
Cassandra中版本化层次结构的高效建模

免责声明:
这是一篇相当长的文章。我首先解释我正在处理的数据,以及我想用它做什么
然后,我详细介绍了我考虑过的三种可能的解决方案,因为我试着做作业(我发誓:])。我最后得到了一个“最佳猜测”,这是第一个解决方案的变体。
我的终极问题是:使用Cassandra解决我的问题的最明智的方法是什么?这是我的尝试之一,还是其他什么?
我正在寻求经验丰富的Cassandra用户的建议/反馈…
我的数据:< br >我有许多超级文档,它们拥有树状结构的文档(标题、子标题、小节等)。
每个SuperDocument结构都可以随着时间的推移而改变(主要是重命名标题),从而为我提供了结构的多个版本,如下所示。
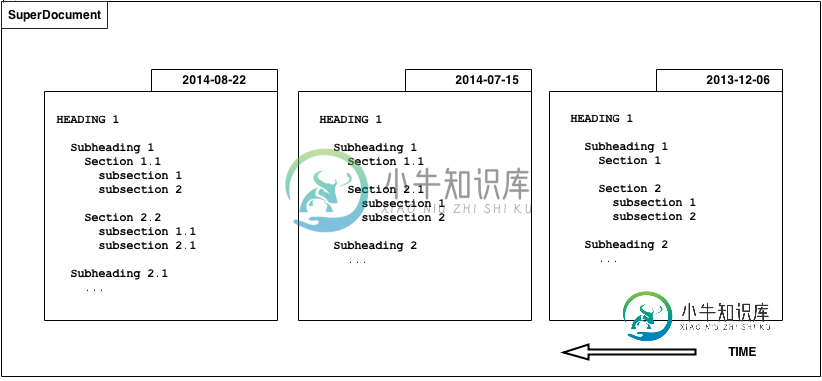
我正在寻找什么:
对于每个超级文档,我需要按上述日期为这些结构添加时间戳,并且我希望在给定的日期内找到最接近的SuperDocument结构的早期版本。(即version_date的最新版本
这些考虑可能有助于更容易地解决问题:
版本是不可变的:更改很少见,每次更改时,我都可以创建整个结构的新表示形式。- 我不需要访问结构的子树。
- 我想说的是,我不需要找到给定叶子的所有祖先,也不需要访问树内的特定节点/叶子。一旦我有了整个树,我就可以在我的客户端代码中解决所有这些问题。
好的,让我们来做
请记住,我真的刚刚开始使用Cassandra。我读过/看过很多关于数据建模的资源,但没有太多(任何!)现场经验
这也意味着一切都将用CQL3写……对不起,节俭爱好者!
我解决这个问题的第一次尝试是创建下表:
CREATE TABLE IF NOT EXISTS superdoc_structures (
doc_id varchar,
version_date timestamp,
pre_pos int,
post_pos int,
title text,
PRIMARY KEY ((doc_id, version_date), pre_pos, post_pos)
) WITH CLUSTERING ORDER BY (pre_pos ASC);
这将给我以下结构:
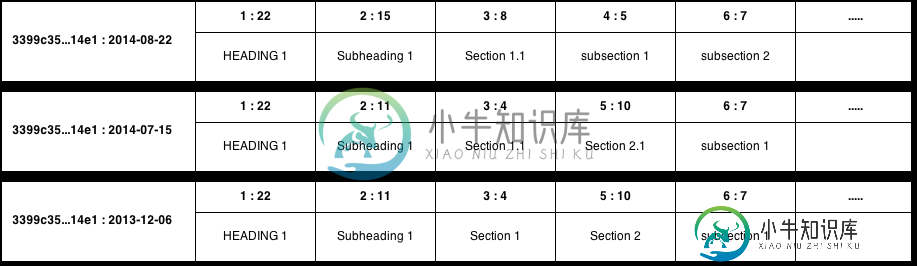
我在这里为我的树使用嵌套集模型;我认为保持结构有序会很好,但我对其他建议持开放态度。
我喜欢这个解决方案:每个版本都有自己的行,其中每一列表示层次结构的一个级别
但问题是我(坦率地)打算如下查询我的数据:
SELECT * FROM superdoc_structures
WHERE doc_id="3399c35...14e1" AND version_date < '2014-03-11' LIMIT 1
卡桑德拉很快提醒我,我不被允许这样做!(因为分区程序不保留群集节点上的行顺序,因此无法扫描分区键)
然后呢
好吧,因为Cassandra不允许我在分区键上使用不等式,所以就这样吧
我将使version_date成为集群密钥,我的所有问题都将消失。是的,不是真的。。。
第一次尝试:
CREATE TABLE IF NOT EXISTS superdoc_structures (
doc_id varchar,
version_date timestamp,
