
第8章 对象的容纳
“如果一个程序只含有数量固定的对象,而且已知它们的存在时间,那么这个程序可以说是相当简单的。”
通常,我们的程序需要根据程序运行时才知道的一些标准创建新对象。若非程序正式运行,否则我们根本不知道自己到底需要多少数量的对象,甚至不知道它们的准确类型。为了满足常规编程的需要,我们要求能在任何时候、任何地点创建任意数量的对象。所以不可依赖一个已命名的句柄来容纳自己的每一个对象,就象下面这样:
MyObject myHandle;
因为根本不知道自己实际需要多少这样的东西。
为解决这个非常关键的问题,Java提供了容纳对象(或者对象的句柄)的多种方式。其中内建的类型是数组,我们之前已讨论过它,本章准备加深大家对它的认识。此外,Java的工具(实用程序)库提供了一些“集合类”(亦称作“容器类”,但该术语已由AWT使用,所以这里仍采用“集合”这一称呼)。利用这些集合类,我们可以容纳乃至操纵自己的对象。本章的剩余部分会就此进行详细讨论。
8.1 数组
对数组的大多数必要的介绍已在第4章的最后一节进行。通过那里的学习,大家已知道自己该如何定义及初始化一个数组。对象的容纳是本章的重点,而数组只是容纳对象的一种方式。但由于还有其他大量方法可容纳数组,所以是哪些地方使数组显得如此特别呢?
有两方面的问题将数组与其他集合类型区分开来:效率和类型。对于Java来说,为保存和访问一系列对象(实际是对象的句柄)数组,最有效的方法莫过于数组。数组实际代表一个简单的线性序列,它使得元素的访问速度非常快,但我们却要为这种速度付出代价:创建一个数组对象时,它的大小是固定的,而且不可在那个数组对象的“存在时间”内发生改变。可创建特定大小的一个数组,然后假如用光了存储空间,就再创建一个新数组,将所有句柄从旧数组移到新数组。这属于“矢量”(Vector)类的行为,本章稍后还会详细讨论它。然而,由于为这种大小的灵活性要付出较大的代价,所以我们认为矢量的效率并没有数组高。
C++的矢量类知道自己容纳的是什么类型的对象,但同Java的数组相比,它却有一个明显的缺点:C++矢量类的operator[]不能进行范围检查,所以很容易超出边界(然而,它可以查询vector有多大,而且at()方法确实能进行范围检查)。在Java中,无论使用的是数组还是集合,都会进行范围检查——若超过边界,就会获得一个RuntimeException(运行期违例)错误。正如大家在第9章会学到的那样,这类违例指出的是一个程序员错误,所以不需要在代码中检查它。在另一方面,由于C++的vector不进行范围检查,所以访问速度较快——在Java中,由于对数组和集合都要进行范围检查,所以对性能有一定的影响。
本章还要学习另外几种常见的集合类:Vector(矢量)、Stack(堆栈)以及Hashtable(散列表)。这些类都涉及对对象的处理——好象它们没有特定的类型。换言之,它们将其当作Object类型处理(Object类型是Java中所有类的“根”类)。从某个角度看,这种处理方法是非常合理的:我们仅需构建一个集合,然后任何Java对象都可以进入那个集合(除基本数据类型外——可用Java的基本类型封装类将其作为常数置入集合,或者将其封装到自己的类内,作为可以变化的值使用)。这再一次反映了数组优于常规集合:创建一个数组时,可令其容纳一种特定的类型。这意味着可进行编译期类型检查,预防自己设置了错误的类型,或者错误指定了准备提取的类型。当然,在编译期或者运行期,Java会防止我们将不当的消息发给一个对象。所以我们不必考虑自己的哪种做法更加危险,只要编译器能及时地指出错误,同时在运行期间加快速度,目的也就达到了。此外,用户很少会对一次违例事件感到非常惊讶的。
考虑到执行效率和类型检查,应尽可能地采用数组。然而,当我们试图解决一个更常规的问题时,数组的局限也可能显得非常明显。在研究过数组以后,本章剩余的部分将把重点放到Java提供的集合类身上。
8.1.1 数组和第一类对象
无论使用的数组属于什么类型,数组标识符实际都是指向真实对象的一个句柄。那些对象本身是在内存“堆”里创建的。堆对象既可“隐式”创建(即默认产生),亦可“显式”创建(即明确指定,用一个new表达式)。堆对象的一部分(实际是我们能访问的唯一字段或方法)是只读的length(长度)成员,它告诉我们那个数组对象里最多能容纳多少元素。对于数组对象,“[]”语法是我们能采用的唯一另类访问方法。
下面这个例子展示了对数组进行初始化的不同方式,以及如何将数组句柄分配给不同的数组对象。它也揭示出对象数组和基本数据类型数组在使用方法上几乎是完全一致的。唯一的差别在于对象数组容纳的是句柄,而基本数据类型数组容纳的是具体的数值(若在执行此程序时遇到困难,请参考第3章的“赋值”小节):
//: ArraySize.java
// Initialization & re-assignment of arrays
package c08;
class Weeble {} // A small mythical creature
public class ArraySize {
public static void main(String[] args) {
// Arrays of objects:
Weeble[] a; // Null handle
Weeble[] b = new Weeble[5]; // Null handles
Weeble[] c = new Weeble[4];
for(int i = 0; i < c.length; i++)
c[i] = new Weeble();
Weeble[] d = {
new Weeble(), new Weeble(), new Weeble()
};
// Compile error: variable a not initialized:
//!System.out.println("a.length=" + a.length);
System.out.println("b.length = " + b.length);
// The handles inside the array are
// automatically initialized to null:
for(int i = 0; i < b.length; i++)
System.out.println("b[" + i + "]=" + b[i]);
System.out.println("c.length = " + c.length);
System.out.println("d.length = " + d.length);
a = d;
System.out.println("a.length = " + a.length);
// Java 1.1 initialization syntax:
a = new Weeble[] {
new Weeble(), new Weeble()
};
System.out.println("a.length = " + a.length);
// Arrays of primitives:
int[] e; // Null handle
int[] f = new int[5];
int[] g = new int[4];
for(int i = 0; i < g.length; i++)
g[i] = i*i;
int[] h = { 11, 47, 93 };
