《兴业数金面试》专题
-
 8月5号腾讯金融科技CDG提前批测开一面
8月5号腾讯金融科技CDG提前批测开一面bg酸非本,2段实习 秋招第一面,拿腾讯练手😂😋😋 1. 自我介绍 2. 我看你简历上也有2个自己开发的项目,你觉得哪个更复杂一些?难度更高一点? 3. 详细说一下你是怎么设计的,以及架构是怎么样子 4. 后台这一块,你的登录做了什么处理? 5. 使用的是已有的技术,没有再增加什么吗? 6. jwt有做什么校验呢? 7. 用户传用户名和密码是用什么协议? 8. 会不会有密码泄漏的风险? 9.
-
测试Quartz JDBC作业存储
现在我手动更改系统时间。例如,如果我将作业安排在2/5/2013 12:45 PM运行,那么我将系统时钟时间更改为2/5/2013 12:43 PM,然后等待几分钟,看看Quartz是否从DB接收到该作业。这对我很管用。 我不想每次需要测试时都更改系统时钟时间。有没有更好的办法做到这一点? 我注意到频繁地改变系统时间有时会使Quartz搞砸,因为有些工作没有被接上。
-
发布测试、作业、考试
老师操作指南-发布测验,作业,考试 添加单元测验或作业 单元测验为客观题,支持单选、多选、填空题、判断题四种类型;单元作业为主观题。注意:如果需要用到 online judge 编程题,需要提出申请,由运营开通权限后,方可添加。 注意: 测验和作业的发布时间需设置的晚于本章节内容发布时间,并且需要设置相应的截止时间 。 单元测验 点击“添加测验”,输入测验名称及时间,点保存; 之后,点击“添加测验
-
 转数分面试记录
转数分面试记录高途 数据分析师 6.22一面深挖业务 1h boss 数据分析师 6.23一面 深挖业务 模型经验 1h 快手 da/ds 海外6.24一面 深挖业务 统计学 一道sql模型经验 1h 字节 数据分析 本地生活 7.1一面 项目经历 业务场景提问 30mins
-
 大数据面试记录
大数据面试记录#数据人的面试交流地# 1.首先自我介绍,一定要加上自己会啥,自己的优势一定要多说出来 2.简历上写的项目一定要自己做的,如果是网上抄的一定要弄懂才能写出来,要不然容易出现问题 3.写自己的技能一定要写自己弄的比较懂的 4.再来说一下我对大数据的理解,大数据讲究计算和存储,对于存储一定要懂hdfs,hive等等技术,对于计算我建议一定要会spark,flink也要会,你可以不用但要会,spark说
-
 阿里数分面试题
阿里数分面试题1、淘宝服装品类如果构建指标体系评估业绩情况,如何构建? 2、如何搭建天猫的业务监控指标体系? 请问有大佬可以分析一下思路吗
-
ebay-数据仓库面试
英文自我介绍和项目介绍 Good Afternoon, my name is Wang Longjiang,graduated from Anhui University. I have been working in the Institute of Aerospace Information, Chinese Academy of Sciences for two years. Focus o
-
 数仓实习生面试
数仓实习生面试总体问的都是蛮基础的,也是根据简历来问的,你简历上写熟悉哪些,就会问哪些 1.自我介绍 2.项目来源,自己做的还是网上找来做的 3.离线数仓介绍 4.项目遇到的问题(提到kafka的重复数据) 5.为什么kafka会出现重复数据 6.你项目中怎么处理的 7.数仓分层的好处 8.数仓分了哪几个数据域 9.讲一些维度建模 10.常见的维度模型(雪花、星型) 11.使用场景 12.除了维度建模,还有哪些
-
 360数分面试记录
360数分面试记录1.大数据概念? 2.用接口啥啥的爬过数据吗? 3.linux的指令会不会? 4.hadoop了解吗? 5.sql怎么优化? 我:………… 还需努力。。。。。。
-
 数字马力ai面试
数字马力ai面试自我介绍及为什么选择测试开发工程师岗位 如何高效的提出bug 项目上线前,测试最后的准备工作有哪些 给银行在线转账系统设计用例 说服他人例子,用了那些沟通方式 在学校或学习过程中遇到困难,有什么标准或步骤解决 向学长学姐寻求建议的例子 多个日期重叠如何处理这种高压情况 项目团队之间发生分歧,如何确保团队到达最终目标 感觉被当成免费的语料喂ai了😥😥😥 #牛客创作赏金赛#
-
 2023届校招面经:浦发银行总行业务零售部-数据分析类岗位
2023届校招面经:浦发银行总行业务零售部-数据分析类岗位TimeLine:一面20221108,二面20221124 BG:北邮本硕,管理类专业,两段实习经历:字节数据分析师、美团商业分析师 一面 群面,10名候选人,5分钟阅读题目,每人1分钟时间陈述个人看法,10分钟时间团队讨论,5分钟时间汇报,之后会对一部分面试者进行单独提问 二面 5分钟时间,体验很一般,面试官会在面试者回答问题时打断发言,且面试官问的问题与岗位本身无太大关联 1. 1分钟时间自
-
请谈一谈你有什么兴趣爱好呢?
