《兴盛优选》专题
-
芹菜和RabbitMQ-队列优先级vs.消费者优先级vs.任务优先级
在我的python应用程序中,我使用芹菜作为任务生产者和消费者,使用RabbitMQ作为代理。现在,我正在实施优先级排序。起初,它看起来根本不起作用,因为根据文档,我刚刚在队列中添加了参数。我更深入地研究了一下,发现了另一种优先级——消费者优先级和任务优先级。所以,现在,看起来有三种不同的优先顺序,我完全困惑了。你能给我解释一下区别吗? 队列最大优先级:即https://www.rabbitmq.
-
javac优化标志
问题内容: 我最近一直在用C编写很多代码,现在正在切换到Java。我当前正在实现一个大型数据结构,并且想知道在调用Java编译器时是否可以打开任何优化标志,以提高gcc之类的性能。 我习惯于: 有类似的命令javac吗? 我正在使用JDK并正在运行Ubuntu 10.04。 问题答案: Java中的优化主要由JIT编译器在运行时完成。因此,没有必要试图指示它在编译时优化某种方式(无论如何它仅创建字
-
Nodejs性能优化
问题内容: 我是性能优化的新手,虽然我认识到nodejs可能不是最适合初学者的地方,但这是手头的任务。 观察结果:在没有负载且数据库中的用户少于10个的登台服务器上,简单JSON API请求的时间约为数百毫秒。特别是,对/ api / get_user的调用大约需要300毫秒 执行以下代码: (注意:我们将会话存储在Redis中) 堆栈: Nodejs Express Redis Mongo 我从
-
Hadoop性能调优?
本文向大家介绍Hadoop性能调优?相关面试题,主要包含被问及Hadoop性能调优?时的应答技巧和注意事项,需要的朋友参考一下 调优可以通过系统配置、程序编写和作业调度算法来进行。 hdfs的block.size可以调到128/256(网络很好的情况下,默认为64) 调优的大头:mapred.map.tasks、mapred.reduce.tasks设置mr任务数(默认都是1) mapred.ta
-
 MySQL分页优化
MySQL分页优化本文向大家介绍MySQL分页优化,包括了MySQL分页优化的使用技巧和注意事项,需要的朋友参考一下 最近,帮同事重写了一个MySQL SQL语句,该SQL语句涉及两张表,其中一张表是字典表(需返回一个字段),另一张表是业务表(本身就有150个字段,需全部返回),当然,字段的个数是否合理在这里不予评价。平时,返回的数据大概5w左右,系统尚能收到数据。但12月31日那天,数据量大概20w,导致SQL执
-
ANTLR 优先规则
本文向大家介绍ANTLR 优先规则,包括了ANTLR 优先规则的使用技巧和注意事项,需要的朋友参考一下 示例 几个词法分析器规则可以匹配相同的输入文本。在这种情况下,令牌类型将选择如下: 首先,选择与最长输入匹配的词法分析器规则 如果文本与隐式定义的标记匹配(例如'{'),请使用隐式规则 如果多个词法分析器规则匹配相同的输入长度,请根据定义顺序选择第一个 以下是组合语法: 给出以下输入: 将从词法
-
MongoDB查询优化
问题内容: 我希望从我的用户模型中检索一些信息,如下所示: 在主页中,我有一个 位置 过滤器,您可以在其中浏览来自国家或城市的用户。 所有字段还包含其中的用户数: 在主页上,然后我还有“学生和老师”页面,我希望仅提供有关这些国家和城市有多少老师的信息… 我想做的是创建一个对MongoDB的查询,以通过单个查询检索所有这些信息。 此刻查询如下: 问题是我不知道如何获取所需的所有信息。 我不知道如何获
-
ApacheApache性能调优
主要内容:硬件和操作系统问题,运行时配置问题,编译时配置问题,原子操作,附录:跟踪的详细分析Apache 2.x是一个通用的Web服务器,旨在提供灵活性,可移植性和性能之间的平衡。虽然它没有专门设计用于设置基准记录,但Apache 2.x在许多实际情况下都具有高性能。 与Apache 1.3相比,版本2.x包含许多额外的优化,以提高吞吐量和可伸缩性。默认情况下,大多数这些改进都已启用。但是,存在可能显着影响性能的编译时和运行时配置选择。本文档介绍了服务器管理员可以配置的选项,以调整Apa