// Compile error: variable e not initialized:
//!System.out.println("e.length=" + e.length);
System.out.println("f.length = " + f.length);
// The primitives inside the array are
// automatically initialized to zero:
for(int i = 0; i < f.length; i++)
System.out.println("f[" + i + "]=" + f[i]);
System.out.println("g.length = " + g.length);
System.out.println("h.length = " + h.length);
e = h;
System.out.println("e.length = " + e.length);
// Java 1.1 initialization syntax:
e = new int[] { 1, 2 };
System.out.println("e.length = " + e.length);
}
} ///:~Here’s the output from the program:
b.length = 5 b[0]=null b[1]=null b[2]=null b[3]=null b[4]=null c.length = 4 d.length = 3 a.length = 3 a.length = 2 f.length = 5 f[0]=0 f[1]=0 f[2]=0 f[3]=0 f[4]=0 g.length = 4 h.length = 3 e.length = 3 e.length = 2
其中,数组a只是初始化成一个null句柄。此时,编译器会禁止我们对这个句柄作任何实际操作,除非已正确地初始化了它。数组b被初始化成指向由Weeble句柄构成的一个数组,但那个数组里实际并未放置任何Weeble对象。然而,我们仍然可以查询那个数组的大小,因为b指向的是一个合法对象。这也为我们带来了一个难题:不可知道那个数组里实际包含了多少个元素,因为length只告诉我们可将多少元素置入那个数组。换言之,我们只知道数组对象的大小或容量,不知其实际容纳了多少个元素。尽管如此,由于数组对象在创建之初会自动初始化成null,所以可检查它是否为null,判断一个特定的数组“空位”是否容纳一个对象。类似地,由基本数据类型构成的数组会自动初始化成零(针对数值类型)、null(字符类型)或者false(布尔类型)。
数组c显示出我们首先创建一个数组对象,再将Weeble对象赋给那个数组的所有“空位”。数组d揭示出“集合初始化”语法,从而创建数组对象(用new命令明确进行,类似于数组c),然后用Weeble对象进行初始化,全部工作在一条语句里完成。
下面这个表达式:
a = d;
向我们展示了如何取得同一个数组对象连接的句柄,然后将其赋给另一个数组对象,就象我们针对对象句柄的其他任何类型做的那样。现在,a和d都指向内存堆内同样的数组对象。
Java 1.1加入了一种新的数组初始化语法,可将其想象成“动态集合初始化”。由d采用的Java 1.0集合初始化方法则必须在定义d的同时进行。但若采用Java 1.1的语法,却可以在任何地方创建和初始化一个数组对象。例如,假设hide()方法用于取得一个Weeble对象数组,那么调用它时传统的方法是:
hide(d);
但在Java 1.1中,亦可动态创建想作为参数传递的数组,如下所示:
hide(new Weeble[] {new Weeble(), new Weeble() });
这一新式语法使我们在某些场合下写代码更方便了。
上述例子的第二部分揭示出这样一个问题:对于由基本数据类型构成的数组,它们的运作方式与对象数组极为相似,只是前者直接包容了基本类型的数据值。
1. 基本数据类型集合
集合类只能容纳对象句柄。但对一个数组,却既可令其直接容纳基本类型的数据,亦可容纳指向对象的句柄。利用象Integer、Double之类的“封装器”类,可将基本数据类型的值置入一个集合里。但正如本章后面会在WordCount.java例子中讲到的那样,用于基本数据类型的封装器类只是在某些场合下才能发挥作用。无论将基本类型的数据置入数组,还是将其封装进入位于集合的一个类内,都涉及到执行效率的问题。显然,若能创建和访问一个基本数据类型数组,那么比起访问一个封装数据的集合,前者的效率会高出许多。
当然,假如准备一种基本数据类型,同时又想要集合的灵活性(在需要的时候可自动扩展,腾出更多的空间),就不宜使用数组,必须使用由封装的数据构成的一个集合。大家或许认为针对每种基本数据类型,都应有一种特殊类型的Vector。但Java并未提供这一特性。某些形式的建模机制或许会在某一天帮助Java更好地解决这个问题(注释①)。
①:这儿是C++比Java做得好的一个地方,因为C++通过template关键字提供了对“参数化类型”的支持。
8.1.2 数组的返回
假定我们现在想写一个方法,同时不希望它仅仅返回一样东西,而是想返回一系列东西。此时,象C和C++这样的语言会使问题复杂化,因为我们不能返回一个数组,只能返回指向数组的一个指针。这样就非常麻烦,因为很难控制数组的“存在时间”,它很容易造成内存“漏洞”的出现。
Java采用的是类似的方法,但我们能“返回一个数组”。当然,此时返回的实际仍是指向数组的指针。但在Java里,我们永远不必担心那个数组的是否可用——只要需要,它就会自动存在。而且垃圾收集器会在我们完成后自动将其清除。
作为一个例子,请思考如何返回一个字串数组:
//: IceCream.java
// Returning arrays from methods
public class IceCream {
static String[] flav = {
"Chocolate", "Strawberry",
"Vanilla Fudge Swirl", "Mint Chip",
"Mocha Almond Fudge", "Rum Raisin",
"Praline Cream", "Mud Pie"
};
static String[] flavorSet(int n) {
// Force it to be positive & within bounds:
n = Math.abs(n) % (flav.length + 1);
String[] results = new String[n];
int[] picks = new int[n];
for(int i = 0; i < picks.length; i++)
picks[i] = -1;
for(int i = 0; i < picks.length; i++) {
retry:
while(true) {
int t =
(int)(Math.random() * flav.length);
for(int j = 0; j < i; j++)
if(picks[j] == t) continue retry;
picks[i] = t;
results[i] = flav[t];
break;
}
}
return results;
}
public static void main(String[] args) {
