
如何使用plotly.graph_objects和plotly.express?定义图形中的颜色

有许多问题和答案以这样或那样的方式涉及到这个话题。有了这篇文章,我想清楚地说明为什么像marker={'color':'red'}这样的简单方法将适用于绘图。图形对象(go),但color='red'不会用于绘图。express(px)尽管颜色是两者的属性。行和px。散布。我想向大家展示一下为什么它不是那么棒。
所以,如果px被认为是最简单的方法来绘制一个具体的数字,那么为什么像Color='red'这样明显的东西会返回错误
颜色的值不是data_frame中的列的名称。
简而言之,这是因为px中的颜色不接受任意的颜色名称或代码,而是数据集中的变量名称,以便将颜色周期分配给唯一的值,并将其显示为以下行不同的颜色。
让我通过应用gapminder数据集进行演示,并展示截至2007年全球所有(至少大多数)国家的预期寿命与人均GDP的散点图。如下所示的基本设置将生成以下绘图
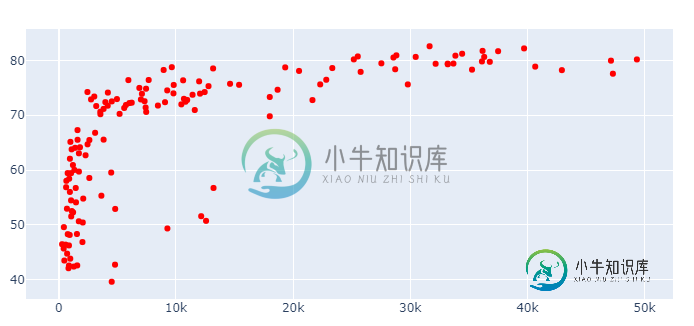
颜色由名为plotly的循环设置,但此处使用marker={'color':'red'}
import plotly.graph_objects as go
df = px.data.gapminder()
df=df.query("year==2007")
fig = go.Figure()
fig.add_traces(go.Scatter(x=df['gdpPercap'], y=df["lifeExp"],
mode = 'markers',
marker = {'color' : 'red'}
))
fig.show()
所以让我们用px试试这个,并假设Color='red'可以做到这一点:
# imports
import plotly.express as px
import pandas as pd
# dataframe
df = px.data.gapminder()
df=df.query("year==2007")
# plotly express scatter plot
px.scatter(df, x="gdpPercap", y="lifeExp",
color = 'red',
)
颜色的值不是data_frame中的列的名称。预期是[的“国家”、“大陆”、“年份”、“生活经历”、“流行”、“gdpPercap”、“iso_alpha”、“iso_num”中的一个,但收到了:红色
这是怎么回事?
共有1个答案

首先,如果需要解释go和px之间更广泛的差异,请看看这里和这里。如果完全不需要解释,你会在答案的最后找到一个完整的代码片段,它将揭示许多具有颜色的plotly.express
一开始可能不是这样,但是有很好的理由说明color='red'不能像您使用px所期望的那样工作。但首先,如果您只想手动为所有标记设置一种特定的颜色,那么可以使用。更新跟踪(marker=dict(color='red'))多亏了pythons链接方法。但首先,让我们看看deafult设置:
# imports
import plotly.express as px
import pandas as pd
# dataframe
df = px.data.gapminder()
df=df.query("year==2007")
# plotly express scatter plot
px.scatter(df, x="gdpPercap", y="lifeExp")
这里,正如问题中已经提到的,颜色被设置为通过px可用的默认绘图顺序中的第一种颜色。颜色。质量的详细地:
['#636EFA', # the plotly blue you can see above
'#EF553B',
'#00CC96',
'#AB63FA',
'#FFA15A',
'#19D3F3',
'#FF6692',
'#B6E880',
'#FF97FF',
'#FECB52']
看起来很不错。但是,如果您想更改内容,甚至同时添加更多信息,该怎么办?
