
埃拉托斯汀筛选与试验分割时间复杂性

根据这个链接http://www.cs.hmc.edu/~oneill/papers/Sieve-JFP.pdf
查找具有试验除法的素数列表的时间复杂度为
n*sqrt(n)/ln(n)^2
用埃拉托色尼筛寻找质数的时间复杂度是
n*ln(ln(x))
这篇论文声称筛子比试分具有更好的时间复杂度。然而,如果我绘制这些函数,筛子显然更差:
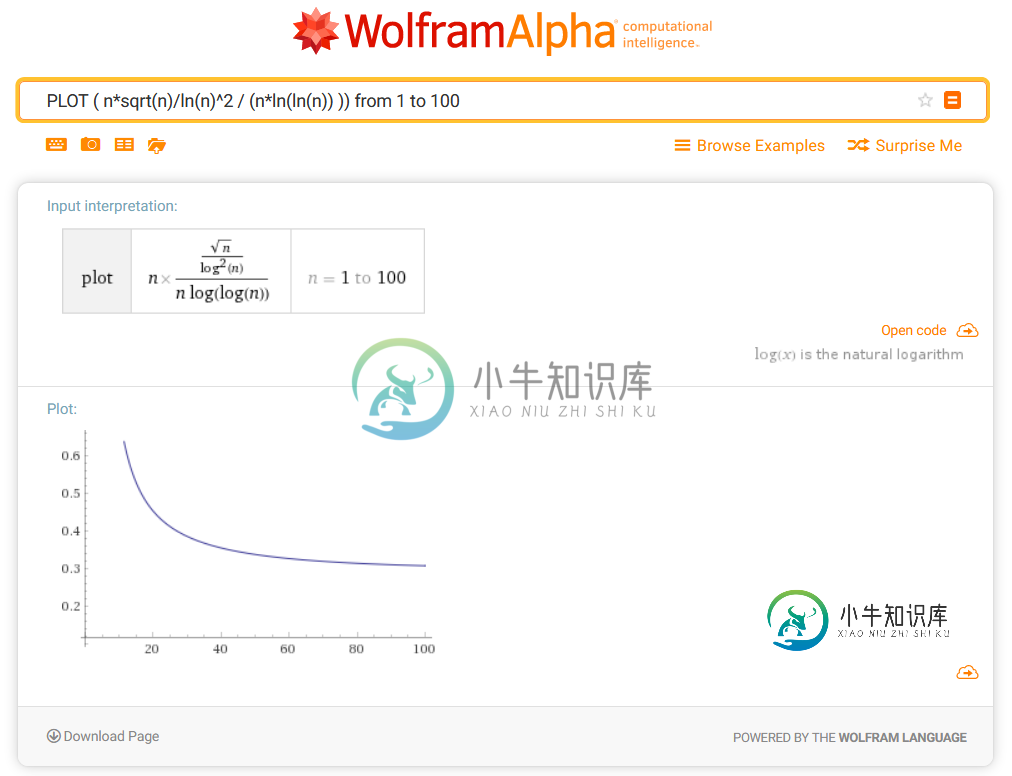
此图像是使用查询在WolframAlpha上创建的
PLOT ( n*sqrt(n)/ln(n)^2 / (n*ln(ln(n)) )) from 1 to 100
因此,仅基于大O表示法,我得出的结论是,对于任意大的n,试验除法应该更好。这个结论是正确的吗?
但是如果我改变常数,结果会改变。似乎不存在独立于常数的渐近散度。那么,根据大O符号的时间复杂度来断定哪个算法对于任意大的n更好似乎是没有用的。知道哪一个更好的唯一方法是通过比较实现。我得出了错误的结论吗?
共有3个答案

您使用的数字不够大。然后画面发生变化:
真正的答案是经济增长的经验顺序。在n的每个特定范围内,我们可以用n^aa和一些
n^1.05。现在没有混淆:
函数。试验分区约为
td n = n**1.5 / (log n)**2
se n = n * log (log n)
_a f n = log ( f (n*1.1) / f n ) / log 1.1
-- 10K 100K 1M 5M 10M 100M
Haskell> map (_a td.(*1000)) [10,100,1000,5000,10000,100000] :: [Float]
[1.2839688, 1.3269958, 1.3557304, 1.3707384, 1.3762819, 1.3917062]
Haskell> map (_a se.(*1000)) [10,100,1000,5000,10000,100000] :: [Float]
[1.0485349, 1.0353413, 1.0274352, 1.0235956, 1.0222284, 1.0185674]
无论常数是多少,n^1.4过程都不会长时间超过n^1.05过程。
最终,正如您所说,您确实需要比较实现。但您可以通过比较它们的经验(即实际测量的运行时间)本地(即您感兴趣的给定范围n)增长顺序(上面使用渐近函数模拟)来进行比较。不是函数的绝对值,尤其是未知常数因子。

