
在Python中的数据矩阵上绘制层次聚类的结果

如何在Python中将树状图绘制在值矩阵的顶部,并适当地重新排序以反映聚类?下图是一个示例:
https://publishing-
cdn.elifesciences.org/07103/elife-07103-fig6-figsupp1-v2.jpg
我使用scipy.cluster.dendrogram制作树状图,并对数据矩阵执行分层聚类。然后,我如何才能将数据绘制为矩阵,在该矩阵中对行进行重新排序以反映在特定阈值处切割树状图而引起的聚类,并使树状图在矩阵旁边绘制?我知道如何以密密麻麻的方式绘制树状图,但是不知道如何在数据强度矩阵旁边绘制正确的比例尺。
任何帮助,将不胜感激。
问题答案:
这个问题不能很好地定义 矩阵 :“值矩阵”,“数据矩阵”。我认为您的意思是 距离矩阵 。换句话说,对称非负N×N 距离矩阵
D中的元素D_ij表示两个特征向量x_i和x_j之间的距离。那是对的吗?
如果是这样,请尝试以下操作(2010年6月13日编辑,以反映两个不同的树状图):
import scipy
import pylab
import scipy.cluster.hierarchy as sch
from scipy.spatial.distance import squareform
# Generate random features and distance matrix.
x = scipy.rand(40)
D = scipy.zeros([40,40])
for i in range(40):
for j in range(40):
D[i,j] = abs(x[i] - x[j])
condensedD = squareform(D)
# Compute and plot first dendrogram.
fig = pylab.figure(figsize=(8,8))
ax1 = fig.add_axes([0.09,0.1,0.2,0.6])
Y = sch.linkage(condensedD, method='centroid')
Z1 = sch.dendrogram(Y, orientation='left')
ax1.set_xticks([])
ax1.set_yticks([])
# Compute and plot second dendrogram.
ax2 = fig.add_axes([0.3,0.71,0.6,0.2])
Y = sch.linkage(condensedD, method='single')
Z2 = sch.dendrogram(Y)
ax2.set_xticks([])
ax2.set_yticks([])
# Plot distance matrix.
axmatrix = fig.add_axes([0.3,0.1,0.6,0.6])
idx1 = Z1['leaves']
idx2 = Z2['leaves']
D = D[idx1,:]
D = D[:,idx2]
im = axmatrix.matshow(D, aspect='auto', origin='lower', cmap=pylab.cm.YlGnBu)
axmatrix.set_xticks([])
axmatrix.set_yticks([])
# Plot colorbar.
axcolor = fig.add_axes([0.91,0.1,0.02,0.6])
pylab.colorbar(im, cax=axcolor)
fig.show()
fig.savefig('dendrogram.png')
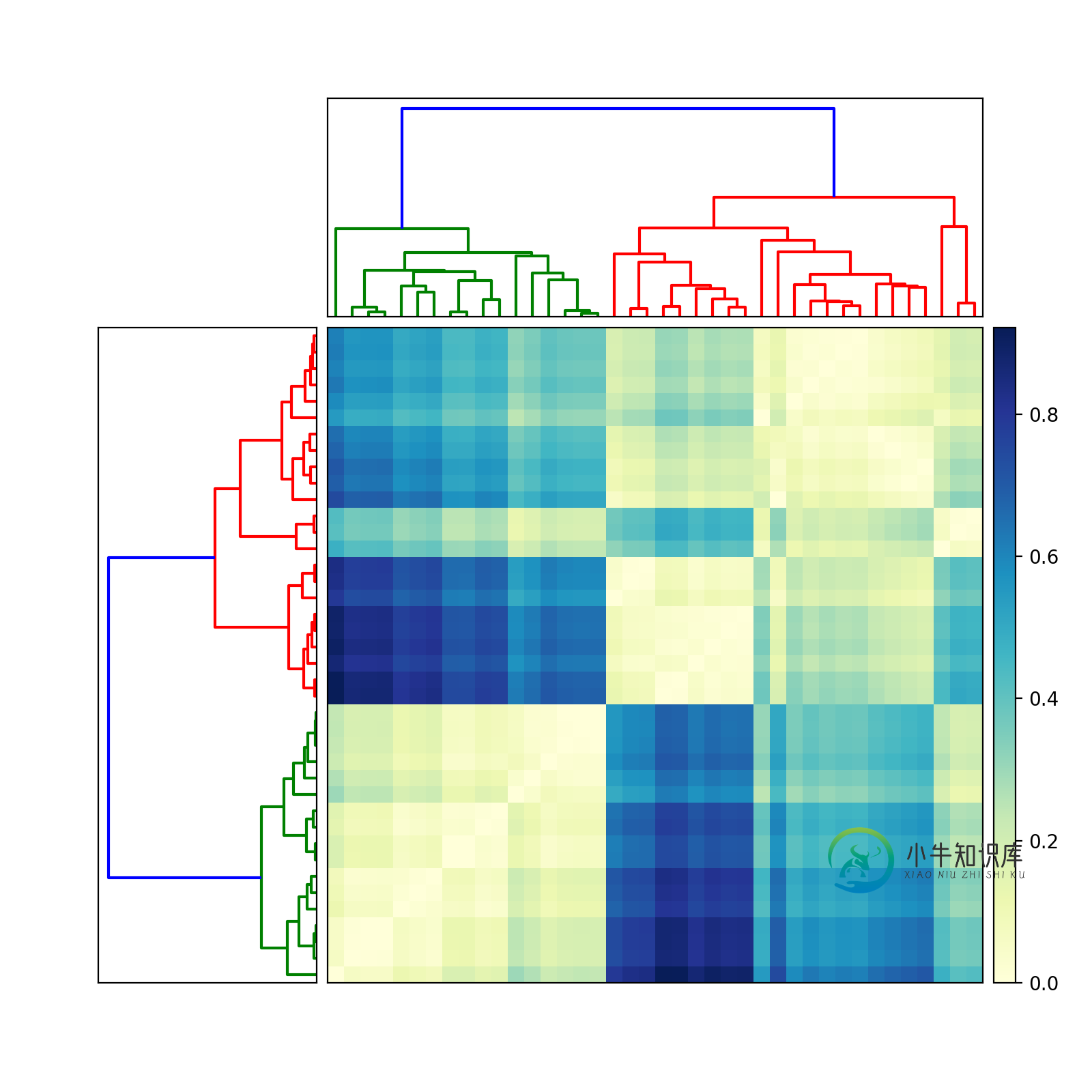
祝好运!让我知道您是否需要更多帮助。
编辑:对于不同的颜色,请调整中的cmap属性imshow。有关示例,请参见scipy /
