《数梦工场》专题
-
 宁德时代大数据算法工程师一面
宁德时代大数据算法工程师一面上来先自我介绍然后让自己挑一个项目介绍。后续面试官问了很多问题 1 特征工程如何做 2 特征筛选都有哪些介绍一下 3 随机森林原理 4 支持向量机介绍一下 5 深度学习框架会哪些介绍一下 6 transformer介绍 7 attention机制都有哪些介绍一下 8 lstm原理以及相比于rnn的优势 9 时间序列预测都有哪些方法 10 介绍一下arima算法 11 数据库都会哪些 12 深度学习
-
 德拓-外包面试-大数据开发工程师
德拓-外包面试-大数据开发工程师1.自我介绍 2.数据采集相关,怎么把kafka中的数据采集到mysql中? 忘了 3.hive,两张表的重复数据,怎么去重? 回答distinct,group by ,开窗取第一条, 开窗函数是哪个? 没回答上来 4.udf函数写过吗,flink消费kafka中的数据写过代码吗,需要看代码? 5.使用java干过那些代码? 面试时长:10分钟,面试效果,差 不足:对于简历上的内容,回答支支吾吾,
-
数据库自动更新及自动赋值工具
数据库自动更新及自动赋值工具。代码包里面包括: 一、模型类及数据库配置文件生成器(C#程序,数据库暂时只支持sqlserver,请在Windows上使用) ,具体功能有: 1.生成OC模型类 2.生成C#模型类 3.生成数据库配置文件 二、IOS客户端功能(示例代码travelAPP): 1、通过数据库配置文件生成或更新客户端Sqlite数据库的表结构 2、NSDictionary数据自动赋值给模
-
 腾讯日常实习数据工程一面面经
腾讯日常实习数据工程一面面经原本投的后台开发,后面被数据工程捞了,因为隔了有一个多月没怎么准备所以状态很差。 一开始先自我介绍, 然后开始挖实习,实习简单的说了三个小任务,问的主要还是有关大数据的东西,全程push,脑子空白有点说不出来。 后面开始JAVA八股, 先说的JVM的分区,有什么堆栈,性能调优,垃圾回收机制, hotspot的新生代和老年代, 创建线程的方法,回答了继承thread和runnable接口,又说run
-
 美团大数据开发工程师-转正实习
美团大数据开发工程师-转正实习发帖求好运 部门:基础研发平台-数据科学与平台部 --------- 一面:57min 1.自我介绍; 2.讲最熟悉的项目; 3.爬虫遇到的问题,如何处理的呢; 4.mysql:left join \ right join \ full join,用一个案例讲一下; 5.数据仓库了解吗; 6.Hashmap的原理了解吗; 7.Hadoop了解吗; 8.NameNode了解吗; 9.HDFS为什么安
-
 5.25 特斯拉-暑假实习-数据库工程师
5.25 特斯拉-暑假实习-数据库工程师面试时间:30min 自我介绍 这个岗位主要是数据库运维,介绍一下你对数据库运维的理解? 是怎么了解这些知识的?从本科到研究生是怎么学习的? Linux shell 熟悉不?介绍一些命令 介绍一下MySQL? MySQL调优工具?生成执行计划?执行计划怎么看?说一下你是怎么进行调优的? 索引优化有那些? MySQL主从复制了解过吗? InnoDB的索引结构?介绍一下B树和B+树的区别? InnoD
-
GeoPandas.to_crs()不能作为函数的一部分工作,但可以在独立程序中工作
我试图将一个由点组成的GeoJSON层从EPSG:4326重新投影到EPSG:3857。当我在一个独立的程序中运行下面的代码时(如下所示),输出与预期一样。 上述代码的输出为: 然而,当我使用完全相同的代码创建一个函数时,输出是EPSG: 3857中的shapefile,其中所有点的坐标都是0.00000, 0.00000。大多数时候,这甚至不会在QGIS中显示。此函数的输入参数是要重新项目的Ge
-
如何将数据从一个工作表复制到另一个工作表到特定行
对所有人,谢谢你提前的时间。 我们已经有了工作代码,可以在Excel中用vb将数据从一个wrksht移动到另一个wrksht。 如有任何帮助,我们将不胜感激。 2/22/19 以下是我的回应。 在第二个工作簿上,在第一列上进行搜索时,工作表称为orderlog 谢谢
-
人工智能 - Kmeans如何应用于类别不平衡的数据上(用kmeans做工具)?
