
层次化的函数库设计
Subversion 的每一个核心函数库都隶属于三个层次之一—仓库层, 仓库访问 (Repository Access, 简称 RA) 层和客户端层 (见 图 1 “Subversion 的架构”). 我们将会简单地介绍这些层次, 但是在这之前, 先简单地总结一下 Subversion 的各个函数库. 为了保持一致, 我们把函数库的名字写成删除了扩展名后, 在 Unix 中的库文件名 (例如 libsvn_fs, libsvn_wc, mod_dav_svn 等).
- libsvn_client
客户端程序的主要接口
- libsvn_delta
目录树和字节流差异比较例程
- libsvn_diff
文件内容差异比较和合并例程
- libsvn_fs
文件系统公共函数和模块加载例程
- libsvn_fs_base
Berkeley DB 文件系统后端
- libsvn_fs_fs
原生文件系统 (FSFS) 后端
- libsvn_ra
仓库访问公共例程和模块加载例程
- libsvn_ra_local
本地仓库访问模块
- libsvn_ra_serf
另一个 WebDAV 仓库访问模块 (试验性的)
- libsvn_ra_svn
使用定制协议的仓库访问模块
- libsvn_repos
仓库接口
- libsvn_subr
各种辅助例程
- libsvn_wc
工作副本管理函数库
- mod_authz_svn
Apache 授权模块, 用于借助 WebDAV 的 Subversion 仓库访问
- mod_dav_svn
Apache 模块, 用于将 WebDAV 操作映射到 Subversion 的 对应操作
在上面的介绍中, “各种” 这个词只出现了一次, 这是一个 好现象, 因为 Subversion 开发团队总是尽量将功能放到正确的层次和函数库 中实现. 站在开发人员的角度来看, 模块化设计最大的好处可能是降低了复杂 度, 于是你就可以快速地勾勒出 “整体面貌”, 更加容易地决定 功能所属的位置.
模块化设计的另一个好处是允许我们重新实现给定的模块, 只要保持 API 兼容 性, 就不会影响其他模块. 在某种意义上, Subversion 已经在这样做了. 函数库 libsvn_ra_local, libsvn_ra_serf 和 libsvn_ra_svn 各自都实现了一套相同的接口, 它们都 是作为 libsvn_ra 的插件与仓库访问层通信— libsvn_ra_local 与仓库直接通信, 另外两个通过网络与 仓库通信. libsvn_fs_base 和 libsvn_fs_fs 是另一对用不同方式实现了相同接口的函数 库—它们是作为 libsvn_fs 的插件.
客户端本身也突出了 Subversion 模块化设计的优越性. 函数库 libsvn_client 是开发 Subversion 客户端的一站式商店 (见 “客户端层”一节). 所以说虽然 Subversion 发行版提供了命令行客户端工具 svn, 但还有 一些第三方程序提供了图形化的客户端工具, 这些图形化工具使用了和命令行工具 相同的 API. 模块化设计在 Subversion 的推广中起到了非常重要的作用.
仓库层
当说到 Subversion 仓库层时, 我们通常谈论的是两个基本概念—版本化 文件系统的实现 (通过 libsvn_fs 函数库访问, 它依赖 libsvn_fs_base 和 libsvn_fs_fs 这两个函数库), 以及围绕它的仓库逻辑 (在 libsvn_repos 里实现). 这些函数库为版本化数据的各 个版本提供了存储和报告机制. 仓库层通过仓库访问层连接到客户端层, 从 Subversion 用户的角度来看, 仓库层是 “线段的另一端”
Subversion 文件系统并不是在操作系统内核态实现的文件系统 (在内核态实现 的文件系统有 Linux ext2 或 NTFS 等), 它是一个虚拟文件系统, “文件” 和 “目录” 不是以真实的文件和目录的 形式 (真实的文件和目录就是你在 shell 中能够看到的那些文件和目录) 存放 到磁盘上, 而是使用了两种抽象存储后端—Berkeley DB 或一个平坦文件 系统 (关于这两种存储后端的更多信息, 见 文件系统). Subversion 开发团队甚至 在考虑为 Subversion 支持更多类型的后端数据库系统, 他们或许会通过 ODBC (Open Database Connectivity, 开放数据库连接) 实现这一特性. 实际上, Google 代码托管 (Google Code Project Hosting) 服务已经做过类似的工作: Google 在 2006 年中期宣称他们的开源团队已经开发了一个私有的 Subversion 文件系统插件, 该插件允许 Subversion 使用 Google Bigtable 数据库作为 存储后端.
