
熊猫分组按同时添加和平均[重复]

我有一个数据框架,其中包含进程列表和它们所花费的时间,如下所示

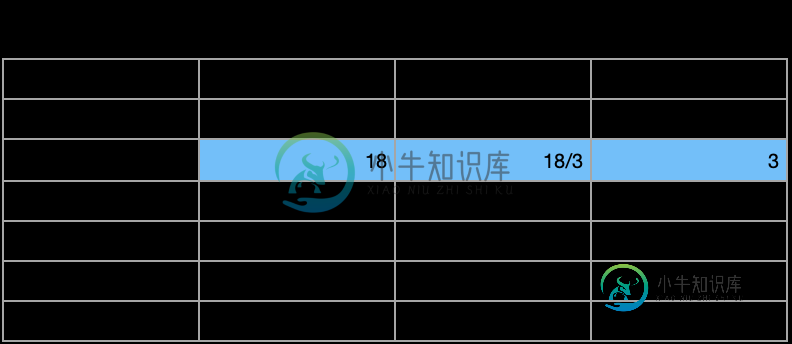
我想得到以下结果
我知道如何使用gorupby以获得ONE,但只获得其中一个列。这就是我解决问题的方法
# the data
ps = ['p1','p2','p3','p4','p2','p2','p3','p6','p2','p4','p5','p6']
times = [20,10,2,3,4,5,6,3,4,5,6,7]
processes = pd.DataFrame({'ps':ps,'time':times})
# the series
dfsum = processes.groupby('PROCESS')['TIME'].sum()
dfcount = processes.groupby('PROCESS')['TIME'].count()
# "building" the df result
frame = { 'total_time': dfsum, 'total_nr': dfcount}
dfresult = pd.DataFrame(frame)
dfresult['average']= dfresult['total_time']/dfresult['total_nr']
dfresult
但是,如何获得所需的df而不必一列一列地组合它呢?对我来说,这种方法还不够“泛音速”(也不够pythonic)
共有2个答案

尝试groupby.agg():
df.groupby('PROCESS')['TIME'].agg(['sum','mean','count'])
样本数据的输出:
sum mean count
ps
p1 20 20.00 1
p2 23 5.75 4
p3 8 4.00 2
p4 8 4.00 2
p5 6 6.00 1
p6 10 5.00 2

processes.groupby('ps').agg(TOTAL_TIME=('time','sum'),AVARAGE=('time','mean'),NRTIMES=('time','size'))
-
我是新来的。任何帮助都将不胜感激 这是我的原始数据: 我想得到的是: 1创建一个新的列调用平均值,以计算每个提要的平均市值。 2求加权平均数。 这是我当前的代码,我得到NaN: 对于加权平均代码: 我得到了一个错误: AttributeError:“Series”对象没有属性“value”
-
问题内容: 我有一个数据框 我需要的是Adjusted_lots,price和ajusted_lots的加权平均价格之和,并按所有其他列进行分组,即。按(合同,月,年和购买)分组 R的类似解决方案是使用dplyr通过以下代码实现的,但是在熊猫中却无法做到这一点。 groupby或任何其他解决方案是否可能相同? 问题答案: 编辑: 更新聚合,以便它与熊猫的最新版本一起使用 要将多个函数传递给grou
-
我想得到这样的东西 我用groupby关键字搜索了stackoverflow,没有找到与我类似的问题。
-
问题内容: 我无法获得熊猫列的平均值或均值。有一个数据框。我在下面尝试的任何事情都没有给我该列的平均值 以下返回几个值,而不是一个: 这样: 问题答案: 如果您只想要列的均值,请选择列(这是一个系列),然后调用:
-
我不能得到熊猫的平均值或平均值。有一个数据框。下面我尝试的东西都没有给我列的平均值 以下内容返回多个值,而不是一个值: 这也是:
-
我有以下数据框: 我需要按年和月分组数据。即:按2013年1月、2013年2月、2013年3月等分组...我将使用新分组的数据来创建一个显示每年/每月abc vs xyz的图表。 我尝试过groupby和sum的各种组合,但似乎没有任何效果。 谢谢你的帮助。