
条款5:尽量使用区间成员函数代替它们的单元素兄弟
条款5:尽量使用区间成员函数代替它们的单元素兄弟
快!给定两个vector,v1和v2,使v1的内容和v2的后半部分一样的最简单方式是什么?不要为“当v2有偶数个元素时才有一半”而烦恼,只要做一些合理的东西。
时间到!如果你的答案是
v1.assign(v2.begin() + v2.size() / 2, v2.end());
或者其他很相似的东西,你就答对了,可以获得金质奖章。如果你的答案涉及到多于一条语句,但没有使用任何形式的循环,你接近了正确答案,但没有金质奖章。如果你的答案涉及到一个循环,你就需要花些时间来改进。如果你的答案涉及到多个循环,那好,我们只能说你真的需要这本书。
顺便说说,如果你对这个问题的答案的回答包含了“嗯?”,请高度注意,因为你将会学到一些真的有用的东西。
这个测验设计为做两件事。第一,它提供给我一个机会来提醒你assign成员函数的存在,太多的程序员没注意到这是一个很方便的方法。它对于所有标准序列容器(vector,string,deque和list)都有效。无论何时你必须完全代替一个容器的内容,你就应该想到赋值。如果你只是拷贝一个容器到另一个同类型的容器,operator=就是选择的赋值函数,但对于示范的那个例子,当你想要给一个容器完全的新数据集时,assign就可以利用,但operator=做不了。
这个测验的第二个理由是演示为什么区间成员函数优先于它们的单元素替代品。区间成员函数是一个像STL算法的成员函数,使用两个迭代器参数来指定元素的一个区间来进行某个操作。不用区间成员函数来解决这个条款开头的问题,你就必须写一个显式循环,可能就像这样:
vector<Widget> v1, v2; // 假设v1和v2是Widget的vector v1.clear(); for (vector<Widget>::const_iterator ci = v2.begin() + v2.size() / 2; ci != v2.end(); ++ci) v1.push_back(*ci);
条款43详细验证了为什么你应该尽量避免手写显式循环,但你不必读那个条款就能知道写这段代码比写assign的调用要做多得多的工作。就像我们将马上会看到的,循环也会造成一个效率的损失,但我们一会儿会处理的。
避免循环的一个方法是按照条款43的建议,使用一个算法来代替:
v1.clear(); copy(v2.begin() + v2.size() / 2, v2.end(), back_inserter(v1));
写这些仍然比写assign的调用要做更多的工作。此外,虽然在这段代码中没有表现出循环,在copy中的确存在一个循环(参见条款43)。结果,效率损失仍然存在。我也会在下面讨论。在这里,我要离题一下来指出几乎所有目标区间是通过插入迭代器(比如,通过inserter,back_inserter或front_inserter)指定的copy的使用都可以——应该——通过调用区间成员函数来代替。比如这里,这个copy的调用可以用一个insert的区间版本代替:
v1.insert(v1.end(), v2.begin() + v2.size() / 2, v2.end());
这个输入量稍微比调用copy少,但它发生的也比说的要直接:数据插入v1。调用copy也表达了那个意思,但没那么直接。这把重点放到了错误的地方。对于发生了什么的关注点不应该是元素被拷贝,而是有新的数据加入v1。insert成员函数使这变得清晰了。copy的使用把它变得晦涩。关于东西被拷贝这个事实并没有什么好关注的,因为STL构建在东西会被拷贝的假定上。拷贝对STL来说很基本,它是本书条款3的主题!
太多的STL程序员过度使用copy,所以我重复一遍我的建议:几乎所有目标区间被插入迭代器指定的copy的使用都可以用调用的区间成员函数的来代替。
返回我们的assign的例子,我们已经确定两个尽量使用区间成员函数代替它们的单元素兄弟的理由。
- 一般来说使用区间成员函数可以输入更少的代码。
- 区间成员函数会导致代码更清晰更直接了当。
简而言之,区间成员函数所产生的代码更容易写,更容易理解。不是这样吗?
