《兴业数金面试》专题
-
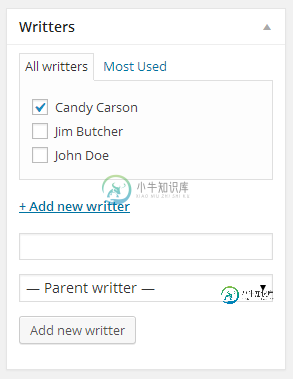 商业分类学
商业分类学我为木马产品定制了分类法,产品将书籍和电子书都有自己的写手。 现在,我需要显示它,例如在产品标题下,并需要双向链接,如标签或类别。
-
MapReduce作业挂起
我是Hadoop的MapReduce的新手。我已经编写了一个map-reduce任务,我正在尝试在本地计算机上运行它。但这项工作在地图绘制完成后就悬而未决了。 下面是代码,我不明白我错过了什么。 我有一个自定义密钥类 使用自定义键的映射器和缩减器类如下。 我还在main中创建了一个作业和配置。不知道我错过了什么。我在本地环境下运行这一切。
-
1.2.4 业界对比
总的来说,我们相信Envoy为现代服务导向架构提供了独特且引人注目的功能。下面我们比较一下Envoy和其他相关的系统。尽管在任何特定的领域(边缘代理,软件负载平衡器,服务消息传递层),Envoy可能不像下面的一些解决方案那样具有丰富的功能,但总体而言,没有其他解决方案将相同的整体特征提供到单个自包含的高性能套餐。 注:以下大部分项目也都正在积极开发中。因此,一些信息可能会过时。如果是这种情况,请让
-
14.14 专业术语
alphabeticfield 字母域 characterfield 字符域 binary digit 二进制数 chatter set 字符集 bit 位 cin(standard input) 标准输人 byte 字节 clog(standarderrorbuffeted) 缓冲标准错误流 cerr(standard err unbuffered) 无缓冲标准错误流 close a file
-
13.18 专业术语
abort() catch an exception 捕获一个异常 assert macro assert 宏 catch argument catch参数 auto_ptr catch block catch块 bad_alloc catch(...) bad_cast dynamic_cast bad_typeid empty exception specification 空异常指定 cat
-
12.10 专业术语
angle brackets 尖括号 keyword temPlate 关键字 template class template 类模板 non-type parameter in a templateheader 模板首 class template name 类模板名 部中的无类型参数 formal parameter in a template header 模板首部中的形式参数 overlo
-
11.11 专业术语
bad member function bad 成员函数 end-of-file 文件尾 badbit endl cerr eof member function eof 成员函数 cin eofbit clear member function clear 成员函数 extensibility 可扩展性 clog fail member function fail 成员函数 cout failb
-
10.12 专业术语
abstract base class 抽象基类 offset into vtable vtable偏移量 abstract class 抽象类 override a pure virtual function 重定义纯虚函数 base-class virtual function 基类虚函数 override a viltual function 重定义虚函数 class hieratchy 类
-
9.17 专业术语
abstraction 抽象 inheritance 继承 ambiguity in multiple inheritance 多重继承的歧 is a relationship 是关系 义性 knows a relationship 知道关系 associaion 关联 member access control 成员访问控制 base class 基类 member class 成员类 base
-
8.14 专业术语
cast operator function 强制类型转换运算符函数 operator<= cascadedoverloaded operators 连续使用重载的运算符 operator+ calss Array Array类 operator+= class ate Date类 operator() class HugeInteger HugeInteger类 operator[] class
-
7.13 专业术语
abstract data type(ADT) 抽象数据类型 dequeue(queueoperation) 出队(队列操作) binary scope resolution operator(::) 二元作用域 destructor 析构函数 运算符 dynamic objects 动态对象 cascading member function calls 连续使用成员 enqueue(queue
-
6.20 专业术语
&reference operator &引用运算符 constructor 构造函数 abstract data type(ADT) 抽象数据类型 datamember 数据成员 access function 访问函数 data type 数据类型 arrow mber selection operator(->) 箭头成员 default constructor 默认构造函数 选择运算符 d
-
4.11 专业术语
a[i] a[i][j] columnsubscript 列—F标 const type qualifier const 类型限定符 array 数组 constant variable 常量变量 array initializer list 数组初始化值列表 declareanarray 声明数组 binary search of an array 数组折半查找 double-subscript
-
Figure 商业插图
图标定义 “现代商业插图”是为企业或产品传递商品信息,集艺术与商业的一种图像表现形式。 商业活动要求把所承载的信息准确、明晰地传达给观众,希求人们对这些信息正确接收、把握,并在让观众采取行动的同时使他们得到美的感受,因此说它是为商业活动服务的。 命名 商业插图遵循统一命名规则,即 类型_位置_名称 例:pic_page01_rocket 适用范围 内容表意复杂,且需要被进一步解释/营造气氛 多用于
-
企业通讯录
在通讯录管理模块,管理员可对通讯录的可见范围、通讯录的字段、以及通讯录安全进行统一管理。 设置可见范围 根据企业内部人员构成情况,设置通讯录可见范围,保护成员信息不外泄。 设置入口:【管理后台】>【我的企业】>【通讯录管理】查看 1 / 隐藏部门/成员 点击添加,从组织架构中选择需要被隐藏的部门或成员,他们的名字将不会显示在公司通讯录中。支持添加白名单,白名单成员可以查看完整的通讯录。 2 / 限