for(int i = 0; i < 20; i++) {
System.out.println(
"flavorSet(" + i + ") = ");
String[] fl = flavorSet(flav.length);
for(int j = 0; j < fl.length; j++)
System.out.println("\t" + fl[j]);
}
}
} ///:~flavorSet()方法创建了一个名为results的String数组。该数组的大小为n——具体数值取决于我们传递给方法的自变量。随后,它从数组flav里随机挑选一些“香料”(Flavor),并将它们置入results里,并最终返回results。返回数组与返回其他任何对象没什么区别——最终返回的都是一个句柄。至于数组到底是在flavorSet()里创建的,还是在其他什么地方创建的,这个问题并不重要,因为反正返回的仅是一个句柄。一旦我们的操作完成,垃圾收集器会自动关照数组的清除工作。而且只要我们需要数组,它就会乖乖地听候调遣。
另一方面,注意当flavorSet()随机挑选香料的时候,它需要保证以前出现过的一次随机选择不会再次出现。为达到这个目的,它使用了一个无限while循环,不断地作出随机选择,直到发现未在picks数组里出现过的一个元素为止(当然,也可以进行字串比较,检查随机选择是否在results数组里出现过,但字串比较的效率比较低)。若成功,就添加这个元素,并中断循环(break),再查找下一个(i值会递增)。但假若t是一个已在picks里出现过的数组,就用标签式的continue往回跳两级,强制选择一个新t。用一个调试程序可以很清楚地看到这个过程。
main()能显示出20个完整的香料集合,所以我们看到flavorSet()每次都用一个随机顺序选择香料。为体会这一点,最简单的方法就是将输出重导向进入一个文件,然后直接观看这个文件的内容。
8.2 集合
现在总结一下我们前面学过的东西:为容纳一组对象,最适宜的选择应当是数组。而且假如容纳的是一系列基本数据类型,更是必须采用数组。在本章剩下的部分,大家将接触到一些更常规的情况。当我们编写程序时,通常并不能确切地知道最终需要多少个对象。有些时候甚至想用更复杂的方式来保存对象。为解决这个问题,Java提供了四种类型的“集合类”:Vector(矢量)、BitSet(位集)、Stack(堆栈)以及Hashtable(散列表)。与拥有集合功能的其他语言相比,尽管这儿的数量显得相当少,但仍然能用它们解决数量惊人的实际问题。
这些集合类具有形形色色的特征。例如,Stack实现了一个LIFO(先入先出)序列,而Hashtable是一种“关联数组”,允许我们将任何对象关联起来。除此以外,所有Java集合类都能自动改变自身的大小。所以,我们在编程时可使用数量众多的对象,同时不必担心会将集合弄得有多大。
8.2.1 缺点:类型未知
使用Java集合的“缺点”是在将对象置入一个集合时丢失了类型信息。之所以会发生这种情况,是由于当初编写集合时,那个集合的程序员根本不知道用户到底想把什么类型置入集合。若指示某个集合只允许特定的类型,会妨碍它成为一个“常规用途”的工具,为用户带来麻烦。为解决这个问题,集合实际容纳的是类型为Object的一些对象的句柄。这种类型当然代表Java中的所有对象,因为它是所有类的根。当然,也要注意这并不包括基本数据类型,因为它们并不是从“任何东西”继承来的。这是一个很好的方案,只是不适用下述场合:
(1) 将一个对象句柄置入集合时,由于类型信息会被抛弃,所以任何类型的对象都可进入我们的集合——即便特别指示它只能容纳特定类型的对象。举个例子来说,虽然指示它只能容纳猫,但事实上任何人都可以把一条狗扔进来。
(2) 由于类型信息不复存在,所以集合能肯定的唯一事情就是自己容纳的是指向一个对象的句柄。正式使用它之前,必须对其进行造型,使其具有正确的类型。
值得欣慰的是,Java不允许人们滥用置入集合的对象。假如将一条狗扔进一个猫的集合,那么仍会将集合内的所有东西都看作猫,所以在使用那条狗时会得到一个“违例”错误。在同样的意义上,假若试图将一条狗的句柄“造型”到一只猫,那么运行期间仍会得到一个“违例”错误。
下面是个例子:
//: CatsAndDogs.java
// Simple collection example (Vector)
import java.util.*;
class Cat {
private int catNumber;
Cat(int i) {
catNumber = i;
}
void print() {
System.out.println("Cat #" + catNumber);
}
}
class Dog {
private int dogNumber;
Dog(int i) {
dogNumber = i;
}
void print() {
System.out.println("Dog #" + dogNumber);
}
}
public class CatsAndDogs {
public static void main(String[] args) {
Vector cats = new Vector();
for(int i = 0; i < 7; i++)
cats.addElement(new Cat(i));
// Not a problem to add a dog to cats:
cats.addElement(new Dog(7));
for(int i = 0; i < cats.size(); i++)
((Cat)cats.elementAt(i)).print();
// Dog is detected only at run-time
}
} ///:~可以看出,Vector的使用是非常简单的:先创建一个,再用addElement()置入对象,以后用elementAt()取得那些对象(注意Vector有一个size()方法,可使我们知道已添加了多少个元素,以便防止误超边界,造成违例错误)。
Cat和Dog类都非常浅显——除了都是“对象”之外,它们并无特别之处(倘若不明确指出从什么类继承,就默认为从Object继承。所以我们不仅能用Vector方法将Cat对象置入这个集合,也能添加Dog对象,同时不会在编译期和运行期得到任何出错提示。用Vector方法elementAt()获取原本认为是Cat的对象时,实际获得的是指向一个Object的句柄,必须将那个对象造型为Cat。随后,需要将整个表达式用括号封闭起来,在为Cat调用print()方法之前进行强制造型;否则就会出现一个语法错误。在运行期间,如果试图将Dog对象造型为Cat,就会得到一个违例。
这些处理的意义都非常深远。尽管显得有些麻烦,但却获得了安全上的保证。我们从此再难偶然造成一些隐藏得深的错误。若程序的一个部分(或几个部分)将对象插入一个集合,但我们只是通过一次违例在程序的某个部分发现一个错误的对象置入了集合,就必须找出插入错误的位置。当然,可通过检查代码达到这个目的,但这或许是最笨的调试工具。另一方面,我们可从一些标准化的集合类开始自己的编程。尽管它们在功能上存在一些不足,且显得有些笨拙,但却能保证没有隐藏的错误。
1. 错误有时并不显露出来