本文向大家介绍请谈一谈你有什么兴趣爱好呢?相关面试题,主要包含被问及请谈一谈你有什么兴趣爱好呢?时的应答技巧和注意事项,需要的朋友参考一下 辩论,因为参加辩论比赛能够锻炼我的逻辑思维,提升我的应对能力,另外也能更精准的找到别人话语中的漏洞,因为辩论需要专注去听和思考,那么也能让我在做一件事情的时候更加专注。
-
大数据数仓高级面试题 3
主要内容:1.建模锯齿,2.数据粒度的锯齿操作,3.下游表依赖上游表问题,4.数仓数据域划分方式,5.数仓一致性是如何保证的,6.数仓优化,7.数据全生命周期,8.数仓建模问题,9.数仓建模过程1.建模锯齿 建模锯齿是指在建模过程中的一种常见的效应,其中模型的输出可能会产生锯齿状的波动。这种效应通常是由于模型的不稳定性或过度拟合导致的。 在建模过程中,锯齿可能会使模型的表现变差,并且在预测新数据时也可能出现不一致的结果。因此,在建模时需要注意避免出现锯齿状的波动。 一种常用的方法是使用正则化来限
-
大数据数仓高级面试题 1
主要内容:1.数仓高内聚低耦合,2.多重粒度,3.如何提高查询效率,4.数仓数据域划分几种方式,5.粒度操作,6.SQL实现,7.数仓中ODS层命中多少为合理,8.数仓价值链的体现和实现,9.建立数仓的步骤,10.指标生命周期的评估,11.数据治理,12.数仓的目的1.数仓高内聚低耦合 一般复杂的公共逻辑可以采用抽象类和抽象方法的方式下沉到共有模块中,然后由相关子类去实现抽象方法,来实现不同的功能。这样可以将复杂的逻辑拆分成各个子类,使得类之间的耦合度降低,提高代码的可维护性。 2.多重粒度 在
-
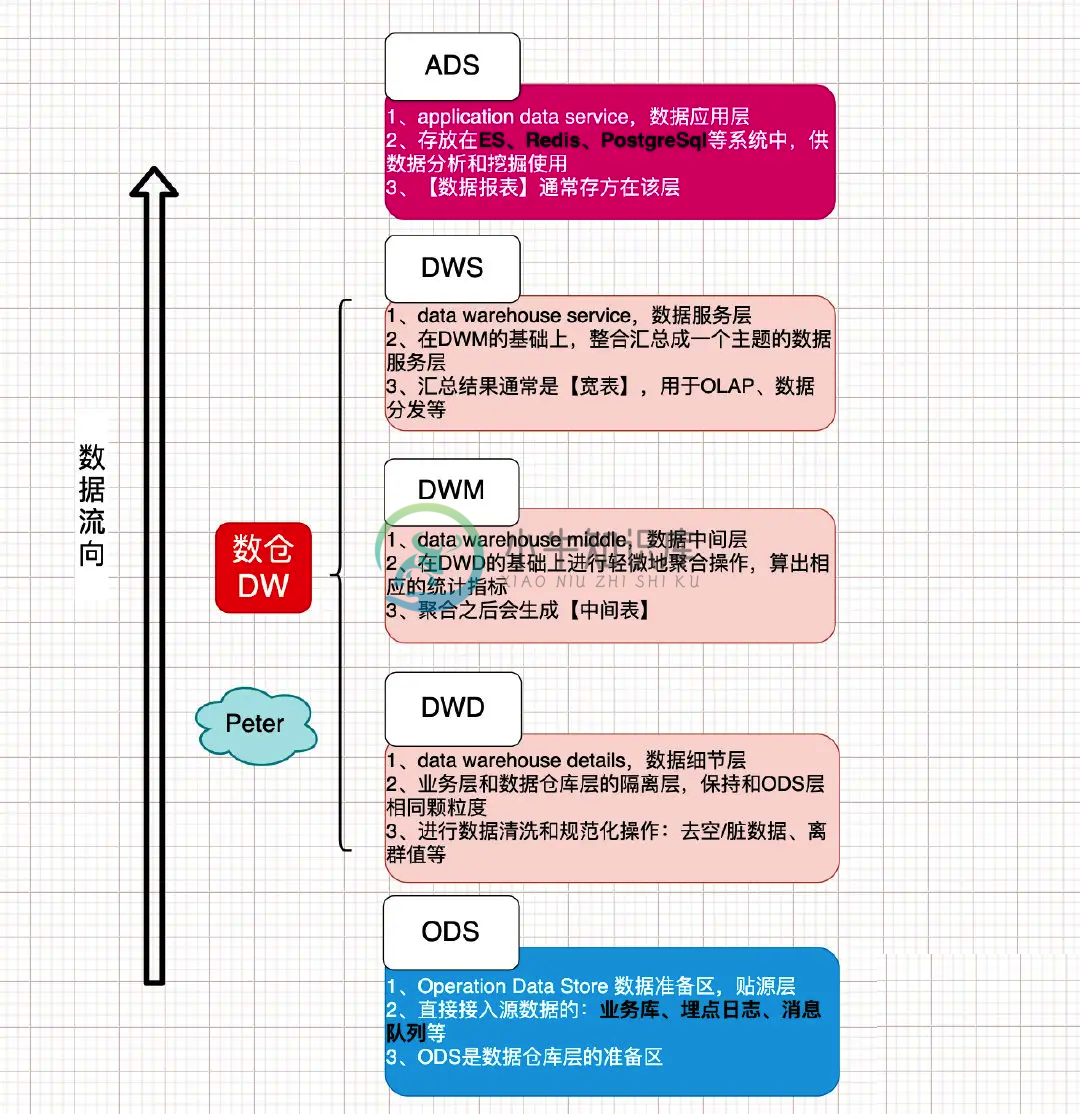 大数据数仓高级面试题 4
大数据数仓高级面试题 4主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括