唉,有些人会把这个论点看作编程风格的问题,而开发者喜欢争论风格问题几乎和喜欢争论什么是真正的编辑器一样。(虽然有很多疑问,但它的确是Emacs。)如果有一个确定区间成员函数优先于它们的单元素兄弟的更普遍赞成的标准将会很有好处。对于标准序列容器,我们有一个:效率。当处理标准序列容器时,应用单元素成员函数比完成同样目的的区间成员函数需要更多地内存分配,更频繁地拷贝对象,而且/或者造成多余操作。
比如,假设你要把一个int数组拷贝到vector前端。(数据可能首先存放在一个数组而不是vector中,因为数据来自于遗留的C API。对于混合使用STL容器和C API的问题的讨论,参见条款16。)使用vector区间insert函数,真的微不足道:
int data[numValues]; // 假设numValues在 // 其他地方定义 vector<int> v; ... v.insert(v.begin(), data, data + numValues); // 把data中的int // 插入v前部
在一个显式循环中使用迭代调用来插入,它可能看起来多多少少像这样:
vector<int>::iterator insertLoc(v.begin());
for (int i = 0; i < numValues; ++i) {
insertLoc = v.insert(insertLoc, data[i]);
++insertLoc;
}
注意我们必须小心保存insert返回值以用于下次循环迭代。如果我们在每次插入后没有更新insertLoc,我们就会有两个问题。首先,所有第一次以后的循环迭代会导致未定义行为,因为每次调用insert会使insertLoc无效。第二,即使insertLoc保持有效,我们总是在vector的前部插入(也就是,在v.begin()),这样的结果就是整数以反序拷贝到v中。
如果我们按照条款43的指引,用调用copy来代替循环,我们会得出像这样的东西:
copy(data, data + numValues, inserter(v, v.begin()));
这次演示了copy模板,这段代码基于copy,这和使用显式循环的代码几乎一样,所以处于效率分析的目的,我们会关注于显示循环,要牢记分析也是一样有效于使用copy的代码。着眼于显式循环可以更容易地了解效率冲击都在哪里。是的,“冲击”是复数,因为使用insert单元素版本的代码对你征收了三种不同的性能税,而如果你用区间版本的insert,则一种都没有。
第一种税在于没有必要的函数调用。把numValues个元素插入v,每次一个,自然会花费你numValues次调用insert。使用insert的区间形式,你只要花费一次调用,节省了numValues-1次调用。当然,可能的内联会使你节省这种税,但再次说明,它也可能不会。只有一件事情是确定的,使用insert的区间形式,你明确地不必为此花费。
内联也节省不了你的第二种税——无效率地把v中的现有元素移动到它们最终插入后的位置的开销。每次调用insert来增加一个新元素到v,插入点以上的每个元素都必须向上移动一次来为新元素腾出空间。所以在位置p的元素必须向上移动到位置p+1等。在我们的例子中,我们在v的前部插入了numValues个元素。那意味着在v中每个插入之前的元素都得向上移动一共numValues个位置。但每次insert调用时每个只能向上移动一个位置,所以每个元素一共会被移动numValues次。如果v在插入前有n个元素,则一共会发生n*numValues次移动。在这个例子里,v容纳int,所以每次移动可能会归结为一次memmove调用,但如果v容纳了用户自定义类型比如Widget,每次移动会导致调用那个类型的赋值操作符或者拷贝构造函数。(大部分是调用赋值操作符,但每次vector的最后一个元素被移动,那个移动会通过调用元素的拷贝构造函数来完成。)于是在一般情况下,把numValues个新对象每次一个地插入容纳了n个元素的vector<Widget>的前部需要花费n*numValues次函数调用:(n-1)*numValues调用Widget赋值操作符和numValues调用Widget拷贝构造函数。即使这些调用内联了,你仍然做了移动numValues次v中的元素的工作。
相反的是,标准要求区间insert函数直接把现有元素移动到它们最后的位置,也就是,开销是每个元素一次移动。总共开销是n次移动,numValues次容器中的对象类型的拷贝构造函数,剩下的是类型的赋值操作符。相比单元素插入策略,区间insert少执行了n*(numValues-1)次移动。花一分钟想想。这意味着如果numValues是100,insert的区间形式会比重复调用insert的单元素形式的代码少花费99%的移动!
