《intel交流群》专题
-
Git提交更改
在本文章教程中,我们将演示如何查看 Git 存储库的文件和提交文件记录,并对存储库中的文件作修改和提交。 注意:在开始学习本教程之前,先克隆一个存储库,有关如何克隆存储库,请参考: http://www.yiibai.com/git/git_clone_operation.html 在上一步中,我们已经修改了 main.py 文件中的代码,在代码中定义了两个变量并提交代码,但是要再次添加和修改ma
-
ECharts 交互组件
主要内容:实例,实例,实例ECharts 提供了很多交互组件:例组件 legend、标题组件 title、视觉映射组件 visualMap、数据区域缩放组件 dataZoom、时间线组件 timeline。 接下来的内容我们将介绍如何使用数据区域缩放组件 dataZoom。 dataZoom dataZoom 组件可以实现通过鼠标滚轮滚动,放大缩小图表的功能。 默认情况下 dataZoom 控制 x 轴,即对 x 轴进行数
-
C#交错数组
主要内容:1、声明交错数组,2、初始化交错数组,3、访问数组中的元素,4、交错数组和多维数组C# 中的交错数组其实就是元素为数组的数组,换句话说就是交错数组中的每个元素都可以是维度和大小不同的数组,所以有时交错数组也被称为“数组的数组”。 1、声明交错数组 交错数组的声明语法如下所示: data_type[][] array_name; 假如要声明一个具有三个元素的一维交错数组,并且数组中的每个元素都是一个一维的整型数组,示例代码如下: int[][] jaggedArray = new
-
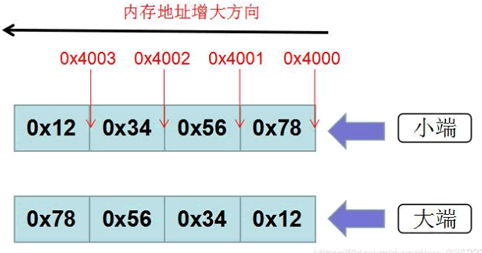 NumPy字节交换
NumPy字节交换主要内容:numpy.ndarray.byteswap()数据以字节的形式存储在计算机内存中,而存储规则可分为两类,即小端字节序与大端字节序。 小端字节序(little-endian),表示低位字节排放在内存的低地址端,高位字节排放在高地址段,它与大端字节序(big-endian)恰好相反。 对于二进制数 0x12345678,假设从地址 0x4000 开始存放,在大端和小端模式下,它们的字节排列顺序,如下所示: 图1:字节存储模式 小端存储后:0x
-
MySQL交叉连接
主要内容:笛卡尔积前面所讲的查询语句都是针对一个表的,但是在关系型数据库中,表与表之间是有联系的,所以在实际应用中,经常使用多表查询。多表查询就是同时查询两个或两个以上的表。 在 MySQL 中,多表查询主要有交叉连接、内连接和外连接。由于篇幅有限,本节主要讲解交叉连接查询。内连接和外连接将在《 MySQL内连接》和《 MySQL外连接》中讲解。 交叉连接(CROSS JOIN)一般用来返回连接表的笛卡尔积。 本节
-
CDI交易警告
调用一个使用数据库(JPA)的方法后,我收到警告: 在事务上下文外部调用了事务注释和必需的 TxType 的托管 Bean。正在开始交易... 但随后它生成SQL查询,一切正常。 信息:Hibernate:插入到ALL_USERS_EXMPL(DATE_ADDED,登录,密码)值 (?, ?, ?) 如何摆脱这些警告?
-
交换向量行
我想通过输入向量的大小在我的2D向量中的2行之间交换,向量元素和2个整数r1和r2代表要交换的行,我真的不知道是否有一个预定义的函数来这样做。 3 3 84-87 78 16 94 36 87-93 50 1 2 交换后的数组: 16 94 36 84-87 78 87-93 50
-
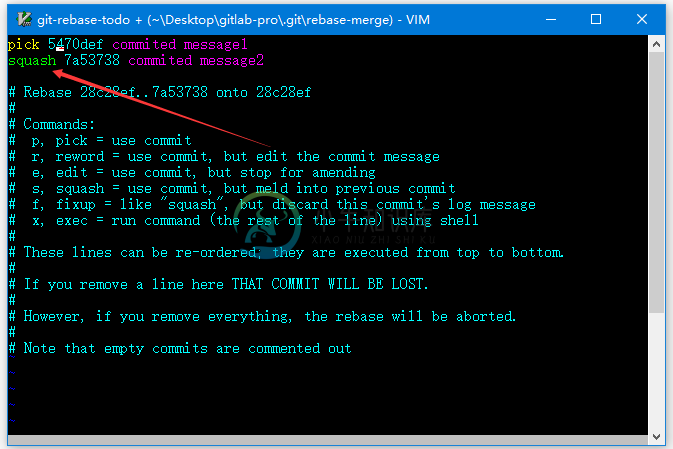 GitLab压缩提交
GitLab压缩提交主要内容:压缩提交的步骤当您获取合并请求时,压缩是将所有提交合并为一个的一种方式。 压缩提交的步骤 步骤(1): 转到您的项目目录,使用命令检出名为的新分支: 标志表示新的分支名称。 步骤(2): 现在,创建一个包含两个提交的新文件,将该文件添加到工作目录,并将更改与提交消息一起存储到存储库中,如下所示: 然后,再次操作 - 步骤(3): 现在,使用以下命令将上述两个提交压缩到一个提交中: 这里,命令用于从一个分支集成到
