《同花顺面试》专题
-
 Canvas实现动态的雪花效果
Canvas实现动态的雪花效果本文向大家介绍Canvas实现动态的雪花效果,包括了Canvas实现动态的雪花效果的使用技巧和注意事项,需要的朋友参考一下 效果如下: 代码如下: 以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持呐喊教程!
-
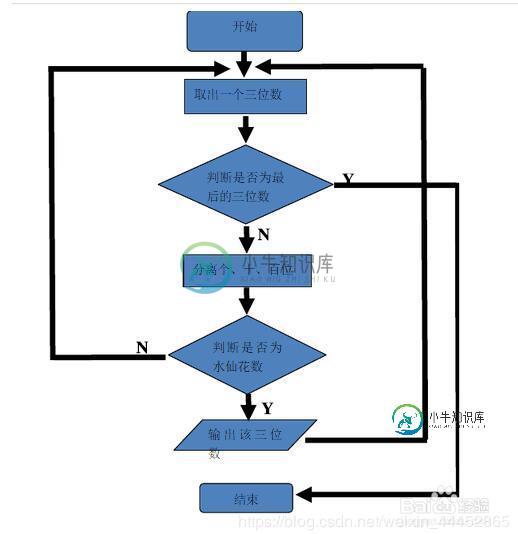 java实现水仙花数的计算
java实现水仙花数的计算本文向大家介绍java实现水仙花数的计算,包括了java实现水仙花数的计算的使用技巧和注意事项,需要的朋友参考一下 看到标题java实现水仙花数,首先先要知道什么是水仙花数,具体了解一下 所谓“水仙花数”是指一个三位数,其各位数字立方和等于该数 列如153=1*1*1+5*5*5+3*3*3 那么153就是水仙花数,首先是分析需要的功能,首先他是一个3位数。 那值一定在100-1000之间,必定
-
火花Kafka生产者可串行化
我想出一个例外: 在这个程序中,我尝试从hdfs路径读取记录,并将它们保存到Kafka中。问题是当我移除关于向Kafka发送记录的代码时,它运行得很好。我错过了什么?
-
DataProc上的Executor心跳超时火花
-
火花:删除所有重复的行
我有一个数据集,如下所示: 但不管用。
-
 Cassandra火花连接器读取性能
Cassandra火花连接器读取性能我有一些Spark经验,但刚开始使用Cassandra。我正在尝试进行非常简单的阅读,但性能非常差——不知道为什么。这是我正在使用的代码: 所有3个参数都是表上键的一部分: 主键(group\u id,epoch,group\u name,auto\u generated\u uuid\u field),聚类顺序为(epoch ASC,group\u name ASC,auto\u generat
-
火花数据帧连接字符串
如何使用Spark-Scala连接日期和时间列(两个字符串)
-
解析火花sql的复杂类型
数据-我使用XML中的许多附加列获取此类数据,并使用com。databricks spark-xml\u 2.11库,用于将xml数据转换为数据帧。 要求-必须从数组(struct)类型或列custom\u属性转换数据。示例中的custom\u属性,如示例输出所示。My struct有三个字段,分别命名为“\u VALUE”、“属性\u id”、“值”。我需要将属性id转换为列名称,数据为-检查“
-
火花/scala字符串json内地图
我有一对看起来像 第二个元素是一个字符串,我从函数get()从http://alvinalexander.com/scala/how-to-write-scala-http-get-request-client-source-fromurl.这里是函数: 现在我想把这个字符串转换成json,从中获取图片url。(来自此)https://stackoverflow.com/a/38271732/14
-
火花阿夫罗到镶木地板
我有一个avro格式的数据流(json编码),需要存储为镶木地板文件。我只能这样做, 把df写成拼花地板。 这里的模式是从json中推断出来的。但是我已经有了avsc文件,我不希望spark从json中推断出模式。 以上述方式,parquet文件将模式信息存储为StructType,而不是avro.record.type。是否也有存储avro模式信息的方法。 火花 - 1.4.1
-
拼花格式中的图式演变
目前我们在生产中使用Avro数据格式。从使用Avro的几个优点中,我们知道它在模式演变方面是好的。 现在我们正在评估Parque格式,因为它在读取随机列时的效率。所以在前进之前,我们仍然关注模式演变。 有谁知道模式演变是否可能在镶木地板中实现,如果是,它怎么可能,如果不是,那么为什么不呢。 一些资源声称这是可能的,但它只能在末尾添加列。 这是什么意思?
-
火花分区数据多个文件
我有5个表存储为CSV文件(A.CSV、B.CSV、C.CSV、D.CSV、E.CSV)。每个文件按日期分区。如果文件夹结构如下:
-
从分区拼花文件读取DataFrame
如何读取带有条件作为数据帧的分区镶木地板, 这工作得很好, 分区存在的时间为< code>day=1到day=30是否可能读取类似于< code>(day = 5到6)或< code>day=5,day=6的内容, 如果我输入< code>*,它会给出所有30天的数据,而且太大了。
-
火花流加入Kafka主题比较
我们需要在Kafka主题上实现连接,同时考虑延迟数据或“不在连接中”,这意味着流中延迟或不在连接中的数据不会被丢弃/丢失,但会被标记为超时, 连接的结果被产生以输出Kafka主题(如果发生超时字段)。 (独立部署中的火花2.1.1,Kafka 10) Kafka在主题:X,Y,...输出主题结果将如下所示: 我发现三个解决方案写在这里,1和2从火花流官方留档,但与我们不相关(数据不在加入Dtsre
-
雪花:Sqlalchemy ORM更新变体字段
有人有做这事的经验吗? 更新: 我要添加的数据是一个字典的python列表: