《万得》专题
-
Spring Boot-通过JPQL UPDATE查询批量更新数十万个对象?
我正在使用具有HiberNate的Spring Boot1.5.2。 我有一个对象列表。每个对象都包含许多属性和@OneTo许多关系(即从数据库中获取此对象并将此对象更新到数据库需要很长时间)。 这就是我使用自定义 JPQL 查询的原因: 一个用于加载对象列表的基本属性 一个用于更新对象所需的属性 我从CrudRepository扩展了这个方法,用于获取对象列表(只有所需的属性) 现在,我想通过以
-
以很小的内存占用执行数百万个可运行的
我有N个愿望是ID。对于每一个ID,我都需要执行一个Runnable(即,我不关心返回值),并等待它们全部完成。每个Runnable的运行时间从几秒到几分钟不等,并行运行大约100个线程是安全的。 在我们当前的解决方案中,我们使用Executors.NewFixedThreadPool(),对每个ID调用submit(),然后对每个返回的Future调用get()。 代码工作得很好,而且非常简单,
-
 UI设计师1分钟学会的大厂面试万能公式
UI设计师1分钟学会的大厂面试万能公式面试必会问到的问题: 请描述一下你的重点项目经历? 我们可根据STAR法则进行以下3个步骤的描述 (S-situation情景、T-task任务、A-action行动、R-结果 ) 句式一: 这是XX背景下的XX项目,我的任务是xx,我通过xx,实现和推动了xxx。 句式二: 目前产品/行业的现状是XXX,业务的目标是XXX,我们因此推导出设计目标是XXX,根据设计目标又可以推导出我的设计策略是X
-
 万集科技苏州研究院算法工程师一面感受
万集科技苏州研究院算法工程师一面感受我是同学介绍了解到万集科技苏州研究院的,7月9号投的简历,7月14号HR就通知我面试,面试时间是下午5点。面试官人非常好,主要问我做了哪些项目,然后问了一些3D点云中常见的算法,同时问了一些在做项目过程遇到的一些困难,整体面试体验非常好。然后我问了HR大哥有没有通过一面,大哥和我说通过一面了。目前在等待二面,希望可以顺利通过二面,拿到offer进入万集科技苏州研究院。
-
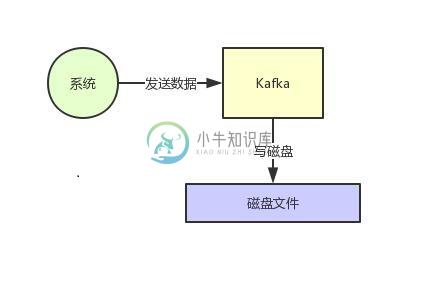 字节面试题: 如何让一个MQ抗住几十万并发?
字节面试题: 如何让一个MQ抗住几十万并发?主要内容:1、页缓存技术 + 磁盘顺序写,2、零拷贝技术,3、最后的总结这篇文章来聊一下Kafka的一些架构设计原理,这也是互联网公司面试时非常高频的技术考点。 Kafka是高吞吐低延迟的高并发、高性能的消息中间件,在大数据领域有极为广泛的运用。配置良好的Kafka集群甚至可以做到每秒几十万、上百万的超高并发写入。 那么Kafka到底是如何做到这么高的吞吐量和性能的呢?这篇文章我们来一点一点说一下。 1、页缓存技术 + 磁盘顺序写 首先Kafka每次接收到数据都会往磁