Kmeans如何应用于减轻类别不平衡的数据上,然后用来训练其他模型? 用kmeans做工具,不是用不平衡数据区训练kmeans! 举例: 训练数据中A,B,C,D,其中A B类别很多 CD很少; 预测数据中全部是A,C。 此时用kmeans直接把ABCD 聚类成2个? 查看过一些博客,基本上都是水文,没多少有用价值。。。
-
设计模式:工厂与工厂方法与抽象工厂
工厂-创建对象而不向客户机公开实例化逻辑,并通过公共接口引用新创建的对象。是工厂方法的简化版本 工厂方法-定义一个创建对象的接口,但让子类决定实例化哪个类,并通过公共接口引用新创建的对象。 抽象工厂-提供了创建相关对象家族的接口,而无需显式指定它们的类。 null
-
依赖,Android库工程以及多工程设置 - 库工程
4.3 库工程 在上面的多工程配置中,:libraries:lib1 和 :libraries:lib2 可能是Java工程,并且 :app Android工程会用到他们生成的jar报。 但是,如果你想共享访问 Android API 的代码或者使用 Android 的样式资源,那么这个库工程就不能是通常的 Java 工程,而应该是 Android 库工程。 4.3.1 创建一个库工程 一个 An
-
 智识神工的人工智能研究工程师面试
智识神工的人工智能研究工程师面试智识神工 第一面 主要是对项目的询问,解释项目的各种地方。 第二面 自我介绍 Double DQN与传统DQN的区别什么? 最大的区别在于Q现实的计算方法,DQN中TargetQ的计算方法是 YtDQN=Rt+1+γaQ(St+1,a;θt−)=Rt+1+γQ(St+1,aQ(St+1,a;θt),θt)Y_t^{DQN} =R_{t+1}+\gamma \max_aQ(S_{t+1},a;\th
-
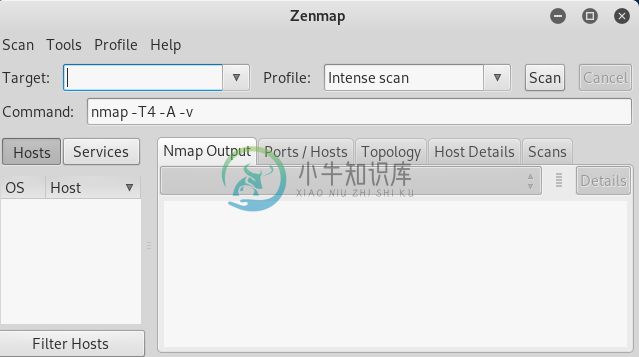 Zenmap工具
Zenmap工具Nmap(网络映射器)是我们要了解的第二个程序工具。它是一个巨大的工具,有很多用途。Nmap用于收集有关任何设备的信息。使用Nmap,我们可以收集有关网络内或网络外的任何客户的信息,我们只需知道他们的IP就可以收集有关客户的信息。Nmap可用于绕过防火墙,以及各种保护和安全措施。在本节中,我们将学习一些基本的Nmap命令,这些命令可用于发现连接到我们网络的客户端,还可以发现这些客户端上的开放端口。
-
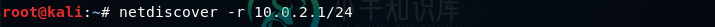 netdiscover工具
netdiscover工具netdiscover是一种用于收集有关网络的所有重要信息的工具。它收集有关已连接客户端和路由器的信息。对于连接的客户端,我们将能够知道他们的IP,MAC地址和操作系统,以及他们在其设备中打开的端口。至于路由器,它将帮助我们了解路由器的制造商。然后,如果我们试图破解它们,我们将能够查找可以用于客户端或路由器的漏洞。 在网络渗透测试中,我们使用来发现所有连接到网络的客户端。在输出的第二部分中,我们了
-
Kafka工具
主要内容:复制工具Kafka工具包装在下。 工具分为系统工具和复制工具。 系统工具 系统工具可以使用脚本从命令行运行。 语法如下 - 下面提到了一些系统工具 - Kafka迁移工具 - 此工具用于将代理从一个版本迁移到另一个版本。 Mirror Maker - 此工具用于将一个Kafka集群镜像到另一个。 消费者偏移量检查器 - 此工具显示指定的一组主题和使用者组的消费者组,主题,分区,偏移量,日志大小,所有者。