在我转向单元素成员函数和它们的区间兄弟的第三个效率开销前,我有一个小修正。我在前面写的段落都是真理,而且除了真理没别的了,但并不是真理的全部。仅当可以不用失去两个迭代器的位置就能决定它们之间的距离时,一个区间insert函数才能在一次移动中把一个元素移动到它的最终位置。这几乎总是可能的,因为所有前向迭代器提供了这个功能,而且前向迭代器几乎到处都是。所有用于标准容器的迭代器都提供了前向迭代器的功能。非标准的散列容器(参见条款25)的迭代器也是。在数组中表现为迭代器的指针也提供了这样的功能。事实上,唯一不提供前向迭代器能力的标准迭代器是输入和输出迭代器。因此,除了当传给insert区间形式的迭代器是输入迭代器(比如istream_iterator——参见条款6)外,我在上面写的东西都是真的。在那个唯一的情况下,区间插入必须每次一位地把元素移动到它们的最终位置,期望中的优点就消失了。(对于输出迭代器,这个问题不会发生,因为输出迭代器不能用于为insert指定一个区间。)
留下的最后一种性能税很愚蠢,重复使用单元素插入而不是一个区间插入就必须处理内存分配,虽然在它里面也有一个令人讨厌的拷贝。就像条款14解释的,当你试图去把一个元素插入内存已经满了的vector时,这个vector会分配具有更多容量的新内存,从旧内存把它的元素拷贝到新内存,销毁旧内存里的元素,回收旧内存。然后它添加插入的元素。条款14也解释了每当用完内存时,大部分vector实现都使它们的容量翻倍,所以插入numValues个新元素会导致最多log2numValues次新内存的分配。条款14也关注了展示该行为的现有实现,所以每次一个地插入1000个元素会导致10次新的分配(包括它们负责的元素拷贝)。与之对比的是(而且,就目前来看,是可预测的),一个区间插入可以在开始插入东西前计算出需要多少新内存(假设给的是前向迭代器),所以它不用多于一次地重新分配vector的内在内存。就像你可以想象到的,这个节省相当可观。
我刚才进行分析是用于vector的,但同样的理由也作用于string。对于deque,理由也很相似,但deque管理它们内存的方式和vector和string不同,所以重复内存分配的论点不能应用。但是,关于很多次不必要的元素移动的论点通常通过对函数调用次数的观察也应用到了(虽然细节不同)。
在标准序列容器中,就剩下list了,在这里使用insert区间形式代替单元素形式也有一个性能优势。关于重复函数调用的论点当然继续有效,但因为链表的工作方式,拷贝和内存分配问题没有发生。取而代之的是,这里有一个新问题:过多重复地对list中的一些节点的next和prev指针赋值。
每当一个元素添加到一个链表时,持有元素的链表节点必须有它的next和prev指针集,而且当然新节点前面的节点(我们叫它B,就是“before”)必须设置它的next指针,新节点后面的节点(我们叫它A,就是“after”)必须设置它的prev指针:
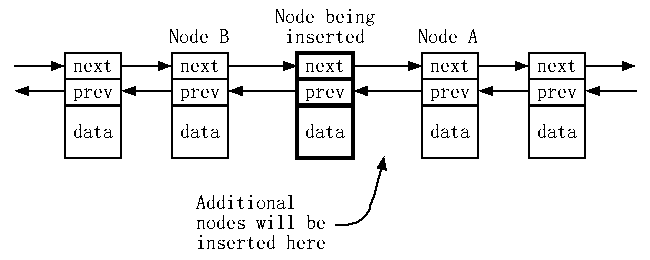
当一系列新节点通过调用list的单元素insert一个接一个添加时,除了最后一个以外的其他新节点都会设置它的next指针两次,第一次指向A,第二次指向在它后面插入的元素。每次在A前面插入时,它都会设置它的prev指针指向一个新节点。如果numValues个节点插入A前面,插入节点的next指针会发生numValues-1次多余的赋值,而且A的prev指针会发生numValues-1次多余的赋值。合计2*(numValues-1)次没有必要的指针赋值。当然,指针赋值很轻量,但如果不是必须,为什么要为它们花费呢?
