《兴业数金面试》专题
-
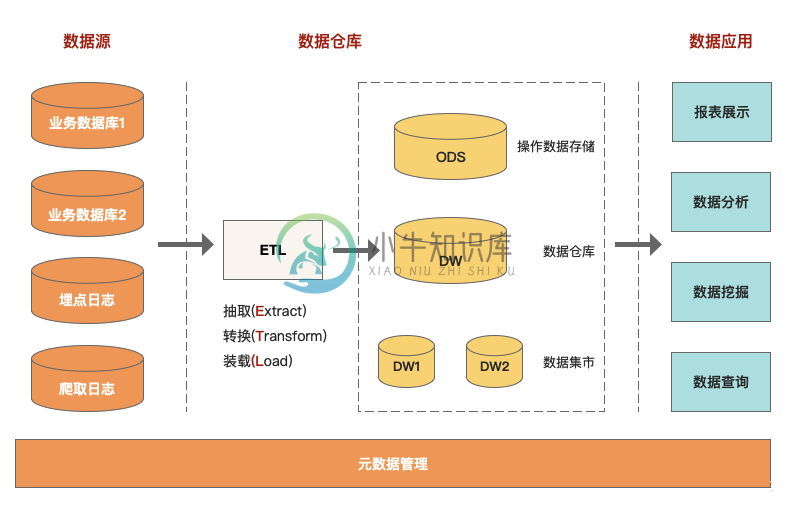 大数据数仓高级面试题 2
大数据数仓高级面试题 2主要内容:1、什么是数据仓库?,2、数据仓库和数据库的区别?,3、如何构建数据仓库?,4、什么是数据中台?,5、数据中台、数据仓库、大数据平台、数据湖的关键区别是什么?,6、大数据有哪些相关的系统?,7、如何建设数据中台?,8、数据仓库最重要的是什么?,9、概念模型、逻辑模型、物理模型分别介绍一下?,10、SCD常用的处理方式有哪些?,11、怎么理解元数据?,12、数仓如何确定主题域?,13、如何控制数据质量?,,,,1、什么是数据仓库? 权威定义:数据仓库是一个面向主题的、集成的、相对稳定的、
-
JavaScript 格式化数字、金额、千分位、保留几位小数、舍入舍去
本文向大家介绍JavaScript 格式化数字、金额、千分位、保留几位小数、舍入舍去,包括了JavaScript 格式化数字、金额、千分位、保留几位小数、舍入舍去的使用技巧和注意事项,需要的朋友参考一下 前端开发中经常会碰到用 JavaScript?格式化数字,最最常见的是格式化金额,一般格式化金额需要千分位分隔,保留2位小数等等。 简单的功能函数 类似的代码网上有很多: 或者 更加完善的功能函数
-
 数字马力-测试-长沙二面面经
数字马力-测试-长沙二面面经#24秋招#(面试官很和蔼,可惜我太菜了) 1、自我介绍 2、我现在说一个场景昂,淘宝双十一用户下单支付的时候,假如有1000个人同时下单,请求支付宝的接口,这1000人选择银行卡支付,支付宝再调用银行的接口,银行的接口只能承受800个人同时下单,如何处理?(太菜了,坑坑巴巴说了几个方法) 3、你自己做的项目有没有遇到什么难点,项目登录用到加盐算法,如何实现的?我感觉这面试官比我还懂我的项目(哈哈
-
 数字马力-质量测试-一面面经
数字马力-质量测试-一面面经大约30min 1、自我介绍; 2、Spring、SpringBoot和SpringMVC的区别; 3、说一下归并排序的思想,归并排序和快速排序那个速度更快; 4、说一下二叉树的应用场景,前序遍历和后序遍历的区别以及应用场景; 5、Mysql事务和索引有了解吗?说一下Mysql的索引; 6、sql语句到Mysql的整个执行流程; 7、说一下你对Mysql数据库的使用,像聚集函数、外连接、group
-
 🔥🔥代码手撕十三金钗🔥🔥再也不怕面试官让我手撕了
🔥🔥代码手撕十三金钗🔥🔥再也不怕面试官让我手撕了面试了两个月,发现大大小小的公司无论面试多久,最后必须来两三道手撕题,考验候选人的代码能力 平时简单题手到擒来,但到了面试官面前就大脑宕机 简简单单一道【实现apply】都能卡住,我的总结是还得多练,同一道题多打几次,面试的时候才能思路清晰 整理了最基础的常见手撕,啃下这些,基本可以应对70%的手撕题 当然大厂手撕并不都是简单基础题,很多都是在这13道基础上拓展,先练好这13道基础题,面试的时候就
-
 爱数二面
爱数二面1、自我介绍 2、软件测试的流程,问到了是怎样学到这些流程的? 3、测试用例设计方法,我说了参考同类型的产品,然后又让我说怎么样找到同类型产品的测试用例 4、编写测试用例的要素 5、使用过那些操作系统,Linux 修改文件权限的命令,又问到是自己确实用过还是就是纯背诵的; 6、了解Linux磁盘阵列吗 7、关系型数据库的对象 8、数据库事务,我说了一些书本知识,又被问到是不是背诵的概念; 9、个人
-
 数码一面
数码一面1、自我介绍 2、前端技术问答 3、数据结构问答 4、学习路线问答 5、未来规划问答 面试官人很好,就是我有点紧张,面试官还一直鼓励我不要紧张 问一下大家都是面完多久收到消息的啊
-
 【前端校招面经】小米南京互联网业务部前端23校招一面面经
【前端校招面经】小米南京互联网业务部前端23校招一面面经自我介绍 在你过往实习的项目中你遇到过哪些问题, 如何解决的 CSS属性有哪些值, 列举出来其各自的作用 static, relative, fixed, absoluate, sticky 口述原理 CSS 手写一个 CSS 将页面元素隐藏的方式有哪些 浏览器缓存原理 手撕代码: 参考答案: 手撕代码: 用实现防抖/节流, 要求用 ts 的泛型机制控制防抖与节流函数的参数与返回值类型相同 参考答
-
 字节产运实习|商业化运营一面面经(已入职)附答案!