在某些情况下,程序似乎正确地工作,不造型回我们原来的类型。第一种情况是相当特殊的:String类从编译器获得了额外的帮助,使其能够正常工作。只要编译器期待的是一个String对象,但它没有得到一个,就会自动调用在Object里定义、并且能够由任何Java类覆盖的toString()方法。这个方法能生成满足要求的String对象,然后在我们需要的时候使用。
因此,为了让自己类的对象能显示出来,要做的全部事情就是覆盖toString()方法,如下例所示:
//: WorksAnyway.java
// In special cases, things just seem
// to work correctly.
import java.util.*;
class Mouse {
private int mouseNumber;
Mouse(int i) {
mouseNumber = i;
}
// Magic method:
public String toString() {
return "This is Mouse #" + mouseNumber;
}
void print(String msg) {
if(msg != null) System.out.println(msg);
System.out.println(
"Mouse number " + mouseNumber);
}
}
class MouseTrap {
static void caughtYa(Object m) {
Mouse mouse = (Mouse)m; // Cast from Object
mouse.print("Caught one!");
}
}
public class WorksAnyway {
public static void main(String[] args) {
Vector mice = new Vector();
for(int i = 0; i < 3; i++)
mice.addElement(new Mouse(i));
for(int i = 0; i < mice.size(); i++) {
// No cast necessary, automatic call
// to Object.toString():
System.out.println(
"Free mouse: " + mice.elementAt(i));
MouseTrap.caughtYa(mice.elementAt(i));
}
}
} ///:~可在Mouse里看到对toString()的重定义代码。在main()的第二个for循环中,可发现下述语句:
System.out.println("Free mouse: " +
mice.elementAt(i));
在“+”后,编译器预期看到的是一个String对象。elementAt()生成了一个Object,所以为获得希望的String,编译器会默认调用toString()。但不幸的是,只有针对String才能得到象这样的结果;其他任何类型都不会进行这样的转换。
隐藏造型的第二种方法已在Mousetrap里得到了应用。caughtYa()方法接收的不是一个Mouse,而是一个Object。随后再将其造型为一个Mouse。当然,这样做是非常冒失的,因为通过接收一个Object,任何东西都可以传递给方法。然而,假若造型不正确——如果我们传递了错误的类型——就会在运行期间得到一个违例错误。这当然没有在编译期进行检查好,但仍然能防止问题的发生。注意在使用这个方法时毋需进行造型:
MouseTrap.caughtYa(mice.elementAt(i));
2. 生成能自动判别类型的Vector
大家或许不想放弃刚才那个问题。一个更“健壮”的方案是用Vector创建一个新类,使其只接收我们指定的类型,也只生成我们希望的类型。如下所示:
//: GopherVector.java
// A type-conscious Vector
import java.util.*;
class Gopher {
private int gopherNumber;
Gopher(int i) {
gopherNumber = i;
}
void print(String msg) {
if(msg != null) System.out.println(msg);
System.out.println(
"Gopher number " + gopherNumber);
}
}
class GopherTrap {
static void caughtYa(Gopher g) {
g.print("Caught one!");
}
}
class GopherVector {
private Vector v = new Vector();
public void addElement(Gopher m) {
v.addElement(m);
}
public Gopher elementAt(int index) {
return (Gopher)v.elementAt(index);
}
public int size() { return v.size(); }
public static void main(String[] args) {
GopherVector gophers = new GopherVector();
for(int i = 0; i < 3; i++)
gophers.addElement(new Gopher(i));
for(int i = 0; i < gophers.size(); i++)
GopherTrap.caughtYa(gophers.elementAt(i));
}
} ///:~这前一个例子类似,只是新的GopherVector类有一个类型为Vector的private成员(从Vector继承有些麻烦,理由稍后便知),而且方法也和Vector类似。然而,它不会接收和产生普通Object,只对Gopher对象感兴趣。
由于GopherVector只接收一个Gopher(地鼠),所以假如我们使用:
gophers.addElement(new Pigeon());
就会在编译期间获得一条出错消息。采用这种方式,尽管从编码的角度看显得更令人沉闷,但可以立即判断出是否使用了正确的类型。
注意在使用elementAt()时不必进行造型——它肯定是一个Gopher。
3. 参数化类型
这类问题并不是孤立的——我们许多时候都要在其他类型的基础上创建新类型。此时,在编译期间拥有特定的类型信息是非常有帮助的。这便是“参数化类型”的概念。在C++中,它由语言通过“模板”获得了直接支持。至少,Java保留了关键字generic,期望有一天能够支持参数化类型。但我们现在无法确定这一天何时会来临。
8.3 枚举器(反复器)
在任何集合类中,必须通过某种方法在其中置入对象,再用另一种方法从中取得对象。毕竟,容纳各种各样的对象正是集合的首要任务。在Vector中,addElement()便是我们插入对象采用的方法,而elementAt()是提取对象的唯一方法。Vector非常灵活,我们可在任何时候选择任何东西,并可使用不同的索引选择多个元素。
若从更高的角度看这个问题,就会发现它的一个缺陷:需要事先知道集合的准确类型,否则无法使用。乍看来,这一点似乎没什么关系。但假若最开始决定使用Vector,后来在程序中又决定(考虑执行效率的原因)改变成一个List(属于Java1.2集合库的一部分),这时又该如何做呢?