其他文件系统 API 所能提供的功能, libsvn_fs 的 API 也能提供—你可以创建或删除文件和目录, 复制或移动, 修改文件内容等. 除此之外, libsvn_fs 还提供了不太常见的功能, 例如 在文件和目录上添加, 修改和删除元数据 (“属性”). 更重要的是, Subversion 的文件系统是一个版本化的文件系统, 这意味着在你修改目录树时, Subversion 记住了目录树被修改前的样子, 以及上次修改前的样子, 上上次 修改前的样子, 可以一直追溯到文件系统被创建的时候.
针对目录树的所有修改都是在一个 Subversion 提交事务的上下文中完成, 下面是修改文件系统的简化过程:
开始一个 Subversion 提交事务.
执行修改 (添加, 删除, 修改属性等).
提交事务.
事务一旦提交, 文件系统的修改就已经作为历史财产持久化地保存下来. 每次轮回都会产生一个新的版本号, 每个版本号都是一个永远可访问的只读 快照.
两种事务
用户很容易把 Subversion 的事务与后端数据库所提供的事务支持弄混, 特别是考虑到前者在 libsvn_fs_base 里的代码和 Berkeley DB 数据库的代码非常接近. 这两种事务都用于提供原子性和隔离性, 换句话说, 事务允许用户以这样一 种方式执行一个操作集合—要么集合中的所有操作都执行成功, 要么一 个都不执行—同时不会干扰到操作数据的其他进程.
数据库事务所围绕的操作通常与修改数据库的数据有关 (例如修改表的一 行), 而 Subversion 事务所涵盖的范围更大, 层次也更高, 例如针对文件或 目录集合的修改, 这些修改将作为一个新的版本号存放到文件系统中. 如果 读者的思路还跟得上, 再考虑这样一个事实—Subversion 是在一个数据 库事务中完成 Subversion 事务的创建 (如果 Subversion 事务创建失败, 那么数据库看起来就像是从来没有创建过 Subversion 事务).
幸运的是对于文件系统 API 用户而言, 由数据库所提供的事务支持几乎 是不可见的 (对于模块化的函数库而言, 这应该是人们所期待的效果), 只 有当人们想知道文件系统的实现细节时, 数据库事务才变成可见的.
文件系统接口提供的大多数功能都是针对文件系统中的路径进行操作, 也 就是说从文件系统外部看来, 描述与访问文件版本号的主要机制都要通过路径 字符串 (例如 /foo/bar) 实施, 类似于在 shell 程序 中处理文件与目录. 你可以用路径参数调用正确的函数来创建新文件与目录, 也可以用其他函数查询文件信息.
与大多数文件系统不同的是, 仅仅依靠路径无法在 Subversion 中唯一 地识别一个文件或目录. 把目录树看成是一个二维系统, 结点的兄弟代表了 一种横向移动, 而进入结点的子目录则是一种纵向移动. 图 8.1 “二维坐标系下的文件与目录” 展示了一个目录树的 典型表示.
图 8.1. 二维坐标系下的文件与目录
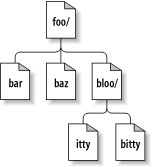
Subversion 文件系统的不同点在于它还有第三个维度—时间 [72] Subversion 文件系统提供的函数如果需要一 个 path 参数, 那么很可能也会需要一个 root 参数, 这个 svn_fs_root_t 类型的参数或者描述了一个版本号, 或者描述了一个 Subversion 事务 (完成中 的版本号), 它所提供的第三个维度可用于区分不同版本号下的 /foo/bar. 图 8.2 “Subversion 目录树的三维表示” 展示了增加了第三个 维度后, 目录树的三维表示.