-
优先级反转
在TSL机制中,可能存在优先级反转的问题。让我们说有两个合作进程:P1和P2。 P1的优先级为2,而P2的优先级为1,P1较早到达并由CPU调度。由于它是一个协作进程,并且希望在临界区执行,因此它将通过将锁变量设置为1来进入临界区。 现在,P2到达就绪队列。 P2的优先级高于P1,因此根据优先级调度,P2被调度并且P1被抢占。 P2也是一个合作进程,并希望在临界区内执行。 虽然,P1被抢占,但它的
-
 优先级调度
优先级调度在优先级调度中,为每个进程分配一个优先级编号。 在一些系统中,数字越小,优先级越高。 而在其他情况下,数字越高,优先级越高。 在可用进程中具有较高优先级的进程由CPU提供。 存在两种类型的优先级调度算法。 一种是抢占式优先级调度,而另一种是非抢先式优先级调度。 分配给每个过程的优先级编号可能会也可能不会变化。 如果优先级号码在整个过程中没有改变,它被称为静态优先级,而如果它保持定期改变自己,它被称
-
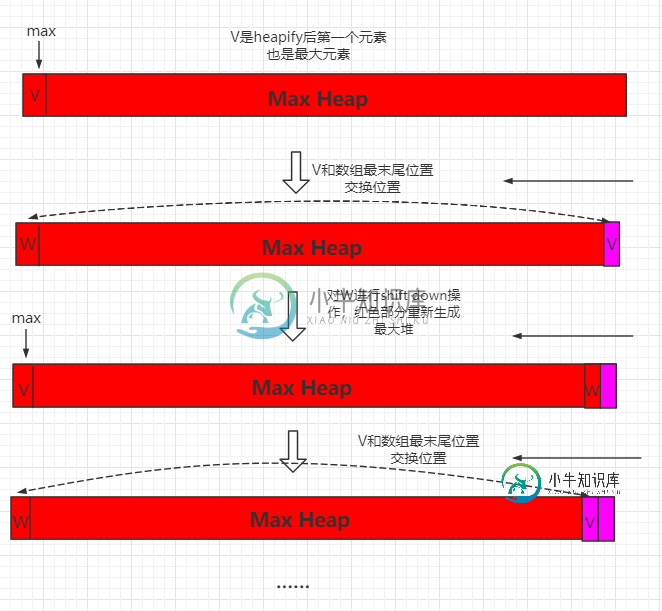 优化堆排序
优化堆排序主要内容:src/runoob/heap/HeapSort.java 文件代码:上一节的堆排序,我们开辟了额外的空间进行构造堆和对堆进行排序。这一小节,我们进行优化,使用原地堆排序。 对于一个最大堆,首先将开始位置数据和数组末尾数值进行交换,那么数组末尾就是最大元素,然后再对W元素进行 shift down 操作,重新生成最大堆,然后将新生成的最大数和整个数组倒数第二位置进行交换,此时到处第二位置就是倒数第二大数据,这个过程以此类推。 整个过程可以用如下图表示: Java 实
-
Linux的优缺点
主要内容:1) 大量的可用软件及免费软件,2) 良好的可移植性及灵活性,3) 优良的稳定性和安全性,4) 支持几乎所有的网络协议及开发语言前面章节提到,相比 Windows 系统,Linux 系统有更好的稳定性,那么除此之外,Linux 系统还有那些优点(或者不足)呢?本节带领大家详细了解一下。 1) 大量的可用软件及免费软件 Linux 系统上有着大量的可用软件,且绝大多数是免费的,比如声名赫赫的 Apache、Samba、 PHP、 MySQL 等,构建成本低廉,是 Linux 被众多企业青
-
优化MongoDB调用
我有一个mongoDB集合,我正在使用java驱动程序从mongo集合中获取数据。 我有一个电话号码列表,我需要在mongoDB集合中搜索所有这些手机号码。 假设我有500个手机号码,目前从我的java代码来看,我会说: 现在的问题是我打了500次DB。。 我想知道是否有更好的方法来处理,例如在RDBMS中,我们如下所示 所以像上面的查询一样,单次调用就足够了,但是在in子句中传递给SQL的参数数
-
 Scipy优化算法
Scipy优化算法主要内容:Nelder–Mead单纯形算法, 最小二乘,求根包提供了几种常用的优化算法。 该模块包含以下几个方面 - 使用各种算法(例如BFGS,Nelder-Mead单纯形,牛顿共轭梯度,COBYLA或SLSQP)的无约束和约束最小化多元标量函数() 全局(蛮力)优化程序(例如,,) 最小二乘最小化()和曲线拟合()算法 标量单变量函数最小化()和根查找() 使用多种算法(例如,Powell,Levenberg-Marquardt混合或Newton-Kr
-
性能和优化
本文档提供的技术与工具概述,有助于使您的Django代码更高效,更快速,并使用更少系统资源。 简介 通常,人们首先关心的是编写的代码起作用,其逻辑函数根据需要产生预期输出。然而,有时,这将不足以使代码像我们希望的那样有效地工作。 Generally one’s first concern is to write code that works, whose logic functions as r