
导读
你已经熟悉了STL。你知道怎么建立容器,迭代它们的内容,添加删除元素和应用常见算法,比如find和sort。但你并不满足,你不能摆脱STL所提供的超过它们能带来的好处的感觉。应该简单的任务并非那样。应该直截了当的操作确有资源泄漏或错误行为。应该高效的过程却需要比你希望给它们的更多的时间和内存。是的,你知道怎么使用STL,但你不确定你在有效地使用它。
我为你写了这本书。
在《Effective STL》中,我解释了怎样结合STL组件来在库的设计得到最大的好处。这样的信息允许你对简单、直接的问题开发简单、直接的解决方案,也帮你对更复杂的问题设计优雅的方法。我描述了常见的STL使用错误,而且向你演示怎么避开它们。那帮助你躲开闪资源漏、不可移植的代码和未定义的行为。我讨论了优化代码的方法,所以你能使STL表现得像它应该的那样快速、光滑。
本书里的信息将使你成为一个更好的STL程序员,它将让你成为一个更高产的程序员。而且它将让你成为一个更愉快的程序员,使用STL很有趣,但是有效地使用它更为有趣,这种有趣是它们必须把你拽离键盘,因为你不能相信你争拥有的好时光。即使对STL的匆匆一瞥也能发现它是一个非常酷的库,但这份酷比你可能想象的更宽更深。我在本书的一个主要目标是传达给你这个库有多神奇,因为在我编程的差不多30年里,我从未见过任何像STL的东西。你或许也没有。
定义、使用和扩展STL
没有“STL”的官方定义,而且当人们使用这个术语时,不同的人表示的是不同的东西。在本书中,“STL”的意思是与迭代器合作的C++标准库的一部分。那包括标准容器(包括string),iostream库的一部分,函数对象和算法。它不包括标准容器适配器(stack、queue和priority_queue)以及bitset和valarray容器,因为它们缺乏迭代器支持。它也不包括数组。真的,数组以指针的形式支持迭代器,但数组是C++语言的一部分,并非库。
技术上,我的STL的定义排除了标准C++库的扩展,特别是散列容器,单链表,rope和多种非标准函数对象。虽然如此,一个有效的STL程序员需要知道这样的扩展,因此我在合适的地方提到了它们。的确,条款25致力于非标准散列容器的概述。它们现在不在STL里,但类似它们的东西几乎肯定将要进入标准C++库的下一个版本,而在窥见未来是有价值的。
存在STL扩展的原因之一是STL是被设计为可扩展的库。不过,在本书里,我关注于使用STL,而不是给它添加新的组件。例如,如果你发现,我没有说多少关于写你自己的算法的东西,而且我根本没有在写新容器和迭代器上提供指导。我相信在你着手增加它的能力之前,掌握STL已经提供的东西很重要,所以那是我在《Effective STL》里关注的。当你决定建立你自己STLesque组件时,你将在像Josuttis的《The C++ Standard Library》[3]和Austern的《Generic Programming and the STL》[4]这样的书里找到建议。我确实在这本书里讨论的STL扩展的一个方面是写你自己的函数对象。你不可能在不知道怎么写自己的函数对象的情况下有效地使用STL,所以我为这个主题投入了整整一章(第6章)。
引用
先前段落中对Josuttis和Austern的书的引用演示了我怎么处理书目引用的。通常,我试图提及引用的足够信息以便已经熟悉它的人能够鉴别出来。例如,如果你已经知道这些作者的书,就不必转向参考书目那里查明[3]和[4]提及的你已经知道的书。当然,如果你不熟悉一个出版物,参考书目(从第225页开始)会给你全面的引用。
我经常引用三个一般没有使用引用编号的东西。第一个是C++国际标准[5],我通常把它简称为“标准”。其他两个是我早先关于C++的书,《Effective C++》[1]和《More Effective C++》[2]。
STL和标准
我经常提及C++标准,因为《Effective STL》专注于可移植的,与标准一致的C++。理论上,我在这本书里演示的一切都可以用于每个C++实现。实际上,那不是真的。编译器的缺陷和STL实现凑合成防止一些有效的代码编译或表现出它们应该有的行为。那是很常见的情况,我描述了这些问题,而且解释了你应该怎么变通地解决他们。