matplotlib文档
。该页面还描述了如何创建自己的颜色图。为了方便起见,我建议使用预先存在的颜色图。在我的示例中,我使用YlGnBu。
Edit: add_axes (see documentation
here)
accepts a list or tuple: (left, bottom, width, height). For example,
(0.5,0,0.5,1) adds an Axes on the right half of the figure.
(0,0.5,1,0.5) adds an Axes on the top half of the figure.
Most people probably use add_subplot for its convenience. I like add_axes
for its control.
To remove the border, use add_axes([left,bottom,width,height], frame_on=False). See example
here.
-
问题内容: 我有几个Jenkins矩阵项目,在这些项目中,我在CSV文件中输出基准测试结果(即执行时间)。我想将这些执行时间绘制为内部版本号的函数,以便可以查看我的项目是否随着时间的推移而退化。 问题答案: 我可以确认Plot Plugin是正确且非常有用的方法。顺便说一句,它也支持CSV:绘图配置示例 我已经使用了几年没有任何问题。基准测试结果作为属性文件生成。基准标识(系列标识)用作键,结果用
-
对于层次聚类法,我们不需要预先指定分类的数量,这个算方法会将每条数据都当作是一个分类,每次迭代的时候合并距离最近的两个分类,直到剩下一个分类为止。 因此聚类的结果是:顶层有一个大分类,这个分类下有两个子分类,每个子分类下又有两个子分类,依此类推,层次聚类也因此得命。 在合并的时候我们会计算两个分类之间的距离,可以采用不同的方法。如下图中的A、B、C三个分类,我们应该将哪两个分类合并起来呢? 单链聚
-
在片段中绘制该图像的最佳方式是什么(所有矩形都应该使用屏幕的整个宽度,高度应该以特定的dp度量)?显然需要画矩形,但我不知道如何在下面的灰色大矩形上画白色和黄色的矩形。同样,使用相同的片段java类,而不是创建一个新的,可以实现这一点吗?
-
本文向大家介绍Python聚类算法之凝聚层次聚类实例分析,包括了Python聚类算法之凝聚层次聚类实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python聚类算法之凝聚层次聚类。分享给大家供大家参考,具体如下: 凝聚层次聚类:所谓凝聚的,指的是该算法初始时,将每个点作为一个簇,每一步合并两个最接近的簇。另外即使到最后,对于噪音点或是离群点也往往还是各占一簇的,除非过度合并。对于
-
问题内容: 我正在像这样扩展JFrame: 但是,屏幕上只画了一个正方形,有人知道为什么吗? 我的广场课也看起来像这样: 问题答案: JFrame的contentPane默认使用BorderLayout。当您向其添加一个Square时,默认情况下会添加BorderLayout.CENTER并覆盖以前添加的所有Square。您将需要阅读所有可用于Swing GUI的布局管理器。 例如,从这里开始:在
-
我们可以使用优先队列来实现这个聚类算法。 什么是优先队列呢? 普通的队列有“先进先出”的规则,比如向队列先后添加Moa、Suzuka、Yui,取出时得到的也是Moa、Suzuka、Yui: 而对于优先队列,每个元素都可以附加一个优先级,从队列中取出时会得到优先级最高的元素。比如说,我们定义年龄越小优先级越高,以下是插入过程: 取出的第一个元素是Yui,因为她的年龄最小: 我们看看Python中如何