部署预测系统(Deploying a predictive system)
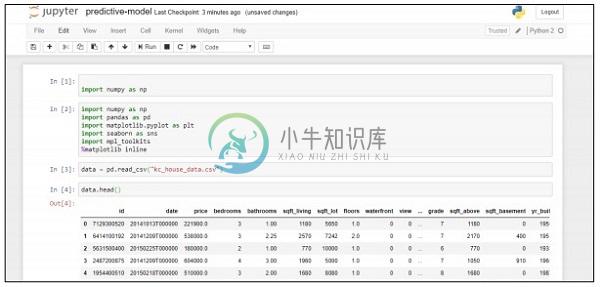
在这个例子中,我们将学习如何创建和部署预测模型,这有助于使用python脚本预测房价。 用于部署预测系统的重要框架包括Anaconda和“Jupyter Notebook”。
按照以下步骤部署预测系统 -
Step 1 - 实现以下代码以将csv文件中的值转换为关联值。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import mpl_toolkits
%matplotlib inline
data = pd.read_csv("kc_house_data.csv")
data.head()
上面的代码生成以下输出 -
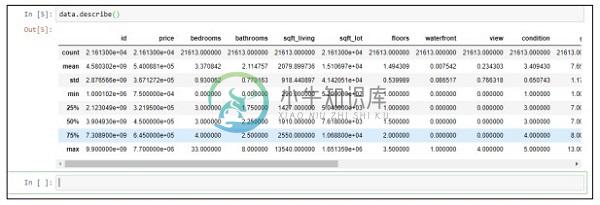
Step 2 - 执行describe函数以获取csv文件的归属中包含的数据类型。
data.describe()
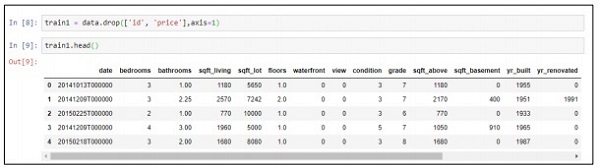
Step 3 - 我们可以根据我们创建的预测模型的部署删除关联的值。
train1 = data.drop(['id', 'price'],axis=1)
train1.head()
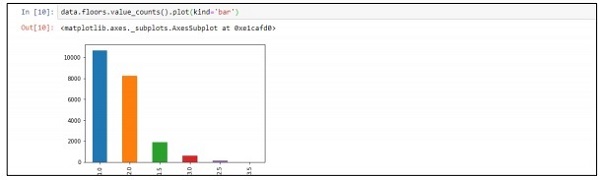
Step 4 - 您可以根据记录可视化数据。 该数据可用于数据科学分析和白皮书输出。
data.floors.value_counts().plot(kind='bar')