图 8.2. Subversion 目录树的三维表示
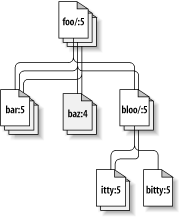
我们前面已经说过, libsvn_fs API 类似于其他 文件系统, 不同点是它提供了版本控制的功能, 不仅限于 Subversion, 任何 对版本化文件系统感兴趣的程序都能使用它的接口. 虽然文件系统 API 对于 基本的文件与目录的版本控制已经提供了足够的支持, 但 Subversion 的要求 不仅于此, 所以就有了 libsvn_repos.
Subversion 仓库函数库 libsvn_repos 从逻辑上 讲处于 libsvn_fs 之上, 在下层版本化文件系统的 基础上提供了更多的功能. libsvn_repos 只封装了 文件系统的某些接口, 包括 Subversion 事务的创建与提交, 版本号属性的修改, 之所以要封装这些接口是因为仓库层为它们关联了钩子. 仓库的钩子系统 并不要求一定要关联到一个版本化文件系统, 因此它们属于仓库函数库.
钩子机制是把仓库函数库与文件系统函数库分开的原因之一. libsvn_repos 还提供了以下功能:
创建, 打开, 销毁和恢复 Subversion 仓库 (包括仓库里的文件系统).
描述两个文件系统树之间的差异.
查询全部 (或部分) 版本号的提交日志消息, 在每个版本号中 都有一些文件系统中的文件与目录被修改.
生成一个人类可读懂的文件系统 “转储” 文件— 它是文件系统中版本号的完整表示.
解析转储文件, 把转储后的版本号加载到另一个 Subversion 仓库里.
随着 Subversion 的不断演变, 仓库函数库将与文件系统函数库共同成长, 提供越来越丰富的功能.
仓库访问层
如果说 Subversion 仓库层是 “线段的另一端”, 那么仓库 访问层 (Repository Access, 简称 RA) 就是线段本身. 仓库访问层充满了 客户端函数库与仓库函数库之间互相传递的数据. 仓库访问层包含的 函数库有模块加载库 libsvn_ra, 仓库访问模块本身 (目前的访问模块有 libsvn_ra_local, libsvn_ra_serf 和 libsvn_ra_svn), 以及仓库访问模块所需的其他 函数库 (例如 mod_dav_svn 或 svnserve).
Subversion 使用 URL 标识仓库资源, URL 的协议部分 (通常是 file://, http://, https://, svn:// 或 svn+ssh://) 决定了使用哪种仓库访问模块处理请求. 每个仓库访问模块都注册了它支持的协议, 于是 RA 加载函数就能在运行时决定 使用哪个模块. 用户可以执行 svn --version 查看 可用的 RA 模块及其所支持的协议:
$ svn --version svn, version 1.8.0-dev (under development) compiled Jan 8 2013, 11:45:25 on i686-pc-linux-gnu Copyright (C) 2013 The Apache Software Foundation. This software consists of contributions made by many people; see the NOTICE file for more information. Subversion is open source software, see http://subversion.apache.org/ The following repository access (RA) modules are available: * ra_svn : Module for accessing a repository using the svn network protocol. - with Cyrus SASL authentication - handles 'svn' scheme * ra_local : Module for accessing a repository on local disk. - handles 'file' scheme * ra_serf : Module for accessing a repository via WebDAV protocol using serf. - handles 'http' scheme - handles 'https' scheme $
RA 层导出的 API 包含了用于发送和接收版本化数据的必要功能, 而且每 一个 RA 插件都可以使用一种特定的协议完成这些任务, 例如 libsvn_ra_serf 使用 HTTP/WebDAV (还可以选择使用 SSL 加密) 与运行着 mod_dav_svn 模块的 Apache HTTP 服务器通信; libsvn_ra_svn 使用一种 Subversion 特有的协议与 svnserve 服务器通信.
