
OpenCV-来自未校准立体系统的深度图

我正在尝试用未校准的方法得到深度图。我可以通过SIFT找到对应的点,然后使用cv2.findgatilatalmat得到基本矩阵。然后使用cv2.stereorretifyuncalibrated来获得每个图像的单应矩阵。最后,我使用cv2.warpperspective来校正和计算视差,但这并不能创建一个好的深度图。这些值非常高,所以我想知道是否必须使用warpperspective,或者是否必须从使用stereorctifyuncalibrated得到的单应矩阵计算旋转矩阵。
我不确定用stereorctifyuncalibrated校正得到的单应矩阵的投影矩阵。
代码的一部分:
#Obtainment of the correspondent point with SIFT
sift = cv2.SIFT()
###find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(dst1,None)
kp2, des2 = sift.detectAndCompute(dst2,None)
###FLANN parameters
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
good = []
pts1 = []
pts2 = []
###ratio test as per Lowe's paper
for i,(m,n) in enumerate(matches):
if m.distance < 0.8*n.distance:
good.append(m)
pts2.append(kp2[m.trainIdx].pt)
pts1.append(kp1[m.queryIdx].pt)
pts1 = np.array(pts1)
pts2 = np.array(pts2)
#Computation of the fundamental matrix
F,mask= cv2.findFundamentalMat(pts1,pts2,cv2.FM_LMEDS)
# Obtainment of the rectification matrix and use of the warpPerspective to transform them...
pts1 = pts1[:,:][mask.ravel()==1]
pts2 = pts2[:,:][mask.ravel()==1]
pts1 = np.int32(pts1)
pts2 = np.int32(pts2)
p1fNew = pts1.reshape((pts1.shape[0] * 2, 1))
p2fNew = pts2.reshape((pts2.shape[0] * 2, 1))
retBool ,rectmat1, rectmat2 = cv2.stereoRectifyUncalibrated(p1fNew,p2fNew,F,(2048,2048))
dst11 = cv2.warpPerspective(dst1,rectmat1,(2048,2048))
dst22 = cv2.warpPerspective(dst2,rectmat2,(2048,2048))
#calculation of the disparity
stereo = cv2.StereoBM(cv2.STEREO_BM_BASIC_PRESET,ndisparities=16*10, SADWindowSize=9)
disp = stereo.compute(dst22.astype(uint8), dst11.astype(uint8)).astype(np.float32)
plt.imshow(disp);plt.colorbar();plt.clim(0,400)#;plt.show()
plt.savefig("0gauche.png")
#plot depth by using disparity focal length `C1[0,0]` from stereo calibration and `T[0]` the distance between cameras
plt.imshow(C1[0,0]*T[0]/(disp),cmap='hot');plt.clim(-0,500);plt.colorbar();plt.show()

以下是用校准方法校正的图片:
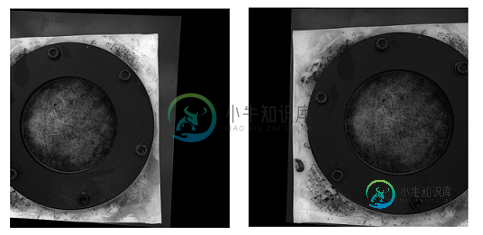
我不知道这两种图片之间的差别是怎么这么重要的。而对于校准的方法来说,它似乎并不对齐。
使用未校准方法的视差图:
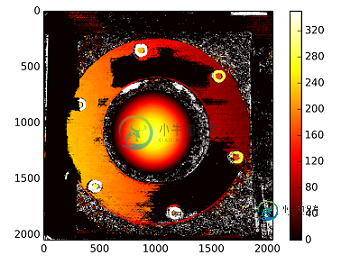
---------以后编辑----------
Y=np.arange(0,2048)
X=np.arange(0,2048)
(XX_field,YY_field)=np.meshgrid(X,Y)
#I mount the X, Y and disparity in a same 3D array
stock = np.concatenate((np.expand_dims(XX_field,2),np.expand_dims(YY_field,2)),axis=2)
XY_disp = np.concatenate((stock,np.expand_dims(disp,2)),axis=2)
XY_disp_reshape = XY_disp.reshape(XY_disp.shape[0]*XY_disp.shape[1],3)
Ts = np.hstack((np.zeros((3,3)),T_0)) #i use only the translations obtained with the rectified calibration...Is it correct?
