
Python将熊猫数字向量列拆分为多个列[重复]

我有一个熊猫的数据框,有一列是向量:
df = pd。DataFrame([1,2], “平均值”:[[1,2,3],[4,5,6]]})

我想把它拆分成这样的元素:
df2=pd.DataFrame({'ID':[1,2],'A':[1,4],'B':[2,5],'C':[3,6]})
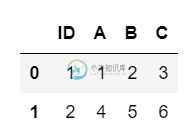
我试过df['Averages']. astype(str).str.split (' ')但是没有运气.任何帮助将不胜感激。
共有2个答案

这将起作用:
df[['A','B','C']] = pd.DataFrame(df.averages.values.tolist(), index= df.index)

pd.concat([df['ID'], df['Averages'].apply(pd.Series)], axis = 1).rename(columns = {0: 'A', 1: 'B', 2: 'C'})
-
我有一个数据帧: 如何拆分该列,使每个值都在自己的列中? 我找到的唯一答案是关于将一列拆分成两列。如何将一列拆分成两列?
-
我的问题是如何将一列拆分为多个列。我不知道为什么 不起作用。 例如,我想将“df_test”更改为“df_test2”。我看到了很多使用熊猫模块的例子。还有别的办法吗?提前感谢您。 df_test2
-
我正在与以下df合作: 我想强制所有年份的数字: 有没有一个简单的方法来做这件事,还是我必须把它们全部打印出来?
-
我有一个这样的专栏: 现在我想在dot在列中如下所示:
-
我有一个包含字典作为元素的单列的。这是以下代码的结果: 我需要将此列拆分为尽可能多的列(我有太多的行和列,并且我无法更改函数),因此输出将是一个包含列,,的数据帧,<代码>功能50。这样做的最佳方式是什么? 一个具体而简单的例子: 但当我尝试用pd.Series或pd.DataFrame包装它时,它说如果数据是标量值,则必须提供索引。提供索引=['feature1','feature2'],我会得
-
我正在处理一个大的csv文件,下一列的最后一列有一个文本字符串,我想用一个特定的分隔符来分割。我想知道是否有一种简单的方法可以使用pandas或python来实现这一点? 我想按空格分割,然后按列中的冒号分割,但是每个单元格将导致不同数量的列。我有一个重新排列列的函数,所以列在工作表的末尾,但是我不确定从那里做什么。我可以在excel中使用内置的函数和一个快速宏来完成,但是我的数据集有太多的记录需