RA 层使用了模块化的设计, 因为 Subversion 开发人员考虑到人们可能 还想使用其他协议访问 Subversion 仓库, 这就使得新协议的开发更加方便. 开发人员仅仅需要写一个实现了 RA 接口的函数库, 新的函数库可以使用已 有的网络协议或你自己发明的新协议, 你甚至可以使用进程间通信 (IPC) 或 基于电子邮件的协议. Subversion 提供了 API, 而你则提供创造性.
客户端层
在客户端, 工作副本是所有操作发生的地方, 客户端实现的所有功能都是为 了更好地管理工作副本—包含了众多文件与子目录的目录, 作为一个 或多个仓库在本地的, 可编辑的 “映射”—并且向仓库 访问层发送或接收修改.
Subversion 工作副本函数库 libsvn_wc 负责管理工作 副本的数据, 为了完成这个任务, 函数库把工作副本有关的管理信息都存放在 一个特殊的子目录内, 这个子目录的名字是 .svn, 每 个工作副本都有这个目录, 目录内包含了用于记录工作副本状态的各种文件与 目录, 为管理性的操作提供了一个私有工作空间. 如果读者熟悉 CVS, 就会发 现 .svn 的功能与 CVS 工作副本里的 CVS 目录非常类似.
Subversion 客户端函数库 libsvn_client 所负责的工作是最广泛的, 它负责混合工作副本函数库与仓库访问层函数 库的功能, 进而向应用程序提供最高层次的 API, 允许应用程序执行最一 般的版本控制操作. 例如函数 svn_client_checkout 接收一个 URL 作为参数, 它将 URL 传递给 RA 层, 并打开一个关联到特定 仓库的已认证会话, 然后函数向仓库请求一个特定的目录树, 并将此目录树 发送给工作副本函数库, 最终在磁盘上得到一个完整的工作副本 (包括目录 .svn).
客户端函数库被设计成可被任意的应用程序使用, Subversion 源代码 包已经包含了一个命令行客户端, 不过基于客户端函数库写出一个 GUI 客户 端并没有多大的难度. 新的客户端没必要封装已有的命令行客户端— 它们完全可以通过 libsvn_client API 获得相同的 功能, 数据和回调机制. 实际上, Subversion 源代码包包含了一个最小化的 客户端实现 (代码在 tools/examples/minimal_client.c), 展示了如何使 用 Subversion API 实现一个简单的客户端程序.
直接绑定—关于正确性的一些话
为什么你的 GUI 程序应该使用 libsvn_client 开发, 而不是直接封装一个命令行程序? 前者除了效率更高之外, 也更 加正确. 基于客户端函数库开发的命令行程序 (例如 Subversion 所提供的) 需要把 C 类型的反馈或请求数据高效地翻译成人类可读懂的格式, 这种 翻译是有损的, 也就是说程序可能无法呈现从 API 获取到的所有信息, 或者为了紧凑显示而与其他信息进行组合.
如果你的程序建立在命令行程序的封装之上, 那么程序只能访问到已 被翻译过的信息 (上面我们刚说过, 信息可能是不完整的), 而这些信息 将被 再次 翻译成 程序自己的 表示格式. 每一次封装, 原始数据 的完整性被破坏的就越多, 类似于拷贝音频或视频磁带的拷贝 (的拷贝 …).
基于 API 进行开发, 而不是封装其他程序的另一大原因是 Subversion 保证了 API 的兼容性. 在次版本号不同的 API 之间 (例如 1.3 和 1.4), 其函数原型不会发生变化, 也就是说在升级 Subversion 时, 不 必升级你自己的程序. 特定的一些函数可能不再赞成使用, 但它们仍然可 以正常工作, 这就给了你一定的缓冲时间升级到最新的 API. 然而 Subversion 命令行程序的输出无法保证这种兼容性.
[72] 某些科幻迷可能会感到震惊, 因为他们一直以来都认为时间 是第 四 个维度, 对此造成的情感创伤我们表示 道歉.