可利用“反复器”(Iterator)的概念达到这个目的。它可以是一个对象,作用是遍历一系列对象,并选择那个序列中的每个对象,同时不让客户程序员知道或关注那个序列的基础结构。此外,我们通常认为反复器是一种“轻量级”对象;也就是说,创建它只需付出极少的代价。但也正是由于这个原因,我们常发现反复器存在一些似乎很奇怪的限制。例如,有些反复器只能朝一个方向移动。
Java的Enumeration(枚举,注释②)便是具有这些限制的一个反复器的例子。除下面这些外,不可再用它做其他任何事情:
(1) 用一个名为elements()的方法要求集合为我们提供一个Enumeration。我们首次调用它的nextElement()时,这个Enumeration会返回序列中的第一个元素。
(2) 用nextElement()获得下一个对象。
(3) 用hasMoreElements()检查序列中是否还有更多的对象。
②:“反复器”这个词在C++和OOP的其他地方是经常出现的,所以很难确定为什么Java的开发者采用了这样一个奇怪的名字。Java 1.2的集合库修正了这个问题以及其他许多问题。
只可用Enumeration做这些事情,不能再有更多。它属于反复器一种简单的实现方式,但功能依然十分强大。为体会它的运作过程,让我们复习一下本章早些时候提到的CatsAndDogs.java程序。在原始版本中,elementAt()方法用于选择每一个元素,但在下述修订版中,可看到使用了一个“枚举”:
//: CatsAndDogs2.java
// Simple collection with Enumeration
import java.util.*;
class Cat2 {
private int catNumber;
Cat2(int i) {
catNumber = i;
}
void print() {
System.out.println("Cat number " +catNumber);
}
}
class Dog2 {
private int dogNumber;
Dog2(int i) {
dogNumber = i;
}
void print() {
System.out.println("Dog number " +dogNumber);
}
}
public class CatsAndDogs2 {
public static void main(String[] args) {
Vector cats = new Vector();
for(int i = 0; i < 7; i++)
cats.addElement(new Cat2(i));
// Not a problem to add a dog to cats:
cats.addElement(new Dog2(7));
Enumeration e = cats.elements();
while(e.hasMoreElements())
((Cat2)e.nextElement()).print();
// Dog is detected only at run-time
}
} ///:~我们看到唯一的改变就是最后几行。不再是:
for(int i = 0; i < cats.size(); i++)
((Cat)cats.elementAt(i)).print();
而是用一个Enumeration遍历整个序列:
while(e.hasMoreElements())
((Cat2)e.nextElement()).print();
使用Enumeration,我们不必关心集合中的元素数量。所有工作均由hasMoreElements()和nextElement()自动照管了。
下面再看看另一个例子,让我们创建一个常规用途的打印方法:
//: HamsterMaze.java
// Using an Enumeration
import java.util.*;
class Hamster {
private int hamsterNumber;
Hamster(int i) {
hamsterNumber = i;
}
public String toString() {
return "This is Hamster #" + hamsterNumber;
}
}
class Printer {
static void printAll(Enumeration e) {
while(e.hasMoreElements())
System.out.println(
e.nextElement().toString());
}
}
public class HamsterMaze {
public static void main(String[] args) {
Vector v = new Vector();
for(int i = 0; i < 3; i++)
v.addElement(new Hamster(i));
Printer.printAll(v.elements());
}
} ///:~仔细研究一下打印方法:
static void printAll(Enumeration e) {
while(e.hasMoreElements())
System.out.println(
e.nextElement().toString());
}注意其中没有与序列类型有关的信息。我们拥有的全部东西便是Enumeration。为了解有关序列的情况,一个Enumeration便足够了:可取得下一个对象,亦可知道是否已抵达了末尾。取得一系列对象,然后在其中遍历,从而执行一个特定的操作——这是一个颇有价值的编程概念,本书许多地方都会沿用这一思路。
这个看似特殊的例子甚至可以更为通用,因为它使用了常规的toString()方法(之所以称为常规,是由于它属于Object类的一部分)。下面是调用打印的另一个方法(尽管在效率上可能会差一些):
System.out.println("" + e.nextElement());
它采用了封装到Java内部的“自动转换成字串”技术。一旦编译器碰到一个字串,后面跟随一个“+”,就会希望后面又跟随一个字串,并自动调用toString()。在Java 1.1中,第一个字串是不必要的;所有对象都会转换成字串。亦可对此执行一次造型,获得与调用toString()同样的效果:
System.out.println((String)e.nextElement())
但我们想做的事情通常并不仅仅是调用Object方法,所以会再度面临类型造型的问题。对于自己感兴趣的类型,必须假定自己已获得了一个Enumeration,然后将结果对象造型成为那种类型(若操作错误,会得到运行期违例)。
8.4 集合的类型
标准Java 1.0和1.1库配套提供了非常少的一系列集合类。但对于自己的大多数编程要求,它们基本上都能胜任。正如大家到本章末尾会看到的,Java 1.2提供的是一套重新设计过的大型集合库。
8.4.1 Vector
