
联合查找不相交路径压缩算法

我这个星期天要参加考试,我只想确认我正在做的事情是否正确(你知道考试让我持怀疑态度)
这就是算法的工作原理:
int Find(int x)
{ // Return the set containing x and compress the path from x to root
// First, find the root
int z = x; while (P[z] > 0) { z = P[z]; } int root = z;
// Start at x again and reset the parent // of every node on the path from x to root z = x;
while (P[z] > 0)
{ int t = P[z];
P[z] = root; // Reset Parent of z to root
z = t; }
return root; }
这就是问题所在:
回想一下为不相交集开发的算法,这些不相交集来自一组n个元素。查找使用路径压缩,联合使用排名。此外,相同等级的两棵树的联合选择与第二个参数关联的根作为新根。从一个集合S={1,2,…,10}和10个不相交子集开始,每个子集都包含一个元素。a.执行后绘制最后一组树:
Union(1,2), Union(3,4), Union(5,6), Union(1,5), Union(1,3)。
这是我对这个问题的回答:
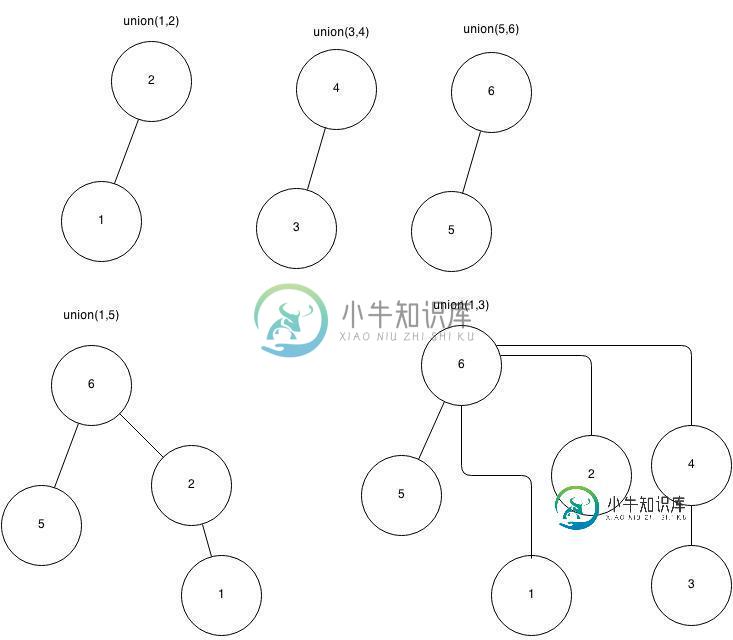
我很想有关于这个算法的任何提示或建议。
谢谢
共有1个答案

< code>Union-Find Set查找操作的关键是路径压缩。
如果我们知道集合A的根是r1,而集合B的根是<code>r2,那么将集合A和集合B连接在一起。最简单的方法是将集合B的根设为集合A的根,这意味着父亲[r2]=r1
但它并不那么“聪明”,当< code>r2的儿子,我们说< code>x,想知道它的根,< code>x问它的父亲< code>r2,然后父亲< code>r2问它自己的父亲< code>r1,blabla,直到根< code>r1。下次再次询问< code>x的根时,< code>x会询问其父< code>r1“我们的根是什么?”,则< code>r1没有必要再次重复之前的循环。由于< code>r1已经知道它的根是< code>r2,因此< code>r1可以直接将其返回给< code>x。
简而言之,x的根也是x的父亲的根。因此,我们得到了如何实现路径压缩(我认为递归更简单):
int Find(int x)
{
// initial each element's root as itself, which means father[x] = x;
// if an element finds its father is itself, means root is found
if(x == father[x])
return father[x];
int temp = father[x];
// root of x's father is same with root of x's father's root
father[x] = Find(temp);
return father[x];
}
它是极高的性能,关于路径压缩查找操作的时间复杂度,请参阅:http://www.gabrielnivasch.org/fun/inverse-ackermann
-
处理以下问题(https://leetcode.com/problems/friend-circles/): 一个班有N个学生。他们有些是朋友,有些不是。他们的友谊本质上是可传递的。比如A是B的直接好友,B是C的直接好友,那么A就是C的间接好友,而我们定义的朋友圈就是一群直接或者间接好友的同学。 给定一个N*N矩阵M,表示班级学生之间的朋友关系。如果M[i][j]=1,则第i和第j个学生是彼此的直
-
针对并集寻找不相交集的问题,提出了带路径压缩的加权快速并集算法 带路径压缩算法的加权快速并集 路径压缩会影响iz[]数组(包含以I为根的树的长度的数组)吗?
-
我有一个项目,我必须实现一个带有路径压缩算法的加权快速并集。在看到其他一些源代码后,我最终得到了这个: 分配给我的任务是正确完成以下方法: int find(int v) void unite(int v,int u) setCount(int v) 嗯,算法似乎很慢,我找不到合适的解决方案。
-
主要内容:UnionFind3.java 文件代码:并查集里的 find 函数里可以进行路径压缩,是为了更快速的查找一个点的根节点。对于一个集合树来说,它的根节点下面可以依附着许多的节点,因此,我们可以尝试在 find 的过程中,从底向上,如果此时访问的节点不是根节点的话,那么我们可以把这个节点尽量的往上挪一挪,减少数的层数,这个过程就叫做路径压缩。 如下图中,find(4) 的过程就可以路径压缩,让数的层数更少。 节点 4 往上寻找根节点时,压缩
-
根据Princeton booksite,带有路径压缩的加权快速联合将10^9联合对10^9对象的操作时间从一年减少到大约6秒。这个数字是怎么得出的?当我在10^8操作中运行下面的代码时,我的运行时间是61s。
-
我正在为联合/查找结构实现快速联合算法。在“Java中的算法”一书网站上给出的实现中,普林斯顿实现在实现路径压缩(在方法中)时无法保持树的大小不变。这不应该对算法产生不利影响吗?还是我错过了什么?另外,如果我是对的,我们将如何修改大小数组?