-
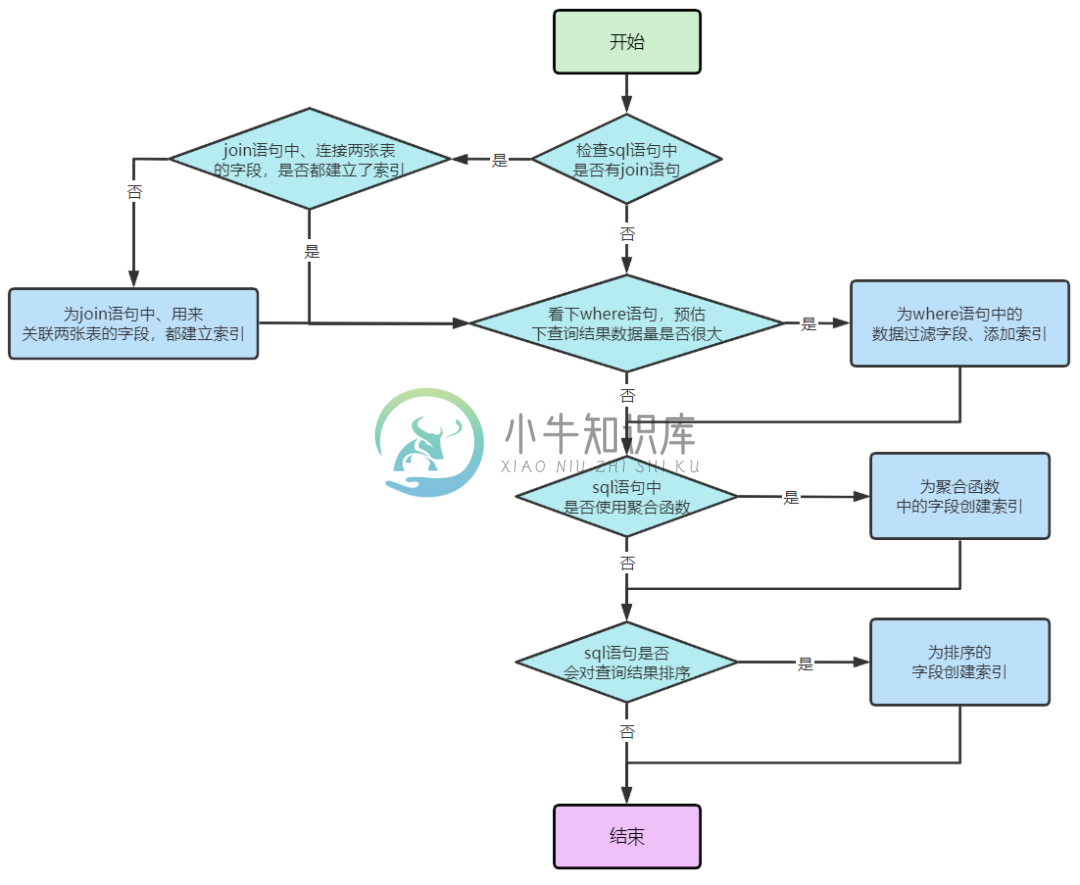 千万数据量下的真实业务场景SQL性能优化!
千万数据量下的真实业务场景SQL性能优化!主要内容:前 言,Simple nested loop算法,Block nested loop 算法,Index nested loop算法,到底能不能使用join?,join关联查询优化实战,优化:被驱动表order_no列添加索引,进一步优化:去掉join,被动向主动的转变,监控系统诞生前 言 通过前几期文章的积累,现在我们的理论知识已经极为扎实了,这个时候就可以动手开始sql优化了,sql优化是非常重要,因为即使再好的MySQL设计架构,也扛不住一个频繁查询的垃圾sql语句。 关于sql的
-
 万物心选算法实习生面经(一面二面+三面挂)
万物心选算法实习生面经(一面二面+三面挂)万物心选是一个小公司,但是听HR说团队挺牛的,是百度的原创团队成员,二面三面的时候也能感觉到面试官是大佬,但是感觉很怪,前面都聊得挺好的,最后把我挂了,浪费我蛮多时间的。 感觉最开始可能是想要我的,但是后来来了更合适的候选人,就找个理由把我挂掉了。 一面(7.5) 自我介绍 推荐的岗位和其他算法岗(CV,NLP)有啥区别 写个代码(补全训练过程,可以上网查,也可以复制自己的代码) import t
-
成千上万的图像,我应该如何组织目录结构?(Linux)
问题内容: 我正在由1and1.com托管的Linux服务器上,成千上万的用户上传了数千张图片(我相信他们使用的是CentOS,但不确定该版本)。这是一个与语言无关的问题,但是,供您参考,我正在使用PHP。 我的第一个想法是将它们全部转储到同一目录中,但是,我记得前一阵子,在一个目录中可以放多少个文件或目录是有限制的。 我的第二个想法是根据用户的电子邮件地址对目录内的文件进行分区(因为无论如何,这
-
MySQL百万级数据量分页查询方法及其优化建议
本文向大家介绍MySQL百万级数据量分页查询方法及其优化建议,包括了MySQL百万级数据量分页查询方法及其优化建议的使用技巧和注意事项,需要的朋友参考一下 数据库SQL优化是老生常谈的问题,在面对百万级数据量的分页查询,又有什么好的优化建议呢?下面将列举了一些常用的方法,供大家参考学习! 方法1: 直接使用数据库提供的SQL语句 语句样式: MySQL中,可用如下方法: SELECT * FROM
-
 万集科技23届秋招前端岗一面二面hr面(已oc)