# I establish the projective matrix with the homography matrix
P11 = np.dot(rectmat1,C1)
P1 = np.vstack((np.hstack((P11,np.zeros((3,1)))),np.zeros((1,4))))
P1[3,3] = 1
# P1 = np.dot(C1,np.hstack((np.identity(3),np.zeros((3,1)))))
P22 = np.dot(np.dot(rectmat2,C2),Ts)
P2 = np.vstack((P22,np.zeros((1,4))))
P2[3,3] = 1
lambda_t = cv2.norm(P1[0,:].T)/cv2.norm(P2[0,:].T)
#I define the reconstruction matrix
Q = np.zeros((4,4))
Q[0,:] = P1[0,:].T
Q[1,:] = P1[1,:].T
Q[2,:] = lambda_t*P2[1,:].T - P1[1,:].T
Q[3,:] = P1[2,:].T
#I do the calculation to get my 3D coordinates
test = []
for i in range(0,XY_disp_reshape.shape[0]):
a = np.dot(inv(Q),np.expand_dims(np.concatenate((XY_disp_reshape[i,:],np.ones((1))),axis=0),axis=1))
test.append(a)
test = np.asarray(test)
XYZ = test[:,:,0].reshape(XY_disp.shape[0],XY_disp.shape[1],4)
共有1个答案

OP没有提供原始图像,所以我使用的是来自Middlebury数据集的tsukuba。
详情请参阅此处的出版物。
你校准的校正图像的大面积黑色区域会让我相信,对于那些,校准做得不是很好。有各种各样的原因可能在起作用,也许是物理设置,也许是当你做校准时的照明,等等,但有很多相机校准教程在那里,我的理解是,你是在要求一种方法,以获得一个更好的深度图,从一个未校准的设置(这不是100%清楚,但标题似乎支持这一点,我认为这是人们将在这里试图找到)。
您使用StereoBM来计算视差(深度图),这确实有效,但是StereoSGBM更适合这个应用程序(它更好地处理更平滑的边缘)。你可以看到下面的区别。
本文更深入地解释了其中的差异:
块匹配侧重于高纹理图像(想象一张树的图片),半全局块匹配将侧重于亚像素级匹配和纹理更平滑的图片(想象一张走廊的图片)。
-
null
这个结果看起来更好,使用了与OP大致相同的方法,减去最后的视差计算,使我认为OP将看到他的图像类似的改进,如果他们提供了。
OpenCV文档中有一篇关于这一点的好文章。如果你需要非常平滑的地图,我建议你看看它。
import cv2
import numpy as np
import matplotlib.pyplot as plt
imgL = cv2.imread("tsukuba_l.png", cv2.IMREAD_GRAYSCALE) # left image
imgR = cv2.imread("tsukuba_r.png", cv2.IMREAD_GRAYSCALE) # right image
def get_keypoints_and_descriptors(imgL, imgR):
"""Use ORB detector and FLANN matcher to get keypoints, descritpors,
and corresponding matches that will be good for computing
homography.
"""
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(imgL, None)
kp2, des2 = orb.detectAndCompute(imgR, None)
############## Using FLANN matcher ##############
# Each keypoint of the first image is matched with a number of
# keypoints from the second image. k=2 means keep the 2 best matches
# for each keypoint (best matches = the ones with the smallest
# distance measurement).
FLANN_INDEX_LSH = 6
index_params = dict(
algorithm=FLANN_INDEX_LSH,
table_number=6, # 12
key_size=12, # 20
multi_probe_level=1,
) # 2
search_params = dict(checks=50) # or pass empty dictionary
flann = cv2.FlannBasedMatcher(index_params, search_params)
flann_match_pairs = flann.knnMatch(des1, des2, k=2)
return kp1, des1, kp2, des2, flann_match_pairs
def lowes_ratio_test(matches, ratio_threshold=0.6):
"""Filter matches using the Lowe's ratio test.
The ratio test checks if matches are ambiguous and should be
removed by checking that the two distances are sufficiently
different. If they are not, then the match at that keypoint is
ignored.
https://stackoverflow.com/questions/51197091/how-does-the-lowes-ratio-test-work
"""
filtered_matches = []
for m, n in matches:
if m.distance < ratio_threshold * n.distance:
filtered_matches.append(m)
return filtered_matches
def draw_matches(imgL, imgR, kp1, des1, kp2, des2, flann_match_pairs):
"""Draw the first 8 mathces between the left and right images."""
# https://docs.opencv.org/4.2.0/d4/d5d/group__features2d__draw.html
# https://docs.opencv.org/2.4/modules/features2d/doc/common_interfaces_of_descriptor_matchers.html
img = cv2.drawMatches(
imgL,
kp1,
imgR,
kp2,
flann_match_pairs[:8],
None,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS,
)
cv2.imshow("Matches", img)
cv2.imwrite("ORB_FLANN_Matches.png", img)
cv2.waitKey(0)
def compute_fundamental_matrix(matches, kp1, kp2, method=cv2.FM_RANSAC):
"""Use the set of good mathces to estimate the Fundamental Matrix.
See https://en.wikipedia.org/wiki/Eight-point_algorithm#The_normalized_eight-point_algorithm
for more info.
