
5.1.4 确定文档类型和输出中文
向客户端浏览器中输出中文一直是很多初学者最闹心的问题之一。如果按着输出英文的方式输出中文,往往会在浏览器中出现乱码或是干脆乱码都不出现,直接显示成了“?”。但如果要是了解了显示乱码或“?”的原理,那么处理起这类问题,就会游刃有余了。
首先来看一下为什么会显示“?”。当在浏览器中出现“?”时,查看一下HTML源代码,这时就会发现在HTML源代码中仍然是“?”,从这一点可以断定。显示“?”并不是客户端浏览器的“杰作”,而是服务端发送到客户端的信息就是“?”,因此,产生“?”的原因在服务端。
实际上,由于Java在内部使用了UCS2(Unicode-16)编码格式,然而在输出字符时,在默认情况下将UCS2转换成了ISO-8859-1编码格式,而这种编码格式根本就不支持中文字符,因此,就无法成功进行编码转换了,在Java中如果在进行编码转换时,当某些字符无法转换,就会用“?”代替,因此,就会出现在浏览器中显示“?”的现象。那么如果解决呢?答案非常简单,只要将UCS2转换成支持中文的字符集编码即可。这种编码格式有很多,如UTF-8、GBK等。而在HttpServletResponse接口中定义了若干方法来完成这个工作。这些方法包括addHeader、setHeader、setContent-Type、setCharacterEncoding、setLocale(详见5.1.2节的介绍)。
现在来看看在浏览器中显示乱码的问题。当查看客户端的HTML源代码时,发现在浏览器中显示乱码的字符,在HTML源代码中显示的是正常的字符。从此可以断定,这个问题是由于浏览器编码解析错误而产生的。解决的方法有很多,如直接更改浏览器的编码设置(对于IE浏览器可以通过选择【查看】>【编码】菜单中的相应编码格式来改变浏览器当前的编码格式),或者通过设置HTTP响应消息头的Content-Type字段来强迫浏览器使用某一编码格式(通过setContentType方法或addHeader方法都可以达到这个目的)。
在下面的例子中将演示一下“?”和乱码是如何产生的,以及如果解决这些问题。
例子 :向客户端输出中文信息
1. 实例说明
在本例的Servlet类中通过一个action请求参数来指定了6种向客户端输出中文的情况,在这些情况中,有的会产生乱码,有的则会在浏览器中正常显示中文信息。读者可以从中充分体会到在Servlet类中向客户端浏览器正常输出中文信息的方法。
2. 编写ChineseServlet类
在ChineseServlet类中使用了6种方法向客户端输出中文信息。ChineseServlet类的实现代码如下:
public class ChineseServlet extends HttpServlet
{
public void service(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException
{
// 读取action参数的值
String action = request.getParameter("action");
// 如果没有action参数,默认是第1种情况
if (action == null)
action = "1";
// 第1种情况
if (action.equals("1"))
{
// 服务端和客户端编码都未设置,这时输出到客户端的中文信息都变成了“?”
}
// 第2种情况
else if (action.equals("2"))
{
// 设置了服务端的编码,客户端浏览器如果处在自动选择编码状态,
// 将选择操作系统默认的编码格式,也就是GBK,因此,浏览器会显示乱码
response.setCharacterEncoding("UTF-8");
}
// 第3种情况
else if (action.equals("3"))
{
response.setCharacterEncoding("UTF-8");
// 在HTTP响应信息头加入了Content-Type字段,
// 这时客户端终于可以正常显示出中文了
response.addHeader("Content-Type", "text/html;charset=UTF-8");
}
// 第4种情况
else if (action.equals("4"))
{
// 同时设置了客户端和服务端编码
response.setContentType("text/html;charset=UTF-8");
}
// 第5种情况
else if (action.equals("5"))
{
// 和使用setContentType的效果完全一样
response.addHeader("Content-Type", "text/html;charset=UTF-8");
}
// 第6种情况
else if (action.equals("6"))
{
// 设置了服务端的编码
response.setCharacterEncoding("UTF-8");
// 重新设置了服务端的字符集编码(覆盖了setCharacterEncoding方法设置的编码格式)
response.setContentType("text/html;charset=GBK");
// 可以使用addHeader来代替setContentType
// response.addHeader("Content-Type", "text/html;charset=GBK");
}
response.getWriter().write("<b>中文信息</b>");
}
}要注意的是在第2种情况下,如果浏览器设置的是UTF-8编码格式,那么仍然会正确显示中文。但经我测试,如果选择了“自动选择”编码,则浏览器会选择操作系统的默认编码,也就是GBK编码格式,但上述情况只针对IE,在Firefox中,就算是选择了“自动选择”编码,仍然会正确选择UTF-8。但为了通用,还是使用setContentType方法来同时设置服务端和客户端编码为好。在上面的代码中,除了第1种情况外都可以向客户端正常输出中文字符,如果出现乱码,唯一的原因就是客户端浏览器使用了不正确的编码格式进行解析。
另外Content-Type字段值的前半部分指定了“text/html”,表示向客户端输出的内容是HTML代码,因此,浏览器会按着HTML的语法来解释从服务端接接收到的文本。而如果将其改为“text/plain”,那么“<b>中文信息</b>”将按着原样输出,浏览器并不会将“中文信息”设为粗体字。
3. 配置ChineseServlet类
ChineseServlet类的配置代码如下:
<servlet>
<servlet-name>ChineseServlet</servlet-name>
<servlet-class>chapter5.ChineseServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>ChineseServlet</servlet-name>
<url-pattern>/ChineseServlet</url-pattern>
</servlet-mapping>4. 测试显示“?”和乱码的情况
在浏览器地址栏中输入如下的URL:
http://localhost:8080/demo/ChineseServlet?action=1
浏览器就会显示出“?”,如图5.3所示。
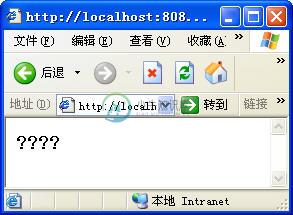
图5.3 输出“?”
在浏览器地址栏中输入如下的URL:
http://localhost:8080/demo/ChineseServlet?action=2
浏览器中会显示乱码(这时浏览器要设为自动选择编码状态),如图5.4所示。
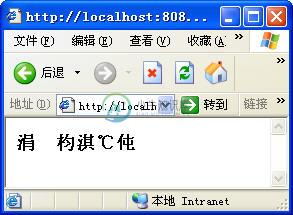
图5.4 输出乱码
5. 测试正常显示中文信息的情况
在浏览器地址栏中输入如下的URL后,则会正常显示中文:
http://localhost:8080/demo/ChineseServlet?action=3
实际上,action请求参数从3至6都会正常显示中文。只是在第6种情况会使用GBK编码,其他的情况使用UTF-8编码。
6. 程序总结
在向客户端输出中文时要同时设置客户端和服务端的字符集编码格式,虽然有很多方法可以完成这个工作,但我建议使用setContentType方法来完成编码设置的工作。