万集科技23届秋招前端岗一面二面hr面(已oc)公司效率很高,周二投简历,周三约周四面试,周五约下周一二面,一天推进一个流程,好评。 一面30min ——————二面—————— 1.自我介绍 2.为什么选择前端 3.是否用过绘制地图的js——cesium.js 4.数组去重 5.介绍一下原型链 6.js数据类型 7.列举一下es6语法 8.promise、promise.all 9.async/await 和 promise 的区别 10.事
-
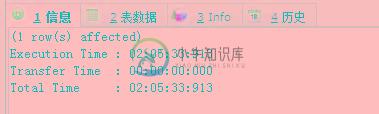 java中JDBC实现往MySQL插入百万级数据的实例代码
java中JDBC实现往MySQL插入百万级数据的实例代码本文向大家介绍java中JDBC实现往MySQL插入百万级数据的实例代码,包括了java中JDBC实现往MySQL插入百万级数据的实例代码的使用技巧和注意事项,需要的朋友参考一下 想往某个表中插入几百万条数据做下测试,原先的想法,直接写个循环10W次随便插入点数据试试吧,好吧,我真的很天真.... 执行CALL proc_initData()后,本来想想,再慢10W条数据顶多30分钟能搞定吧,结果
-
如何删除具有2000万行数据集的MySQL中的重复项?
问题内容: 我有很大的MySQL数据库。我需要快速删除重复的项目。外观如下: 删除后,表的其余部分应为: 我不在乎身份证。最重要的是没有重复的项目会消失。 问题答案: 您可以尝试以下方法: 即,尝试添加到您的列和表中 这样做的 好处 是,将来也不会有重复的行可以插入到表中
-
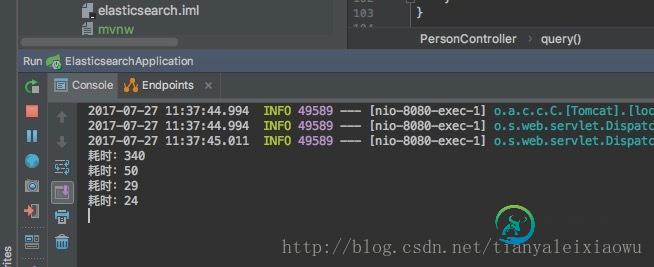 java 使用ElasticSearch完成百万级数据查询附近的人功能
java 使用ElasticSearch完成百万级数据查询附近的人功能本文向大家介绍java 使用ElasticSearch完成百万级数据查询附近的人功能,包括了java 使用ElasticSearch完成百万级数据查询附近的人功能的使用技巧和注意事项,需要的朋友参考一下 上一篇文章介绍了ElasticSearch使用Repository和ElasticSearchTemplate完成构建复杂查询条件,简单介绍了ElasticSearch使用地理位置的功能。 这一篇
-
如何导出百万记录DynamoDB表作为CSV使用数据管道?
我有一个百万记录的DynamoDB表。我正在使用数据管道将DynamoDb表导出到S3。但是数据管道以DynamoDB JSON格式将表导出为一组原始json文件。数据管道运行一小时后,由于超时异常,EMR失败。 有没有办法将DynamoDB表导出为CSV并增加数据管道中的EMR超时配置?
-
基于Neo4j的大型图节点度查询(百万节点和链接)
有人在neo4j上用gremlin或Cypher查询这么大的图形吗?