有时候,最容易的变通办法是使用另一个STL实现。附录B给一个这种情况的例子。实际上,STL用得越多,编译器和库实现的区别就越重要。程序员在设法让合法的代码编译时遇到困难,他们通常责备他们的编译器,但对于STL,编译器可能是好的,而STL实现是不良的。为了强调你得依赖编译器和库实现的事实,我使用你的STL平台。一个STL平台是一个特定编译器和一个标准模板库特定实现的组合。在本书里,如果我提及一个编译器问题,你能确信我意思是编译器有问题。但是,如果我说你的STL平台有问题,你应该理解为“可能是编译器缺陷,可能是库缺陷,或许都有”。
我一般提及你的“编译器们”——复数。那是我长期相信你通过确保代码可以在多于一个的编译器上工作的方法来改进你的代码质量(特别是移植性)的产物。此外,使用多个编译器一般可以简化拆解由STL的使用不当造成的错误信息难题。(条款49致力于解码此类消息的方法。)
关于与标准一致的代码,我强调的另一个方面是你应该避免构造未定义行为。这样的构造可能在运行期做任何事情。不幸的是,这意味着它们可能正好做了你想要的,而那会导致一种错误的安全感。太多程序员以为未定义行为总会导致一个明显的问题,例如,一个分段错误或其他灾难性的错误。未定义行为的结果实际上更为狡猾,例如,破坏极少引用的数据。它们也可以通过程序运行。我发现一个未定义行为的好定义是“为我工作,为你工作,在开发和QA期间工作,但在你最重要的用户面前爆炸了”。避免未定义行为很重要,所以我指出了它会出现的通常情况。你应该训练你自己警惕这样的情况。
引用计数
讨论STL而没有提及引用计数是几乎不可能的。正如你将在条款7和33看见的,基于指针的容器的设计几乎总要导致引用计数。另外, 很多string实现内部是引用计数的,而且,正如条款15解释的,这可能是一个你不能忽视的实现细节。在本书里,我认为你已经熟悉引用的基础。如果你不是,大多数中级和高级C++教材都覆盖了这个主题。例如,在《More Effective C++》里,相关材料是在条款28和29。如果你不知道引用计数是什么而且你不喜欢学习,不要担心。你也可以读完本书,虽然这里那里可能有一些句子不像它们应该的那么有意义。
string和wstring
我关于string说的任何东西都可以相等地应用到给它的宽字符兄弟,wstring。类似地,任何时候我提及string和char或char*之间的关系,对于wstring和wchar_t或wchar_t*之间的关序也是正确的。换句话说,只是因为我在本书里不明确地提及宽字符字符串,不要以为STL不能支持它们。它也像基于char的字符串一样支持它们。它必须。string和wstring都是同一个模板的实例化,basic_string。
术语,术语,术语
这不是STL的入门书,所以我认为你知道基本的东西。仍然,下面的术语十分重要,我感到需要强迫复习它们:
- vector、string、deque和list被称为标准序列容器。标准关联容器被是set、multiset、map和multimap。
- 迭代器被分成五个种类,基于它们支持的操作。简要地说,输入迭代器是每个迭代位置只能被读一次的只读迭代器。输出迭代器是每个迭代位置只能被写一次的只写迭代器。输入和输出迭代器被塑造为读和写输入和输出流(例如,文件)。因此并不奇怪输入和输出迭代器最通常的表现分别是istream_iterator和ostream_iterator。
前向迭代器有输入和输出迭代器的能力,但是它们可以反复读或写一个位置。它们不支持operator--,所以它们可以高效地向前移动任意次数。所有标准STL容器都支持比前向迭代器更强大的迭代器,但是,正如你可以在条款25看到的,散列容器的一种设计可以产生前向迭代器。单链表容器(在条款50提到)也提供前向迭代器。
双向迭代器就像前向迭代器,除了它们的后退可以像前进一样容易。标准关联容器都提供双向迭代器。list也有。
随机访问迭代器可以做双向迭代器做的一切事情,但它们也提供“迭代器算术”,即,有一步向前或向后跳的能力。vector、string和deque都提供随机访问迭代器。指进数组的指针可以作为数组的随机访问迭代器。
- 重载了函数调用操作符(即,operator())的任何类叫做仿函数类。从这样的类建立的对象称为函数对象或仿函数。STL中大部分可以使用函数对象的地方也都可以用真函数,所以我经常使用术语“函数对象”来表示C++函数和真的函数对象。