Vector的用法很简单,这已在前面的例子中得到了证明。尽管我们大多数时候只需用addElement()插入对象,用elementAt()一次提取一个对象,并用elements()获得对序列的一个“枚举”。但仍有其他一系列方法是非常有用的。同我们对于Java库惯常的做法一样,在这里并不使用或讲述所有这些方法。但请务必阅读相应的电子文档,对它们的工作有一个大概的认识。
1. 崩溃Java
Java标准集合里包含了toString()方法,所以它们能生成自己的String表达方式,包括它们容纳的对象。例如在Vector中,toString()会在Vector的各个元素中步进和遍历,并为每个元素调用toString()。假定我们现在想打印出自己类的地址。看起来似乎简单地引用this即可(特别是C++程序员有这样做的倾向):
//: CrashJava.java
// One way to crash Java
import java.util.*;
public class CrashJava {
public String toString() {
return "CrashJava address: " + this + "\n";
}
public static void main(String[] args) {
Vector v = new Vector();
for(int i = 0; i < 10; i++)
v.addElement(new CrashJava());
System.out.println(v);
}
} ///:~若只是简单地创建一个CrashJava对象,并将其打印出来,就会得到无穷无尽的一系列违例错误。然而,假如将CrashJava对象置入一个Vector,并象这里演示的那样打印Vector,就不会出现什么错误提示,甚至连一个违例都不会出现。此时Java只是简单地崩溃(但至少它没有崩溃我的操作系统)。这已在Java 1.1中测试通过。
此时发生的是字串的自动类型转换。当我们使用下述语句时:
"CrashJava address: " + this
编译器就在一个字串后面发现了一个“+”以及好象并非字串的其他东西,所以它会试图将this转换成一个字串。转换时调用的是toString(),后者会产生一个递归调用。若在一个Vector内出现这种事情,看起来堆栈就会溢出,同时违例控制机制根本没有机会作出响应。
若确实想在这种情况下打印出对象的地址,解决方案就是调用Object的toString方法。此时就不必加入this,只需使用super.toString()。当然,采取这种做法也有一个前提:我们必须从Object直接继承,或者没有一个父类覆盖了toString方法。
8.4.2 BitSet
BitSet实际是由“二进制位”构成的一个Vector。如果希望高效率地保存大量“开-关”信息,就应使用BitSet。它只有从尺寸的角度看才有意义;如果希望的高效率的访问,那么它的速度会比使用一些固有类型的数组慢一些。
此外,BitSet的最小长度是一个长整数(Long)的长度:64位。这意味着假如我们准备保存比这更小的数据,如8位数据,那么BitSet就显得浪费了。所以最好创建自己的类,用它容纳自己的标志位。
在一个普通的Vector中,随我们加入越来越多的元素,集合也会自我膨胀。在某种程度上,BitSet也不例外。也就是说,它有时会自行扩展,有时则不然。而且Java的1.0版本似乎在这方面做得最糟,它的BitSet表现十分差强人意(Java1.1已改正了这个问题)。下面这个例子展示了BitSet是如何运作的,同时演示了1.0版本的错误:
//: Bits.java
// Demonstration of BitSet
import java.util.*;
public class Bits {
public static void main(String[] args) {
Random rand = new Random();
// Take the LSB of nextInt():
byte bt = (byte)rand.nextInt();
BitSet bb = new BitSet();
for(int i = 7; i >=0; i--)
if(((1 << i) & bt) != 0)
bb.set(i);
else
bb.clear(i);
System.out.println("byte value: " + bt);
printBitSet(bb);
short st = (short)rand.nextInt();
BitSet bs = new BitSet();
for(int i = 15; i >=0; i--)
if(((1 << i) & st) != 0)
bs.set(i);
else
bs.clear(i);
System.out.println("short value: " + st);
printBitSet(bs);
int it = rand.nextInt();
BitSet bi = new BitSet();
for(int i = 31; i >=0; i--)
if(((1 << i) & it) != 0)
bi.set(i);
else
bi.clear(i);
System.out.println("int value: " + it);
printBitSet(bi);
// Test bitsets >= 64 bits:
BitSet b127 = new BitSet();
b127.set(127);
System.out.println("set bit 127: " + b127);
BitSet b255 = new BitSet(65);
b255.set(255);
System.out.println("set bit 255: " + b255);
BitSet b1023 = new BitSet(512);
// Without the following, an exception is thrown
// in the Java 1.0 implementation of BitSet:
// b1023.set(1023);
b1023.set(1024);
System.out.println("set bit 1023: " + b1023);
}
static void printBitSet(BitSet b) {
System.out.println("bits: " + b);
String bbits = new String();
for(int j = 0; j < b.size() ; j++)
bbits += (b.get(j) ? "1" : "0");
System.out.println("bit pattern: " + bbits);
}