"""
pts1, pts2 = [], []
fundamental_matrix, inliers = None, None
for m in matches[:8]:
pts1.append(kp1[m.queryIdx].pt)
pts2.append(kp2[m.trainIdx].pt)
if pts1 and pts2:
# You can play with the Threshold and confidence values here
# until you get something that gives you reasonable results. I
# used the defaults
fundamental_matrix, inliers = cv2.findFundamentalMat(
np.float32(pts1),
np.float32(pts2),
method=method,
# ransacReprojThreshold=3,
# confidence=0.99,
)
return fundamental_matrix, inliers, pts1, pts2
############## Find good keypoints to use ##############
kp1, des1, kp2, des2, flann_match_pairs = get_keypoints_and_descriptors(imgL, imgR)
good_matches = lowes_ratio_test(flann_match_pairs, 0.2)
draw_matches(imgL, imgR, kp1, des1, kp2, des2, good_matches)
############## Compute Fundamental Matrix ##############
F, I, points1, points2 = compute_fundamental_matrix(good_matches, kp1, kp2)
############## Stereo rectify uncalibrated ##############
h1, w1 = imgL.shape
h2, w2 = imgR.shape
thresh = 0
_, H1, H2 = cv2.stereoRectifyUncalibrated(
np.float32(points1), np.float32(points2), F, imgSize=(w1, h1), threshold=thresh,
)
############## Undistort (Rectify) ##############
imgL_undistorted = cv2.warpPerspective(imgL, H1, (w1, h1))
imgR_undistorted = cv2.warpPerspective(imgR, H2, (w2, h2))
cv2.imwrite("undistorted_L.png", imgL_undistorted)
cv2.imwrite("undistorted_R.png", imgR_undistorted)
############## Calculate Disparity (Depth Map) ##############
# Using StereoBM
stereo = cv2.StereoBM_create(numDisparities=16, blockSize=15)
disparity_BM = stereo.compute(imgL_undistorted, imgR_undistorted)
plt.imshow(disparity_BM, "gray")
plt.colorbar()
plt.show()
# Using StereoSGBM
# Set disparity parameters. Note: disparity range is tuned according to
# specific parameters obtained through trial and error.
win_size = 2
min_disp = -4
max_disp = 9
num_disp = max_disp - min_disp # Needs to be divisible by 16
stereo = cv2.StereoSGBM_create(
minDisparity=min_disp,
numDisparities=num_disp,
blockSize=5,
uniquenessRatio=5,
speckleWindowSize=5,
speckleRange=5,
disp12MaxDiff=2,
P1=8 * 3 * win_size ** 2,
P2=32 * 3 * win_size ** 2,
)
disparity_SGBM = stereo.compute(imgL_undistorted, imgR_undistorted)
plt.imshow(disparity_SGBM, "gray")
plt.colorbar()
plt.show()
-
目标 在这个章中,我们将学习从立体图像创建深度图。 基本 在上一章中,我们看到了极线约束等相关术语的基本概念。我们也看到,如果我们有两个相同的场景图像,我们可以直观地从中获取深度信息。 上图包含全等三角形。写出它们的等价方程将得到以下结果: $$ disparity = x - x' = \frac{Bf}{Z} $$ $x$ 和 $x'$ 是对应于场景点 3D 的图像平面中的点与其相机中心之间的
-
立体图像的深度图 作者|OpenCV-Python Tutorials 编译|Vincent 来源|OpenCV-Python Tutorials 目标 在本节中, 我们将学习根据立体图像创建深度图。 基础 在上一节中,我们看到了对极约束和其他相关术语等基本概念。我们还看到,如果我们有两个场景相同的图像,则可以通过直观的方式从中获取深度信息。下面是一张图片和一些简单的数学公式证明了这种想法。 上图
-
如果我已经在实验中计算了相机的本质(相机矩阵和畸变系数)。 然后我把摄像机移到了现实世界的领域。我使用了现实世界中大约6-10个已知的位置,使用SolvePnP()估计相机姿态。所以我也有两个相机旋转和平移。 既然我有两个相机的相机姿态,那么我可以简单地减去我从SolvePnP得到的两个平移向量和旋转向量,并将结果传递给Stereotrety()吗?(两台摄像机使用相同的公共物点参考系)
-
问题内容: 有什么方法可以从存储库中获取OpenCV?我应该添加到哪个工件?我发现的每个教程都是从‘14开始的,似乎有所更改- 他们说它尚未在Maven官方存储库中,但我找到了条目: 可悲的是,我得到了错误 当我使用。我可以以一种使我的项目包含它的方式添加该库,而不必手动将其添加到类路径中的方法吗? 问题答案: 这对我有用。 我正在使用以下Maven依赖项
-
如果船长的终极目标是保护船只,他应该永远待在港口。 ——圣托马斯·阿奎那《神学大全》(1265-1274) [TOC] 到目前为止,本书主要描述的是现状。在这最后一章中,我们将放眼未来,讨论应该是怎么样的:我将提出一些想法与方法,我相信它们能从根本上改进我们设计与构建应用的方式。 对未来的看法与推测当然具有很大的主观性。所以在撰写本章时,当提及我个人的观点时会使用第一人称。您完全可以不同意
-
我有一个表,它有一个主键,这个主键是用table Generator生成的: @tablegenerator(name=“resourceidgenerator”,table=“sequence”,pkColumnName=“name”,pkColumnValue=“resource_type_id”,valueColumnName=“nextid”,allocationSize=1),它工作得很