正如我们已经提到的px.scatter,颜色属性不接受像red这样的颜色作为参数。相反,您可以例如使用颜色='大陆'来轻松区分数据集中的不同变量。但是px中的颜色还有很多:
以下六种方法的结合将让你用具体的表达方式来做你想做的事情。请记住,你甚至不必选择。您可以同时使用下面的一个、一些或所有方法。一种特别有用的方法将显示为1和3的组合。但我们一会儿就会谈到这一点。这是你需要知道的:
1.更改px使用的颜色序列:
color_discrete_sequence=px.colors.qualitative.Alphabet
2.使用color参数为不同的变量指定不同的颜色
color = 'continent'
自定义一个或多个可变颜色
color_discrete_map={"Asia": 'red'}
4.轻松组一个更大的子集,你的变量,使用判决理解和color_discrete_map
subset = {"Asia", "Africa", "Oceania"}
group_color = {i: 'red' for i in subset}
5.设置不透明度使用rgba()颜色代码。
color_discrete_map={"Asia": 'rgba(255,0,0,0.4)'}
6.使用以下命令覆盖所有设置:
.update_traces(marker=dict(color='red'))
以下片段将生成下图,显示各大洲在不同GDP水平下的预期寿命。标记的大小代表了不同水平的人群,从一开始就让事情变得更有趣。
import plotly.express as px
import pandas as pd
# dataframe, input
df = px.data.gapminder()
df=df.query("year==2007")
px.scatter(df, x="gdpPercap", y="lifeExp",
color = 'continent',
size='pop',
)
为了说明上述方法的灵活性,让我们首先改变颜色序列。因为我们的初学者只显示一个类别和一种颜色,你必须等待后续步骤才能看到真正的效果。但是这里是与第1步相同的color_discrete_sequence=px.colors.qualitative.Alphabet:
1.将px使用的颜色顺序更改为
color_discrete_sequence=px.colors.qualitative.Alphabet
现在,让我们将Alphabet颜色序列中的颜色应用到不同的大陆:
2.使用color参数为不同的变量指定不同的颜色
color = 'continent'
如果你和我一样,认为这种特定的颜色序列看起来很简单,但可能有点难以区分,你可以将自己选择的颜色分配给一个或多个大陆,如下所示:
自定义一个或多个可变颜色
color_discrete_map={"Asia": 'red'}
这真是太棒了:现在你可以改变序列,为特别有趣的变量选择任何你喜欢的颜色。但是,如果您想将特定颜色指定给更大的子集,上述方法可能会变得有点乏味。下面是你如何通过听写理解来做到这一点:
4.为一个组分配颜色使用一个判决理解和color_discrete_map
# imports
import plotly.express as px
import pandas as pd
# dataframe
df = px.data.gapminder()
df=df.query("year==2007")
subset = {"Asia", "Europe", "Oceania"}
group_color = {i: 'red' for i in subset}
# plotly express scatter plot
px.scatter(df, x="gdpPercap", y="lifeExp",
size='pop',
color='continent',
color_discrete_sequence=px.colors.qualitative.Alphabet,
color_discrete_map=group_color
)
5.设置不透明度使用rgba()颜色代码。
现在让我们后退一步。如果你认为red很适合亚洲,但是可能有点太强了,你可以使用rgba颜色来调整不透明度,比如'rgba(255,0,0,0.4)'
import plotly.express as px
import pandas as pd
# dataframe, input
df = px.data.gapminder()
df=df.query("year==2007")
px.scatter(df, x="gdpPercap", y="lifeExp",
color_discrete_sequence=px.colors.qualitative.Alphabet,
color = 'continent',
size='pop',
color_discrete_map={"Asia": 'rgba(255,0,0,0.4)'}
)
如果您认为我们现在变得有点太复杂了,您可以再次覆盖所有类似的设置:
6.使用以下命令覆盖所有设置:
.update_traces(marker=dict(color='red'))
这让我们回到了我们开始的地方。我希望你会发现这个有用!
# imports
import plotly.express as px
import pandas as pd
# dataframe
df = px.data.gapminder()
df=df.query("year==2007")
subset = {"Asia", "Europe", "Oceania"}
group_color = {i: 'red' for i in subset}
# plotly express scatter plot
px.scatter(df, x="gdpPercap", y="lifeExp",
size='pop',
color='continent',
color_discrete_sequence=px.colors.qualitative.Alphabet,
#color_discrete_map=group_color
color_discrete_map={"Asia": 'rgba(255,0,0,0.4)'}
)#.update_traces(marker=dict(color='red'))
-
我正在使用IText7从html字符串生成pdf。现在,我需要对段落应用自定义颜色和自定义字体或字体系列。 如何使用Itext7实现这一点? 谢谢
-
我希望这个图中的条形图有我自己选择的不同颜色。我不想使用随机的颜色为酒吧(或一组酒吧)。
-
类似 (https://www.visactor.io/vchart/demo/pie-chart/basic-pie)这样的饼图,图例的图像、颜色、内容可以自定义?如何自定义配置?
-
所以我最终只是按顺序添加项目,一个游戏板的表层,上面的瓷砖,然后放置在瓷砖中的游戏令牌。 智慧的话语和优秀的链接是最受欢迎的。提前谢了。
-
我正在尝试使用ChartJS创建一个条形图,如下所示: 我想知道如何分别为每个条添加渐变颜色,并根据它们的高度添加渐变颜色。 我在这里找到了一个非常接近的解决方案,但它为整个图形设置了,而不是单个条。 另外,如果我为每个条创建渐变,这个解决方案更接近,但是,我想根据条的高度设置渐变。 有没有办法指定根据酒吧高度,而不是坐标上的
-
问题内容: 我想设置色彩图的中间点,即我的数据从-5到10,我希望零成为中间点。我认为实现此目的的方法是归一化规范化并使用规范,但是我没有找到任何示例,我也不清楚我到底要实现什么。 问题答案: 请注意,在matplotlib 3.1版中,添加了DivergingNorm类。我认为它涵盖了您的用例。可以这样使用: 在matplotlib 3.2中,该类已重命名为TwoSlopesNorm
-
我在这里学习python教程:https://plotly.com/python/gantt/ 上面教程中的代码给了我图表: 请注意,有两个事件。 我想为每个开始和结束交替颜色。例如第一事件红色、第二事件蓝色、第三事件红色、第四事件蓝色等。 我已经尝试了和参数,但是颜色不交替。 我所尝试的: 和 有什么关于如何交替颜色的想法吗? 我希望A工作看起来像什么的一个例子:
-
本节,我们将绘制四个三角形,并用不同的填充样式来填充每个三角形。HTML5的画布API提供的填充样式有颜色、线性渐变、径向渐变和图案。 图2-3 绘制自定义填充样式 按照以下步骤绘制4个三角形,一个使用颜色填充、一个使用线性渐变填充、一个使用径向渐变填充、一个使用图案填充: 1. 创建一个简单的函数,该函数绘制一个矩形: function drawTriangle(context, x, y,