- 函数bind1st和bind2nd称为绑定器。
STL的一个革命性方面是它的复杂度保证。这些保证约束了任何STL操作允许表现的工作量。这极好,因为它可以帮你确定同一问题不同方法的相对效率,不论你使用的是什么STL平台。不幸的是,如果你不了解计算机科学的行话,在复杂度保证后面的专有名词可能会把你弄糊涂。这里有一个关于我在本书里使用的复杂度术语的快速入门。每个都引用了它作为n的函数做一件事情要多久,n是容器或区间的元素数目。
- 以常数时间执行的操作的性能不受n的改变而影响,例如,向list中插入一个元素是一个常数时间操作。不管list有一个还是一百万个元素,插入都花费同样数量的时间。
不要太照字面理解占用“常数时间”。 它不意味着做某些事情所花费时间的数量是字面上的常数,它只表明不被n影响。例如,两个STL平台可能花费非常不同数量的时间执行相同的“常数时间”操作。如果一个库比另一个有更复杂的实现,或如果一个编译器执行了充分的更积极优化的时候,这就会发生。
常数时间复杂度的一个变体是分摊常数时间。以分摊常数时间运行的操作通常是常数时间的操作,但偶尔它们花的时间也取决于n。分摊常数时间操作通常以常数时间运行。
- 当n变大时,以对数时间运行的操作需要更多的时间运行,但它需要的时间以与n的对数成正比的比率增长。例如,在一百万个项上的一次操作预计花费大约在一百个项上三倍的时间,因为log n3 = 3 log n。在关联容器上的大多数搜寻操作(例如,set::find)是对数时间操作。
- 以线性时间运行的操作需要的时间以与n成正比的比率增长。标准算法count以线性时间运行,因为它必须查看给定区间中的每个元素。如果区间的大小扩大了三倍,它也必须做三倍的工作,而且我们期望它大约花费三倍时间来完成。
通常,常数时间操作运行得比要求对数时间的快,而对数时间操作运行得比线性的快。当n变得足够大时,这总是真的,但对于n相对小的值,有时候更差理论复杂度的操作可能或胜过更好理论复杂度的操作。如果你想对知道更多STL复杂度保证的东西,转向Josuttis的《The C++ Standard Library》[3]。
术语的最后一个要注意的东西是,记住map或multimap里的每个元素都有两个组件。我一般叫第一个组件键,叫第二个组件值。以
map<string, double> m;
为例,string是键,double是值。
代码例子
这本书充满了例子代码,当我引入每个例子时我都作了解释。不过仍然值得提前知道一些事情。
你可以从上面map的例子看到我通常忽略#include,而且忽视STL组件在namespace std里的事实。当定义map m,我可以这么写,
#include <map> #include <string> using std::map; using std::string; map<string, double> m;
但我喜欢让我们省掉这些噪音。
当我为一个模板声明一个形式类型参数时,我使用typename而不是class。即,不这么写,
template<class T>
class Widget { ... };
我这么写:
template<typename T>
class Widget { ... };
用这个场景里,class和typename表示完全相同的东西,但我发现typename能更清楚地表示我通常想要说的:T可以是任何类型;不必是一个类。如果你喜欢使用class来声明类型参数,那也可以。在这个场景里是用typename或class完全是风格的问题。
在另一个场景里,这不再是风格问题。为了避免潜在的解析含糊(我将提供给你细节),你被要求在依赖形式类型参数的类型名字之前使用typename。这样的类型被称为依赖类型,一个例子将帮助阐明我所说的。假设你想为函数写一个模板,给定一个STL容器,返回容器中的最后一个元素是否大于第一个元素。这是一种方法:
template<typename C>
bool lastGreaterThanFirst(const C& container)
{
if (container.empty()) return false;
typename C::const_iterator begin(container, begin());
