
5.2.1.1.1-HDFS-安装
采用最简配置进行安装。
1. yum 安装
1.1 安装组件
yum install hadoop-hdfs-namenode
# 在将要运行 NameNode 的节点上安装。
yum install hadoop-hdfs-datanode
# 在将要运行 DataNode 的节点上安装。
1.2 修改配置文件
使用 yum 安装的 cdh 版本 hdfs 配置文件在 /etc/hadoop/conf 路径下,使用 tar 安装的 apache 版本 hadoop 配置文件在安装路径的 conf 目录下。
- core-site.xml
- hdfs-site.xml
- hadoop-env.sh
1.3 创建目录
根据配置文件创建目录,并且修改文件用户为hdfsmkdir /namedir # 在 namenode 节点创建,与 hdfs-site.xml 配置文件中 dfs.namenode.name.dir 的配置一致即可。 chown -R hdfs:hdfs /namedir # cdh 版本需要改变权限, apache 版本不改权限也能成功。 mkdir /datadir # 在 datanode 节点创建,与 hdfs-site.xml 配置文件中 dfs.namenode.data.dir 的配置一致。 chown -R hdfs:hdfs /namedir # cdh 版本需要改变权限, apache 版本不改权限也能成功。1.4 格式化 NameNode
hdfs namenode -format chown -R hdfs:hdfs /namedir # cdh 版本需要改变权限, apache 版本不改权限也能成功。1.5 启动服务
如果启动时不打印日志,则去 /etc/init.d 路径下启动,当启动不成功时,根据打印的日志地址查看日志,注意将 .out 改为 .log。service hadoop-hdfs-namenode start # 启动 namenode,并使用 jps 查看进程是否存在。 service hadoop-hdfs-datanode start # 启动 namenode,并使用 jps 查看进程是否存在。1.6 其他
- 启动失败时,删除 datadir 和 namedir 目录下的全部文件,重新 format。
- 验证方式,使用 hdfs dfs -mkdir /test 能成功创建文件夹。
1.7 常见错误及解决方案
- 日志中 datadir 或 namedir Pemission Deny,cdh 版本查看 datadir 或 namedir 以及目录下的文件是否为 hdfs:hdfs 属组和用户,不是则使用 chown 命令改变。
- Cluster id,删除 datadir 或 namedir 下的所有文件,重新格式化并启动。
- JAVA_HOME not set,配置 hadoop-env.sh 文件中的 JAVA_HOME。 如果还是不能解决,在使用的脚本中设置 JAVA_HOME。
2. tar 包安装的不同点
- datadir 或 namedir 权限不要改变。
- 环境变量需要添加 HADOOP_HOME ,PATH 添加 $HADOOP_HOME/bin:$HADOOP_HOME:sbin
- apache 版本使用 start-dfs.sh 启动一次,cdh 版本使用 service 命令去 namenode、datanode 节点分别启动。
3. 高可用版
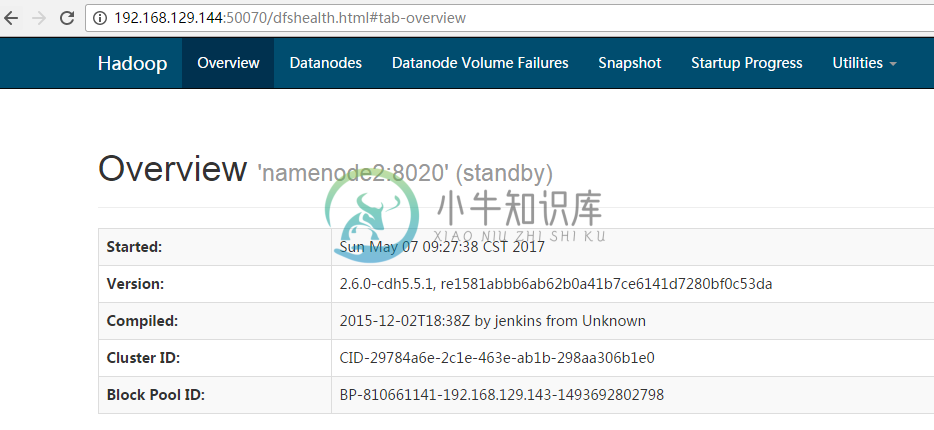
(1)启动 Zookeeper 集群,命令:zkServer.sh start,并查看状态,命令:zkServer.sh status。 (2) 格式化 Zookeeper 集群(只在 NameNode 节点运行),格式化命令:hdfs zkfc -formatZK (3)开启 Journalmnode 集群,命令:/etc/init.d/hadoop-hdfs-journalnode start。 (4)格式化 Namenode,格式化命令:hadoop namenode –format。 (5)格式化 Standby Namenode,格式化命令:hadoop namenode –bootstrapStandby。 (6)启动HDFS,脚本见附录B。 (7)启动 Yarn,脚本见附录B。 (8)启动 zkfc (注:只在 Namenodehe 和 Standby Namenode) 命令:hadoop-daemon.sh start zkfc (10)通过192.168.129.143/144:50070查看,如下图7:192.168.129.143处于active状态;如下图8,192.168.129.144处于standby状态,配置成功。我们可以再192.168.129.143节点执行serivce network restart命令,192.168.129.144处于active状态,192.168.129.143处于standby状态,高可用性配置成功。同样,我们可以通过192.168.129.143/144:8088 Yarn的Web界面,如下图9,配置成功。 启动完成后可以通过60030端口访问regionServer页面, 60010端口访问hbase的master页面。 (11)使用多次 namenode 格式化后可能出现 ID 不匹配的问题时,删除 current 文件(可以使用 find / -name current 命令查找,namenode 和 datanode 都需 要删除),重新格式化。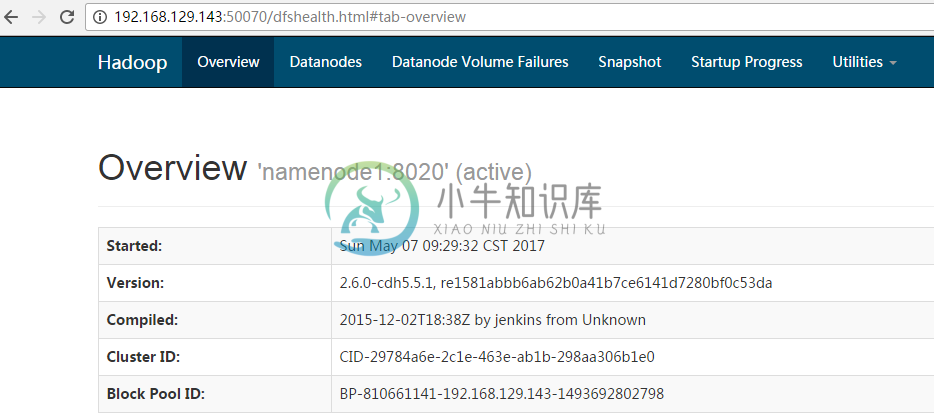
参考资料
- Installing and Deploying CDH Using the Command Line
- Docker绑定固定IP/跨主机容器互访
- Deploying CDH 5 on a Cluster
- 使用yum源安装CDH Hadoop集群
- core-site.xml.ha
- hdfs-site.xml.ha
- Enabling HDFS HA