pre_pos int,
post_pos int,
title text,
PRIMARY KEY (doc_id, version_date, pre_pos, post_pos)
) WITH CLUSTERING ORDER BY (version_date DESC, pre_pos ASC);
我发现这个不那么优雅:所有版本和结构级别都被制作成现在非常宽的行的列(与我以前的解决方案相比):

问题:对于相同的请求,使用<code>LIMIT 1</code>只会返回第一个标题。使用no<code>LIMIT</code>将返回所有版本的结构级别,我必须对其进行过滤,以仅保留最新的版本。
第二次尝试:
还没有第二次尝试...虽然我有一个想法,但我觉得它没有明智地使用卡桑德拉。
这个想法是仅按version_date进行聚类,并以某种方式在每个列值中存储整个层次结构。听起来很糟糕,不是吗?
我会做这样的事情:
CREATE TABLE IF NOT EXISTS superdoc_structures (
doc_id varchar,
version_date timestamp,
nested_sets map<int, int>,
titles list<text>,
PRIMARY KEY (doc_id, version_date)
) WITH CLUSTERING ORDER BY (version_date DESC);
由此产生的行结构将是:

实际上,在我看来,这似乎没什么问题,但我可能会有比级别标题更多的数据去规范化到我的列中。如果只有两个属性,我可以使用另一个地图(例如,将标题与id关联起来),但是更多的数据会导致更多的列表,我感觉它会很快成为反模式
此外,当数据输入时,我必须在我的客户端应用程序中将所有列表合并在一起!
备选方案
我可以使用另一个表格,该表格仅列出超级文档的版本日期
这是两个查询,加上一个要管理的内存缓存存储。但我最终可能会得到一个,所以也许这是最好的妥协?
也许我甚至不需要缓存存储?
总而言之,我真的觉得第一个解决方案是对我的数据进行建模的最优雅的解决方案。你呢?!
共有1个答案

首先,你不需要使用内存缓存或雷迪斯。卡桑德拉将为您提供非常快速的访问该信息的权限。你当然可以有一个这样的表:
create table superdoc_structures {
doc_id varchar;
version_date timestamp;
/* stuff */
primary key (doc_id, version_date)
} with clustering order by (version_date desc);
这将为您提供一种访问给定版本的快速方法(此查询可能看起来很熟悉;-):
select * from superdoc_structures
where doc_id="3399c35...14e1" and
version_date < '2014-03-11'
order by version_date desc
limit 1;
因为从模式的角度来看,文档树结构似乎没有什么关系,而且每次有新版本时,您都很乐意完整地创建文档,所以我不明白您为什么要费心将树拆分为单独的行。为什么不将表中的整个文档作为文本或blob字段?