>
请注意,试验部门在每一步都使用除法(与加法或乘法相比,现代处理器上的操作速度较慢),而埃拉托斯特尼筛子则不然。因此,试验除法可能具有更大的常量。另一个因素是筛子所需的空间,但这通常会更便宜。
当数量级为100时,试除法可能确实具有相当的效率。不过,从更大的角度来看:(链接)。筛子的真正用例是当您想要检查数百万个连续数字的素性时。

本文认为,筛子比试验划分具有更好的时间复杂度。然而,如果我画出这些函数,筛子显然更差。因此,仅根据大O符号,我可以得出结论,对于任意大的n,审判划分应该更好。这个结论正确吗?
不,结论是错误的,该图没有显示整个画面,因为您需要考虑常量和更大的n值的函数行为。
为了检验一个函数< code>f(n)是否比一个函数< code>g(n)渐近优越,你需要检验在无穷远处发生了什么。这可以通过以下方式实现:
lim_{n->infinity} f(n)/g(n)
现在,你有3种可能:
-
< li >极限是无穷大-
通过检查您在 wolfram alpha 上的函数,我们可以得出结论,当涉及到大 O 表示法时,第一个 - n*sqrt(n)/ln(n)^2 是“慢”的。
对于n的“小”值 - 所有赌注都是关闭的,并且大O符号对于这些情况没有信息。要对这些情况做出信息丰富的决定,您需要考虑常量和其他因素(有些是机器相关的)。对此的可靠答案不是理论上的,应该使用经验实验和统计测试来实现。
-
我正在实现一个相当快的质数生成器,我得到了一些不错的结果,在埃拉托斯特尼的筛子上进行了一些优化。特别是,在算法的初步部分,我以这种方式跳过2和3的所有倍数: 这里是一个根据埃拉托色尼筛的布尔数组。我认为这是一种只考虑质数2和3的轮式因式分解,按照模式2、4、2、4递增。. 我想做的是实现一个更大的轮子,也许考虑素数2,3和5。 我已经阅读了很多关于它的文档,但我没有看到任何使用埃拉托斯特尼筛子的实
-
做一个简单的筛子很容易: 但是当N非常大并且我无法在内存中持有这种数组时,该怎么办?我已经查找了分段筛方法,它们似乎涉及查找素数,直到sqrt(N),但我不明白它是如何工作的。如果 N 非常大(比如 10^18)怎么办?
-
我正在尝试实现筛选算法,它会询问连续数字列表的大小,并打印出该列表中的素数,但我收到了一个seg错误:11错误。 这是我的代码:
-
我正在尝试编写一个程序来实现对埃拉托西的筛选。我可以从2到任何给定的结束编号,但我们正在处理的赋值要求我们输入起始值。我完全被卡住了。我试过很多不同的代码,但它总是给我奇怪的答案。 我的起点是起始值,终点是结束值。我基本上想找到这个范围的素数。谢谢!!!
-
在一个类作业中,我被要求用Java编写Eratostenes筛选代码,我的代码效率非常低。运行时间不长,但我相当肯定,除了像我一样列出所有内容外,还有其他循环的空间。。 这是我的代码: 基本上,我所做的是将所有不是质数的元素设置为true… 所以我的主要2个问题是1。有没有办法实现一个循环,使代码更短2。如何打印此数组中所有为 true(质数)的元素
-
我在我的一个班级里做的一个作业,我们必须实现一个厄拉多塞的筛子。我已经尝试了七次来得到一个有效的代码,并且尝试了整合我研究过的许多解决方案。我终于有一个可以输出数字的了。不幸的是,它同时打印合数和质数,但不打印2。 我的代码如下: 我怀疑我的循环有问题。我修复了前两个循环的和变量,以便它从2开始打印出来,问题似乎是在我将数组初始化为true后,它没有将合数标记为。 提前感谢你的帮助。