} ///:~随机数字生成器用于创建一个随机的byte、short和int。每一个都会转换成BitSet内相应的位模型。此时一切都很正常,因为BitSet是64位的,所以它们都不会造成最终尺寸的增大。但在Java 1.0中,一旦BitSet大于64位,就会出现一些令人迷惑不解的行为。假如我们设置一个只比BitSet当前分配存储空间大出1的一个位,它能够正常地扩展。但一旦试图在更高的位置设置位,同时不先接触边界,就会得到一个恼人的违例。这正是由于BitSet在Java 1.0里不能正确扩展造成的。本例创建了一个512位的BitSet。构建器分配的存储空间是位数的两倍。所以假如设置位1024或更高的位,同时没有先设置位1023,就会在Java 1.0里得到一个违例。但幸运的是,这个问题已在Java 1.1得到了改正。所以如果是为Java 1.0写代码,请尽量避免使用BitSet。
8.4.3 Stack
Stack有时也可以称为“后入先出”(LIFO)集合。换言之,我们在堆栈里最后“压入”的东西将是以后第一个“弹出”的。和其他所有Java集合一样,我们压入和弹出的都是“对象”,所以必须对自己弹出的东西进行“造型”。
一种很少见的做法是拒绝使用Vector作为一个Stack的基本构成元素,而是从Vector里“继承”一个Stack。这样一来,它就拥有了一个Vector的所有特征及行为,另外加上一些额外的Stack行为。很难判断出设计者到底是明确想这样做,还是属于一种固有的设计。
下面是一个简单的堆栈示例,它能读入数组的每一行,同时将其作为字串压入堆栈。
//: Stacks.java
// Demonstration of Stack Class
import java.util.*;
public class Stacks {
static String[] months = {
"January", "February", "March", "April",
"May", "June", "July", "August", "September",
"October", "November", "December" };
public static void main(String[] args) {
Stack stk = new Stack();
for(int i = 0; i < months.length; i++)
stk.push(months[i] + " ");
System.out.println("stk = " + stk);
// Treating a stack as a Vector:
stk.addElement("The last line");
System.out.println(
"element 5 = " + stk.elementAt(5));
System.out.println("popping elements:");
while(!stk.empty())
System.out.println(stk.pop());
}
} ///:~months数组的每一行都通过push()继承进入堆栈,稍后用pop()从堆栈的顶部将其取出。要声明的一点是,Vector操作亦可针对Stack对象进行。这可能是由继承的特质决定的——Stack“属于”一种Vector。因此,能对Vector进行的操作亦可针对Stack进行,例如elementAt()方法。
8.4.4 Hashtable
Vector允许我们用一个数字从一系列对象中作出选择,所以它实际是将数字同对象关联起来了。但假如我们想根据其他标准选择一系列对象呢?堆栈就是这样的一个例子:它的选择标准是“最后压入堆栈的东西”。这种“从一系列对象中选择”的概念亦可叫作一个“映射”、“字典”或者“关联数组”。从概念上讲,它看起来象一个Vector,但却不是通过数字来查找对象,而是用另一个对象来查找它们!这通常都属于一个程序中的重要进程。
在Java中,这个概念具体反映到抽象类Dictionary身上。该类的接口是非常直观的size()告诉我们其中包含了多少元素;isEmpty()判断是否包含了元素(是则为true);put(Object key, Object value)添加一个值(我们希望的东西),并将其同一个键关联起来(想用于搜索它的东西);get(Object key)获得与某个键对应的值;而remove(Object Key)用于从列表中删除“键-值”对。还可以使用枚举技术:keys()产生对键的一个枚举(Enumeration);而elements()产生对所有值的一个枚举。这便是一个Dictionary(字典)的全部。
Dictionary的实现过程并不麻烦。下面列出一种简单的方法,它使用了两个Vector,一个用于容纳键,另一个用来容纳值:
//: AssocArray.java
// Simple version of a Dictionary
import java.util.*;
public class AssocArray extends Dictionary {
private Vector keys = new Vector();
private Vector values = new Vector();
public int size() { return keys.size(); }
public boolean isEmpty() {
return keys.isEmpty();
}
public Object put(Object key, Object value) {
keys.addElement(key);
values.addElement(value);
return key;
}
public Object get(Object key) {
int index = keys.indexOf(key);
// indexOf() Returns -1 if key not found:
if(index == -1) return null;
return values.elementAt(index);
}
public Object remove(Object key) {
int index = keys.indexOf(key);
if(index == -1) return null;
keys.removeElementAt(index);
Object returnval = values.elementAt(index);
values.removeElementAt(index);
return returnval;
}
public Enumeration keys() {
return keys.elements();
}
public Enumeration elements() {
return values.elements();
}
// Test it:
public static void main(String[] args) {
AssocArray aa = new AssocArray();
for(char c = 'a'; c <= 'z'; c++)
aa.put(String.valueOf(c),
String.valueOf(c)
.toUpperCase());
char[] ca = { 'a', 'e', 'i', 'o', 'u' };
for(int i = 0; i < ca.length; i++)