create table superdoc_structures {
doc_id varchar;
version_date timestamp;
contents text;
primary key (doc_id, version_date)
} with clustering order by (version_date desc);
因此,要获得新年时存在的文档内容,您需要:
select contents from superdoc_structures
where doc_id="...." and
version_date < '2014-01-1'
order by version_date > 1
现在,如果您确实想维护文档组件的某种层次结构,我建议您执行一些操作,例如闭包表表来表示它。或者,既然您愿意在每次写入时复制整个文档,为什么不在每次写入时复制整个部分信息,为什么不这样做并有一个这样的架构:
create table superdoc_structures {
doc_id varchar;
version_date timestamp;
section_path varchar;
contents text;
primary key (doc_id, version_date, section_path)
) with clustering order by (version_date desc, section_path asc);
然后让section path具有类似“第一级下一级子级叶子名称”的语法。另一个好处是,当您拥有文档的version_date时(或者如果您在section_path上创建了一个二级索引),因为空格在词汇上比任何其他有效字符都“低”,所以您实际上可以非常干净地获取一个子部分:
select section_path, contents from superdoc_structures
where doc_id = '....' and
version_date = '2013-12-22' and
section_path >= 'chapter4 subsection2' and
section_path < 'chapter4 subsection2!';
或者,您可以使用Cassandra对集合的支持来存储这些部分,但是……我不知道您为什么要费心将它们分解为一大块,因为这样做非常好。
-
在Tableau中,可以构建层次结构以可视化数据。可以通过以下步骤在Tableau中创建它: 例如,考虑数据源,例如Sample-Superstore,以及它的维度和度量。 第1步: 首先转到工作表。然后, 选择一个维度,然后右键单击该维度以创建层次结构。 转到“层次结构(Hierarchy)”选项。 并且,单击下面屏幕截图中显示的“创建层次结构(Create Hierarchy)”选项。 第2步
-
5.4.1 层次化体系结构 层次化设计是构造复杂系统的一个基本方法,按此方法设计出的系统具有层次化体系结构。现实世界中这种层次化结构俯拾皆是。例如,一幢高楼总是从最底层打基础开始,一层 一层地加高。又如,我国的行政组织具有街道、区、市、省、中央这样的层次化结构。 计算机软件的各个构件也经常组织成这样的层次体系结构。在层次体系中,下层构件为 上层构件提供服务,上层构件使用下层构件的服务,上层和下层之
-
问题内容: 我在 .NET for WinRT(C#)中 ,我想将JSON字符串反序列化为,然后将字典值稍后转换为实际类型。JSON字符串可以包含对象层次结构,我也希望在其中包含子对象。 这是应该能够处理的示例JSON: 我尝试使用 DataContractJsonSerializer 这样做: 实际上,这对于第一个级别是可行的,但是 “父母” 只是一个不能强制转换为的对象: 然后,我尝试使用 J
-
问题内容: 遵循以下两个先前的答案并进行调整以获取所需的结果,我已经成功地在SQL Server 2008中模拟了Oracle CONNECT BY语句。但是如何在LINQ中做到这一点? 这是我正在使用虚拟数据库的示例: 这是用于返回heirachy的SQL: 问题答案: 您可以使用: 也许更好的做法是,创建一个包含查询的视图,然后使用LINQ从该视图读取。
-
我有这样的层次结构: 因此,用户可以添加他的工作经验。此外,他还可以为特定的项目添加角色。 我想为用户id 1获取项目,但项目之间只有关系 获取用户 获得工作经验 获取角色 获取项目 因此,如果我有更多不同工作经验的角色,我就必须提出20个请求才能得到我的项目。这不是很有效率吗?我必须加载一些不必要的数据。。。 是否可以只创建endpoint:并按用户ID过滤它? 应该如何在API上管理它?对我来
-
我是服务器端web开发的新手,最近我读了很多关于实现RESTful API的文章。REST API的一个方面我仍然坚持是如何构建URI层次结构,该层次结构标识客户机可以与之交互的资源。具体地说,我一直在决定在资源由其他资源类型组成的情况下,层次结构有多详细,以及该做些什么。 这里有一个例子,希望能说明我的意思。假设我们有一个web服务,它允许用户从其他用户那里购买产品。所以在这个简单的例子中,有两