现在已经很清楚你可以不必,避免开销的关键是使用list的insert区间形式。因为那个函数知道最后有多少节点会被插入,它可以避免多余的指针赋值,对每个指针只使用一次赋值就能设置它正确的插入后的值。
对于标准序列容器,当在单元素插入和区间插入之间选择时,除编程风格之外还有很多东西都浮出水面。对于关联容器,效率问题几乎没有,但是附加的重复调用单元素insert函数的开销问题仍然存在。此外,区间插入的特别类型在关联容器中也可能导致优化,但据我所知,这样的优化目前只存在于理论中。当然,在你看到这点的时候,理论可能已经变成实践了,所以关联容器的区间插入可能变得比单元素插入更有效。毫无疑问它们不会降低效率,所以你选择它们没有任何损失。
即使没有效率的论点,当你写代码时使用区间成员函数需要更少的输入这个事实仍然存在,它产生的代码也更容易懂,从而增强你软件的长期维护。只要两个特性就足以使你尽量选择区间成员函数。效率优势真的只是一个红利。
经历了关于区间成员函数的奇迹的长篇大论后,只需要我为你总结一下就可以了。知道那个成员函数支持区间可以使你更容易去发现使用它们的时机。在下面的,参数类型iterator意思是容器的迭代器类型,也就是container::iterator。另一方面,参数类型InputIterator意思是可以接受任何输入迭代器。
- 区间构造。所有标准容器都提供这种形式的构造函数:
container::container(InputIterator begin, // 区间的起点 InputIterator end); // 区间的终点
如果传给这个构造函数的迭代器是istream_iterators或istreambuf_iterators(参见条款29),你可能会遇到C++的最惊异的解析,原因之一是你的编译器可能会因为把这个构造看作一个函数声明而不是一个新容器对象的定义而中断。条款6告诉你需要知道所有关于解析的东西,包括怎么对付它。
- 区间插入。所有标准序列容器都提供这种形式的insert:
void container::insert(iterator position, // 区间插入的位置 InputIterator begin, // 插入区间的起点 InputIterator end); // 插入区间的终点
关联容器使用它们的比较函数来决定元素要放在哪里,所以它们了省略position参数。
void container::insert(lnputIterator begin, InputIterator end);
当寻找用区间版本代替单元素插入的方法时,不要忘记有些单元素变量用采用不同的函数名伪装它们自己。比如,push_front和push_back都把单元素插入容器,即使它们不叫insert。如果你看见一个循环调用push_front或push_back,或如果你看见一个算法——比如copy——的参数是front_inserter或者back_inserter,你就发现了一个insert的区间形式应该作为优先策略的地方。
- 区间删除。每个标准容器都提供了一个区间形式的erase,但是序列和关联容器的返回类型不同。序列容器提供了这个:
iterator container::erase(iterator begin, iterator end);
而关联容器提供这个:
void container::erase(iterator begin, iterator end);
为什么不同?解释是如果erase的关联容器版本返回一个迭代器(被删除的那个元素的下一个)会招致一个无法接受的性能下降。我是众多发现这个徒有其表的解释的人之一,但标准说的就是标准说的,标准说erase的序列和关联容器版本有不同的返回类型。
这个条款的对insert的性能分析大部分也同样可以用于erase。单元素删除的函数调用次数仍然大于一次调用区间删除。当使用单元素删除时,每一次元素值仍然必须向它们的目的地移动一位,而区间删除可以在一个单独的移动中把它们移动到目标位置。
关于vector和string的插入和删除的一个论点是必须做很多重复的分配。(当然对于删除,会发生重复的回收。)那是因为用于vector和string的内存自动增长来适应于新元素,但当元素的数目减少时它不自动收缩。(条款17描述了你怎么减少被vector或string持有的不必要的内存。)
一个非常重要的区间erase的表现是erase-remove惯用法。你可以在条款32了解到所有关于它的信息。
- 区间赋值。就像我在这个条款的一开始提到的,所有标准列容器都提供了区间形式的assign:
void container::assign(InputIterator begin, InputIterator end);
所以现在我们明白了,尽量使用区间成员函数来代替单元素兄弟的三个可靠的论点。区间成员函数更容易写,它们更清楚地表达你的意图,而且它们提供了更高的性能。那是很难打败的三驾马车。