
错误:序列的真值不明确。使用a.empty、a.bool()、a.item()、a.any()或a.all()

distdf=pd.DataFrame(dist)
for i in range(len(distdf)):
if distdf.loc[i]==distdf.loc[i+1]:
print("true")
else:
print('no')
但我有一个错误。
ValueError:序列的真值不明确。使用a.empty、a.bool()、a.item()、a.any()或a.all()。
我怎样才能修好它?
共有3个答案

dist =[1,2,3,4,5,6]
distdf = pd.DataFrame(dist)
for i in range(len(distdf)-1):
res = distdf.loc[i].values==distdf.loc[i].values
if True in res:
print("true")
else:
print('no')

尽管您只有一列,distdf.loc[i]仍然是Pandas Series对象,而不仅仅是包含在唯一列中的整数,因此会出现错误。
您可以使用.values比较单个列中每个单元格的值,以避免出现此错误:
# you also need to use len(distdf)-1 and not len(distdf)
for i in range(len(distdf)-1):
if distdf.loc[i].values == distdf.loc[i+1].values:
print("true")
else:
print('no')

您的代码失败,因为distdf.loc[i]==distdf.loc[i 1]尝试比较整行,即两个Series对象。
如果您编写:如果distdf.loc[i,'distince']==distdf.loc[i 1,'distince']:,即比较每一行(当前行和下一行)中的distince元素,则会有一些改进。
但是这段代码在循环的最后一轮也会失败,因为当你“停留”在最后一行时,就没有下一行了,所以会引发KeyError异常。
有一种更简单、更泛泛的方法来获取您的值列表,而不需要任何循环。
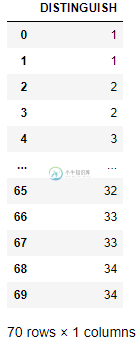
假设您的数据帧(distdf)包含:
DISTINGUISH
0 1
1 1
2 2
3 2
4 3
5 3
6 32
7 32
8 33
9 33
10 34
11 34
由于您想对其唯一的列进行操作,为了保持代码简短,让我们将其保存在col0下:
col0 = distdf.iloc[:, 0]
然后,要获得没有任何循环的值列表,请运行:
np.where(col0 == col0.shift(-1), 'true', 'no')
上述数据的结果为:
array(['true', 'no', 'true', 'no', 'true', 'no', 'true', 'no', 'true',
'no', 'true', 'no'], dtype='<U4')
-
当我运行以下代码时: 它给出了以下错误: ValueError:序列的真值不明确。 使用a.empty、a.bool()、a.item()、a.any()或a.all() 这里怎么了?
-
我有一个数据帧“信号”: 因为我需要一些条件来设置我的“\u exec\u dict”,这是一个告诉交易平台我的订单是什么的字典? 问题是我不能使用 来做条件判定。 要进行测试,请执行以下操作: 有一些改变, 结果是: 搜索后,像一个系列的真相值是模糊的。使用a.empty、a.bool()、a.item()、a.any()或a.all()
-
问题内容: 在用or条件过滤我的结果数据帧时遇到问题。我希望我的结果df提取var大于0.25且小于-0.25的所有列值。 下面的逻辑为我提供了一个模糊的真实值,但是当我将此过滤分为两个单独的操作时,它可以工作。这是怎么回事 不知道在哪里使用建议。 问题答案: 在和python语句需要-值。因为这些被认为是模棱两可的,所以您应该使用“按位” (或)或(和)操作: 对于此类数据结构,它们会重载以生成
-
问题内容: 在用条件过滤我的结果数据帧时遇到问题。我希望我的结果提取大于0.25且小于的所有列值。 下面的逻辑为我提供了一个模糊的真实值,但是当我将此过滤分为两个单独的操作时,它起作用。这是怎么回事 不知道在哪里使用建议。 问题答案: 在和python语句需要值。因为这些被认为是模棱两可的,所以你应该使用操作: 对于此类数据结构,它们会重载以产生元素级(或)。 只是为该语句添加更多解释: 当你想获
-
我使用如果条件在python执行计算,但我得到的真值系列是含糊不清的。使用a.empty、a.bool()、a.item()、a.any()或a.all() 有人能帮助我理解如何基于其他列上的if条件对数据帧执行操作吗? 附件是代码和错误的图像