
非平衡面板数据:如何使用时间序列分裂交叉验证?

我目前正在处理一个巨大的不平衡数据集,并想知道是否有可能使用sklearn的时间序列分裂交叉验证来将我的训练样本分裂成几个“折叠”。我希望每个褶皱只包含在特定褶皱的时间框架内的横截面观察。
如前所述,我正在使用一个非平衡面板数据集,它利用了Pandas的多索引。这里有一个可重复的例子来提供更多的直觉:
arrays = [np.array(['A', 'A', 'A', 'B', 'B', 'C', 'C', 'D', 'D', 'D', 'D']),
np.array(['2000-01', '2000-02', '2000-03', '1999-12', '2000-01',
'2000-01', '2000-02', '1999-12', '2000-01', '2000-02', '2000-03'])]
s = pd.DataFrame(np.random.randn(11, 4), index=arrays)
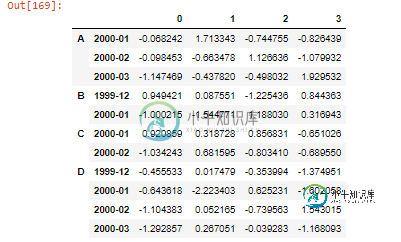
例如,我希望最初将1999-12年的所有横截面单元作为训练样本,并将2000-01年的所有横截面单元作为验证。接下来,我希望将1999-12和2000-01中的所有横截面单元作为训练,并将2000-02中的所有横截面单元作为验证,以此类推。使用TimeSeriesSplit函数可以这样做吗,或者我需要查看其他地方?
共有1个答案

TimeSeriesSplit是Kfold的变体,它确保在每个连续的fold中索引值都是升序的。如文件所述:
在每一次分裂中,测试指标必须高于以前...[另外]注意,与标准交叉验证方法不同,连续的训练集是它们之前的训练集的超集。
文档
import pandas as pd
import numpy as np
import datetime
arrays = [np.array(['A', 'A', 'A', 'B', 'B', 'C', 'C', 'D', 'D', 'D', 'D']),
np.array(['2000-01', '2000-02', '2000-03', '1999-12', '2000-01',
'2000-01', '2000-02', '1999-12', '2000-01', '2000-02', '2000-03'])]
# Cast as datetime
arrays[1] = pd.to_datetime(arrays[1])
df = pd.DataFrame(np.random.randn(11, 4), index=arrays)
df.index.sort_values()
folds = df.reset_index() # df still has its multindex after this
# You can tack an .iloc[:, 2:] to the end of these lines for just the values
# Use your predefined conditions to access the datetimes
fold1 = folds[folds["level_1"] <=datetime.datetime(2000, 1, 1)]
fold2 = folds[folds["level_1"] == datetime.datetime(2000, 2, 1)]
fold3 = folds[folds["level_1"] == datetime.datetime(2000, 3, 1)]
-
问题内容: 我想使用scikit-learn的GridSearchCV来确定随机森林模型的一些超级参数。我的数据是时间相关的,看起来像 如何实现以下交叉验证折叠技术? 也就是说,我想使用2年的历史观测值来训练模型,然后在接下来的一年中测试其准确性。 问题答案: 您只需要将拆分的可迭代对象传递给GridSearchCV。此拆分应采用以下格式: 要获取idx,您可以执行以下操作: 看起来像这样: 然后
-
本文向大家介绍问题:对应时间序列的数据集如何进行交叉验证?相关面试题,主要包含被问及问题:对应时间序列的数据集如何进行交叉验证?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 1.预测后一半;2.日向前链 解析:传统的交叉验证由于假定样本独立同分布,因此随机打乱分为训练集和验证集。但是对于时间序列来讲,需要考虑序列间的时间依赖。
-
问题内容: 我正在尝试训练数据不平衡的网络。我有A(198个样本),B(436个样本),C(710个样本),D(272个样本),并且我已经阅读了有关“weighted_cross_entropy_with_logits”的信息,但是我发现的所有示例都是针对二进制分类的,因此我不太了解对如何设置这些权重充满信心。 样本总数:1616 A_weight:198/1616 = 0.12? 如果我理解的话
-
我知道使用旋转保持二叉搜索树平衡/自平衡的方法。 我不确定我的情况是否需要那么复杂。我不需要像自平衡BST那样维护任何排序顺序属性。我只是有一个普通的二叉树,我可能需要删除节点或插入节点。我需要尝试在树中保持平衡。为简单起见,我的二叉树类似于段树,每次删除一个节点时,从根到这个节点的路径上的所有节点都会受到影响(在我的情况下,这只是节点值的一些减法)。类似地,每次插入一个节点时,从根到插入节点的最
-
我工作的问题,以检查如果二进制结构树是平衡或不,当我运行代码,我得到EXC_BAD_ACCESS,我不确定如何修复问题,是什么导致它打破。 假设代码在某个时刻命中 NULL 并返回 (true,-1),并深入到左侧子树。然后返回并转到右侧子树。我们可以检查左和右的子树是否由不同的平衡,如果它是 谢谢
-
我正在探索OpenJDK JMH测试我的代码。根据我的理解,默认情况下,JMH会派生多个JVM,以保护测试不受之前收集的“概要文件”的影响。这个示例代码对此做了很好的解释。 但是,我的问题是,如果我使用以下两种方法执行,我将对结果产生什么影响: 1) 有 1 个分叉,100 次迭代 2) 有 10 个分叉,每个分叉 10 次迭代 哪种方法会给出更准确的结果?