
十二、案例学习:用于 SMS 垃圾检测的文本分类
我们首先从dataset目录中加载文本数据,该目录应该位于notebooks目录中,是我们通过从GitHub存储库的顶层运行fetch_data.py脚本创建的。
此外,我们执行一些简单的预处理并将数据数组拆分为两部分:
text:列表的列表,其中每个子列表包含电子邮件的内容 y:我们的 SPAM 与 HAM 标签,以二元形式存储;1 代表垃圾邮件,0 代表非垃圾邮件消息。
import os
with open(os.path.join("datasets", "smsspam", "SMSSpamCollection")) as f:
lines = [line.strip().split("\t") for line in f.readlines()]
text = [x[1] for x in lines]
y = [int(x[0] == "spam") for x in lines]
text[:10]
y[:10]
print('Number of ham and spam messages:', np.bincount(y))
type(text)
type(y)
接下来,我们将数据集分为两部分,即测试和训练数据集:
from sklearn.model_selection import train_test_split
text_train, text_test, y_train, y_test = train_test_split(text, y,
random_state=42,
test_size=0.25,
stratify=y)
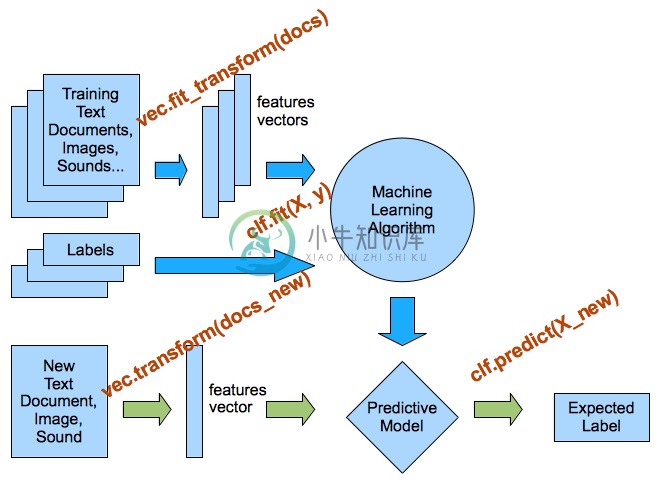
现在,我们使用CountVectorizer将文本数据解析为词袋模型。
from sklearn.feature_extraction.text import CountVectorizer
print('CountVectorizer defaults')
CountVectorizer()
vectorizer = CountVectorizer()
vectorizer.fit(text_train)
X_train = vectorizer.transform(text_train)
X_test = vectorizer.transform(text_test)
print(len(vectorizer.vocabulary_))
X_train.shape
print(vectorizer.get_feature_names()[:20])
print(vectorizer.get_feature_names()[2000:2020])
print(X_train.shape)
print(X_test.shape)
为文本特征训练分类器
我们现在可以训练分类器,例如逻辑回归分类器,它是文本分类任务的快速基线:
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf
clf.fit(X_train, y_train)
我们现在可以在测试集上评估分类器。 让我们首先使用内置得分函数,这是测试集中正确分类的比例:
clf.score(X_test, y_test)
我们还可以计算训练集上的扥分,看看我们做得如何:
clf.score(X_train, y_train)
可视化重要特征
def visualize_coefficients(classifier, feature_names, n_top_features=25):
# get coefficients with large absolute values
coef = classifier.coef_.ravel()
positive_coefficients = np.argsort(coef)[-n_top_features:]
negative_coefficients = np.argsort(coef)[:n_top_features]
interesting_coefficients = np.hstack([negative_coefficients, positive_coefficients])
# plot them
plt.figure(figsize=(15, 5))
colors = ["tab:orange" if c < 0 else "tab:blue" for c in coef[interesting_coefficients]]
plt.bar(np.arange(2 * n_top_features), coef[interesting_coefficients], color=colors)
feature_names = np.array(feature_names)
plt.xticks(np.arange(1, 2 * n_top_features + 1), feature_names[interesting_coefficients], rotation=60, ha="right");
visualize_coefficients(clf, vectorizer.get_feature_names())
vectorizer = CountVectorizer(min_df=2)
vectorizer.fit(text_train)
X_train = vectorizer.transform(text_train)
X_test = vectorizer.transform(text_test)
clf = LogisticRegression()
clf.fit(X_train, y_train)
print(clf.score(X_train, y_train))
print(clf.score(X_test, y_test))
len(vectorizer.get_feature_names())
print(vectorizer.get_feature_names()[:20])
visualize_coefficients(clf, vectorizer.get_feature_names())
练习
使用
TfidfVectorizer而不是CountVectorizer。 结果更好吗?系数如何不同? 更改TfidfVectorizer和CountVectorizer的参数min_df和ngram_range。这如何改变重要特征?
# %load solutions/12A_tfidf.py
# %load solutions/12B_vectorizer_params.py