-
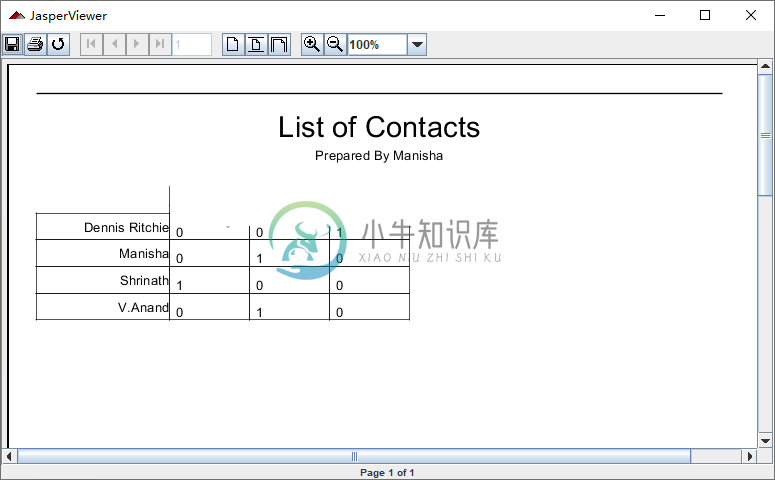 JasperReports 交叉表crosstab
JasperReports 交叉表crosstab主要内容:交叉表属性,JasperReports 交叉表的示例交叉表(cross-tabulation)报表是包含以表格形式跨行和列排列数据的表格的报表。交叉表对象用于在主报表中插入交叉表报表。交叉表可用于任何级别的数据(名义、有序、区间或比率),并且通常以动态表的形式显示包含在报表变量中的汇总数据。变量用于显示汇总数据,例如总和、计数、平均值。 交叉表属性 JRXML 元素<crosstab> 用于在报表中插入交叉表。 属性 以下是 <crosstab>
-
Spring交易和hibernate.current_session_context_class
问题内容: 我有一个使用Hibernate 4和Spring Transactions的Spring 3.2应用程序。所有方法都运行良好,我可以正确访问数据库以保存或检索实体。然后,我引入了一些多线程,并且由于每个线程都在访问db,所以我从Hibernate中收到以下错误: 我从网上读到我必须添加到Hibernate配置中的内容,但是现在每次我尝试访问数据库时,都会得到: 但是,我的服务方法带有注
-
super()和@staticmethod交互
问题内容: super()是否不打算与静态方法一起使用? 当我尝试类似的东西 我收到以下错误 如果我将静态方法更改为类方法,并将类实例传递给super(),则一切正常。我是在这里错误地调用super(type)还是缺少我想要的东西? 问题答案: 的简短答案 我是在这里错误地调用super(type)还是缺少我想要的东西? 是:是的,您打错了它的名称……而且(实际上是 因为 ),您缺少某些内容。 但
-
交换MS-SQL表
问题内容: 我想以最佳方式交换到表。 我有一个IpToCountry表,我每周根据导入的外部CSV文件创建一个新表。 我发现进行切换的最快方法是执行以下操作: 这样做的问题是,表之间仍可能会被访问。 如何在SQL中解决此问题? 考虑使用sp_getapplock和sp_releaseapplock,但是我想尽可能快地从表函数中读取数据。 问题答案: 假设您无法更新/插入现有表,为什么不使用视图
-
测试RabbitMQ交换
我正在尝试编写一个应用程序,测试将N个交换绑定到内存、IO等相同队列的效果。 所有测试都使用“主题”交换类型。我遇到的问题是,当我使用多个exchange进行测试时,我没有收到我发布回的所有消息。但是,当我使用1 exchange时,我会收到所有消息。 你知道为什么会这样吗? 谢谢 编辑: 我有一个队列,它使用相同的绑定键绑定到两个“主题”交换: *。系统日志# #。系统错误 我将向每个excha
-
Kafka-偏移提交
我目前正在从具有特定偏移量的主题中获取消息。我正在使用寻求()来实现它。但是当我将enable.auto.commit设置为true或使用手动同步(委托同步()/委托同步())时,Seek()不起作用,因为它没有轮询来自特定偏移量的消息,而是从最后提交的偏移量中选择。 因此,在使用Seek()时,是否必须将偏移量存储在外部DB中,而不提交给Kafka?Seek和Commit不能并行工作吗? 客户端
-
交易不回滚
问题内容: 我叫两种方法,第一种方法更新一个表,第二种方法在另一个表中插入一条记录。当第二笔交易失败时,它不会回退第一笔交易。 这是我的支持豆: EJB接口: EJB类: 我的自定义例外: 编辑: 添加了DAO类: 和DAO接口: 问题答案: 在这种情况下,关键问题是某些JBoss版本中数据源中的默认错误。原始代码很好,并且可以在其他应用程序服务器(WebSphere App Server和轻量级