap_info(sql)
print(dict_db["host"])
def test2():
sql="select * from db"
res=analyze_sql_state(sql)
print("select:"+res)
sql="update t set col1=a where b=2"
res=analyze_sql_state(sql)
print("update:"+res)
sql="insert into t values(1,2)"
res=analyze_sql_state(sql)
print("insert:"+res)
sql="delete from t where b=2"
res=analyze_sql_state(sql)
print("delete:"+res)
##类似主函数
if __name__=="__main__":
test2()
测试结果:

从结果可以看出,只有第一次向内存加载数据,并且按照权重实现了负载均衡。
因为测试函数test1()写的是固定语句,所以读写分离的结果没有显示出来。
另外:测试使用的数据库表结构及数据:
desc rwlb; +---------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+-------------+------+-----+---------+-------+ | host | varchar(50) | YES | | NULL | | | user | varchar(50) | YES | | NULL | | | pwd | varchar(50) | YES | | NULL | | | my_user | varchar(50) | YES | | NULL | | | my_pwd | varchar(50) | YES | | NULL | | | role | varchar(10) | YES | | NULL | | | weight | int(11) | YES | | NULL | | | status | int(11) | YES | | NULL | | | port | int(11) | YES | | NULL | | | db | varchar(50) | YES | | NULL | | +---------+-------------+------+-----+---------+-------+ select * from rwlb; +---------------+------+----------+---------+-----------+------+--------+--------+------+------+ | host | user | pwd | my_user | my_pwd | role | weight | status | port | db | +---------------+------+----------+---------+-----------+------+--------+--------+------+------+ | 192.168.42.60 | root | Abcd1234 | root | Abcd.1234 | RW | 10 | 1 | NULL | NULL | | 192.168.42.61 | root | Abcd1234 | root | Abcd.1234 | R | 20 | 1 | NULL | NULL | +---------------+------+----------+---------+-----------+------+--------+--------+------+------+
总结
以上所述是小编给大家介绍的python实现mysql的读写分离及负载均衡,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
-
本文向大家介绍在OneProxy的基础上实行MySQL读写分离与负载均衡,包括了在OneProxy的基础上实行MySQL读写分离与负载均衡的使用技巧和注意事项,需要的朋友参考一下 简介 Part1:写在最前 OneProxy平民软件完全自主开发的分布式数据访问层,帮助用户在MySQL/PostgreSQL集群上快速搭建支持分库分表的分布式数据库中间件,也是一款具有SQL白名单(防SQL注入
-
本文向大家介绍Nginx与Tomcat实现动静态分离和负载均衡,包括了Nginx与Tomcat实现动静态分离和负载均衡的使用技巧和注意事项,需要的朋友参考一下 本文介绍了Nginx与Tomcat实现动静态分离和负载均衡,所谓动静分离就是通过nginx(或apache等)来处理用户端请求的图片、html等静态的文件,tomcat(或weblogic)处理jsp、do等动态文件,从而达到动静页面访问时
-
本文向大家介绍springboot基于Mybatis mysql实现读写分离,包括了springboot基于Mybatis mysql实现读写分离的使用技巧和注意事项,需要的朋友参考一下 近日工作任务较轻,有空学习学习技术,遂来研究如果实现读写分离。这里用博客记录下过程,一方面可备日后查看,同时也能分享给大家(网上的资料真的大都是抄来抄去,,还不带格式的,看的真心难受)。 完整代码:https:/
-
本文向大家介绍Nginx+Tomcat实现负载均衡、动静分离的原理解析,包括了Nginx+Tomcat实现负载均衡、动静分离的原理解析的使用技巧和注意事项,需要的朋友参考一下 一、Nginx 负载均衡实现原理 1、Nginx 实现负载均衡是通过反向代理实现 反向代理(Reverse Proxy) 是指以 代理服务器(例:Nginx) 来接受 internet 上的连接请求,然后将请求转发给内部网络
-
本文向大家介绍PHP实现的mysql读写分离操作示例,包括了PHP实现的mysql读写分离操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP实现的mysql读写分离操作。分享给大家供大家参考,具体如下: 首先mysql主从需配置好,基本原理就是判断sql语句是否是select,是的话走master库,否则从slave查 结果: I am using master db.. 19
-
前言 我们都知道当单库系统遇到性能瓶颈时,读写分离是首要优化手段之一。因为绝大多数系统读的比例远高于写的比例,并且大量耗时的读操作容易引起锁表导致无发写入数据,这时读写分离就更加重要了。 EF Core如何通过代码实现读写分离,我们可以搜索到很多案例。总结起来一种方法是注册一个DbContextFactory,读操作注入ReadDcontext,写操作注入WriteDbcontext;另外一种是动