字节产运实习|商业化运营一面面经(已入职)附答案!1.自我介绍🎓 大致介绍了自己的院校、专业,我结合了所招岗位JD来讲,过程中挑之前自己实习过程中和JD相符的点,全力证明自己和这个岗位的匹配度,全程大概2min 2.深挖简历 ✏️ 针对刚才的自我介绍,面试官反问问题,主要是反问和JD上相关的(所以提前了解岗位所需很重要),深挖之前的实习经历,⚠️简历一定不能造假 面试官会问很细节的东西,比如拉新了多少人,有关项目的数据(如不知道就诚实的讲不
-
 双非跨专业-CVTE二面-电商运营(面经及个人感受分享)
双非跨专业-CVTE二面-电商运营(面经及个人感受分享)面试公司:cvte 面试岗位:电商运营 个人情况:双非本 跨专业 唯一亮点可能就是实习经历丰富(但没有电商相关实习经验) 面试情况:网传的CVTE工作强度大,在我二面时体现的淋漓尽致... 二面最初和我约的面试时间是: 周 日 晚上的 十 点 半 ! 一看到这个面试时间我整个人都绷不住了,然后协调修改时间,最后将时间协调到了周一晚上八点半... 面试问题很常规,自我介绍、投递公司及岗位意向原因、后
-
 B站产品offer|双非院校,3轮业务面,超详细面经分享!
B站产品offer|双非院校,3轮业务面,超详细面经分享!具体面经 业务一面 自我介绍 介绍一下上一段产品实习 实习项目介绍,介绍一下你实习的 xx项目吗? 你觉得设计xx功能时的原则有哪些? 如何衡量你这个项目优化的效果? ? 看你专业本科,研究生跨度挺大,现在又想做产品,可以说一下为什么? 讲一下你未来三年的职业规划 介绍一下你性格的优劣势 反问环节 (B站一面)总体时长35min 自我介绍 介绍一下实习项目及项目深挖 你项目最大的亮点是什么? 你做
-
 小企业网站
小企业网站创建一个小型企业网站并不是一件复杂的工作。 主要担心的是弄清楚网站的内容,这是企业主拖延的主要原因之一。 小型企业网站是最好的,当他们很简单,最小的文本,并在每个页面上只有一个选项 - 例如,提交表单,或联系我们按钮。 企业网站也倾向于采用标准格式,使用一些必要的网页。 当您浏览列表时,请不要担心格式化每个页面,只需考虑文本,图像和您将包含的内容即可。 一个小企业网站最关键的页面是 - 主页 关于
-
Jenkins作业DSL-javaposse.jobdsl.DSL.helpers.gitparamcontext.userepository()
我试图使用Jenkins DSL groovy来创建Jenkins工作。我对Git参数使用的方法,很少有参数无法识别,并出现以下错误。 方法:javaposse.jobdsl.dsl.helpers.gitParamContext.SelectedValue()的签名不适用于参数类型:(java.lang.String)值:[NONE] 方法:javaposse.jobdsl.dsl.helper
-
Linux就业市场
本文向大家介绍Linux就业市场,包括了Linux就业市场的使用技巧和注意事项,需要的朋友参考一下 Linux技术的职业历来为许多人带来了极大的回报,并且似乎是常绿和衰退的证明。如果您打算学习Linux课程,那么可以肯定,对Linux认证专业人士的需求在不久的将来会持续增长,而且足够稳定。 Linux就业市场现在非常火爆,特别是对于那些具有系统管理技能的人。每个人都在寻找Linux人才。随着对Li
-
groovy 访问物业
本文向大家介绍groovy 访问物业,包括了groovy 访问物业的使用技巧和注意事项,需要的朋友参考一下 示例 注意:*是可选的。我们也可以像下面这样写上面的语句,Groovy编译器对此仍然很满意。