typename C::const_ierator end(container.end());
return *--end > *begin;
}
在这个例子里,局部变量begin和end的类型是C::const_iterator。const_iterator是依赖形式类型参数C的一种类型。因为C::const_iterator是一种依赖类型,你被要求在它之前放上typename这个词。(一些编译器错误地接受没有typename的代码,但这样的代码不可移植。)
我希望你注意到了在上面例子里我对颜色的使用。那是为了让你的注意力集中于特别重要的部分代码。通常,我加亮相关例子之间的差别,正如我在Widget例子里演示两种可能的声明参数T的方法。用于唤起例子中特别值得注意的部分的颜色也延伸到图表。例如,来自条款5的这张图使用颜色来区分当新元素被插入list时受影响的两个指针:
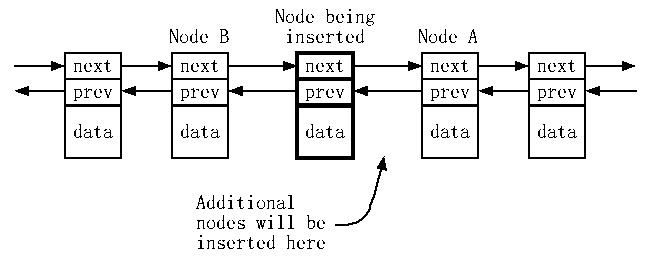
我也为章号使用颜色,但这样的使用完全没有理由。这作为我的第一本两色的书,我希望你能原谅我的一点色彩丰富。
我最喜爱的参数名中的有两个是lhs和rhs。它们分别代表“左手边”和“右手边”,而且当声明操作符时,我发现它们特别有用。 这是来自条款19的一个例子:
class Widget { ... };
bool operator==(const Widget& Ihs, const Widget& rhs);
当这个函数在这样的场景下被调用时,
if (x == y) ... // 假设x和y是Widget
x,在“==”的左边,在operator==里面被称为lhs,而y被称为rhs。
至于类名Widget,与GUI或者工具无关。这指示我为“做某件事的某个类”使用的名字。有时,正如第7页上的,Widget是一个类模板而不是一个类。在这样的情况里,你可能发现我仍然称Widget为一个类,即使这真的是一个模板。只要对讨论的东西不会产生歧义,忽略类和类模板、结构体和结构体模板、函数和函数模板之间的差别就不会伤害任何人。在可能混淆的情况下,我会分清模板和它们产生的类、结构体和函数。
涉及效率的条款
我考虑过在《Effective STL》中包含一章关于效率的,但我最后决定当前的组织是更好的。仍然,许多项目关注与减少空间和运行期需要。为了方便你的性能提高,这里有一张包含实际上关于效率的章节的表:
| 条款4:用empty来代替检查size()是否为0 | 23 |
| 条款5:尽量使用区间成员函数代替它们的单元素兄弟 | 24 |
| 条款14:使用reserve来避免不必要的重新分配 | 66 |
| 条款15:小心string实现的多样性 | 68 |
| 条款23:考虑用有序vector代替关联容器 | 100 |
| 条款24:当关乎效率时应该在map::operator[]和map-insert之间仔细选择 | 106 |
| 条款25:熟悉非标准散列容器 | 111 |
| 条款29:需要一个一个字符输入时考虑使用istreambuf_iterator | 126 |
| 条款31:了解你的排序选择 | 133 |
| 条款44:尽量用成员函数代替同名的算法 | 190 |
| 条款46:考虑使用函数对象代替函数作算法的参数 | 201 |
《Effective STL》的方针
构成本书50个条款的方针是基于世界上最有经验的STL程序员的见解和建议。这些方针总结了你应该总是做的——或总是避免做的——以发挥标准模板库的最大功效。同时,它们只是方针。在一些条件下,违反它们是有意义的。例如,条款7的标题告诉你在容器销毁前应该删除容器内new得的指针,但那个条款的正文说明只适用于当容器销毁时被那些指针指向的对象也得跟随而去的情况。情况经常如此,但不永远为真。类似的,条款35的标题恳求你使用STL算法进行简单的忽略大小写字符串比较,但条款的正文指出在一些情况里,你最好使用不仅在STL之外,而且甚至不是标准C++一部分的一个函数!
只有你足够了解你正写的软件,它运行的环境,以及建立它的场景,才能确定违反我提出的方针是否合理。多数时候,不是,而且伴随每个条款的讨论解释了为什么。在一些情况里,它是。对指南奴隶般的盲从是不对的,但骑士般的漠视也不对。在一个人冒险之前,你应该保证你有一个好原因。