System.out.println("Uppercase: " +
aa.get(String.valueOf(ca[i])));
}
} ///:~在对AssocArray的定义中,我们注意到的第一个问题是它“扩展”了字典。这意味着AssocArray属于Dictionary的一种类型,所以可对其发出与Dictionary一样的请求。如果想生成自己的Dictionary,而且就在这里进行,那么要做的全部事情只是填充位于Dictionary内的所有方法(而且必须覆盖所有方法,因为它们——除构建器外——都是抽象的)。
Vector key和value通过一个标准索引编号链接起来。也就是说,如果用“roof”的一个键以及“blue”的一个值调用put()——假定我们准备将一个房子的各部分与它们的油漆颜色关联起来,而且AssocArray里已有100个元素,那么“roof”就会有101个键元素,而“blue”有101个值元素。而且要注意一下get(),假如我们作为键传递“roof”,它就会产生与keys.index.Of()的索引编号,然后用那个索引编号生成相关的值矢量内的值。
main()中进行的测试是非常简单的;它只是将小写字符转换成大写字符,这显然可用更有效的方式进行。但它向我们揭示出了AssocArray的强大功能。
标准Java库只包含Dictionary的一个变种,名为Hashtable(散列表,注释③)。Java的散列表具有与AssocArray相同的接口(因为两者都是从Dictionary继承来的)。但有一个方面却反映出了差别:执行效率。若仔细想想必须为一个get()做的事情,就会发现在一个Vector里搜索键的速度要慢得多。但此时用散列表却可以加快不少速度。不必用冗长的线性搜索技术来查找一个键,而是用一个特殊的值,名为“散列码”。散列码可以获取对象中的信息,然后将其转换成那个对象“相对唯一”的整数(int)。所有对象都有一个散列码,而hashCode()是根类Object的一个方法。Hashtable获取对象的hashCode(),然后用它快速查找键。这样可使性能得到大幅度提升(④)。散列表的具体工作原理已超出了本书的范围(⑤)——大家只需要知道散列表是一种快速的“字典”(Dictionary)即可,而字典是一种非常有用的工具。
③:如计划使用RMI(在第15章详述),应注意将远程对象置入散列表时会遇到一个问题(参阅《Core Java》,作者Conrell和Horstmann,Prentice-Hall 1997年出版)
④:如这种速度的提升仍然不能满足你对性能的要求,甚至可以编写自己的散列表例程,从而进一步加快表格的检索过程。这样做可避免在与Object之间进行造型的时间延误,也可以避开由Java类库散列表例程内建的同步过程。
⑤:我的知道的最佳参考读物是《Practical Algorithms for Programmers》,作者为Andrew Binstock和John Rex,Addison-Wesley 1995年出版。
作为应用散列表的一个例子,可考虑用一个程序来检验Java的Math.random()方法的随机性到底如何。在理想情况下,它应该产生一系列完美的随机分布数字。但为了验证这一点,我们需要生成数量众多的随机数字,然后计算落在不同范围内的数字多少。散列表可以极大简化这一工作,因为它能将对象同对象关联起来(此时是将Math.random()生成的值同那些值出现的次数关联起来)。如下所示:
//: Statistics.java
// Simple demonstration of Hashtable
import java.util.*;
class Counter {
int i = 1;
public String toString() {
return Integer.toString(i);
}
}
class Statistics {
public static void main(String[] args) {
Hashtable ht = new Hashtable();
for(int i = 0; i < 10000; i++) {
// Produce a number between 0 and 20:
Integer r =
new Integer((int)(Math.random() * 20));
if(ht.containsKey(r))
((Counter)ht.get(r)).i++;
else
ht.put(r, new Counter());
}
System.out.println(ht);
}
} ///:~在main()中,每次产生一个随机数字,它都会封装到一个Integer对象里,使句柄能够随同散列表一起使用(不可对一个集合使用基本数据类型,只能使用对象句柄)。containKey()方法检查这个键是否已经在集合里(也就是说,那个数字以前发现过吗?)若已在集合里,则get()方法获得那个键关联的值,此时是一个Counter(计数器)对象。计数器内的值i随后会增加1,表明这个特定的随机数字又出现了一次。
假如键以前尚未发现过,那么方法put()仍然会在散列表内置入一个新的“键-值”对。在创建之初,Counter会自己的变量i自动初始化为1,它标志着该随机数字的第一次出现。
为显示散列表,只需把它简单地打印出来即可。Hashtable toString()方法能遍历所有键-值对,并为每一对都调用toString()。Integer toString()是事先定义好的,可看到计数器使用的toString。一次运行的结果(添加了一些换行)如下:
{19=526, 18=533, 17=460, 16=513, 15=521, 14=495,
13=512, 12=483, 11=488, 10=487, 9=514, 8=523,
7=497, 6=487, 5=480, 4=489, 3=509, 2=503, 1=475,
0=505}大家或许会对Counter类是否必要感到疑惑,它看起来似乎根本没有封装类Integer的功能。为什么不用int或Integer呢?事实上,由于所有集合能容纳的仅有对象句柄,所以根本不可以使用整数。学过集合后,封装类的概念对大家来说就可能更容易理解了,因为不可以将任何基本数据类型置入集合里。然而,我们对Java封装器能做的唯一事情就是将其初始化成一个特定的值,然后读取那个值。也就是说,一旦封装器对象已经创建,就没有办法改变一个值。这使得Integer封装器对解决我们的问题毫无意义,所以不得不创建一个新类,用它来满足自己的要求。
1. 创建“关键”类
在前面的例子里,我们用一个标准库的类(Integer)作为Hashtable的一个键使用。作为一个键,它能很好地工作,因为它已经具备正确运行的所有条件。但在使用散列表的时候,一旦我们创建自己的类作为键使用,就会遇到一个很常见的问题。例如,假设一套天气预报系统将Groundhog(土拔鼠)对象匹配成Prediction(预报)。这看起来非常直观:我们创建两个类,然后将Groundhog作为键使用,而将Prediction作为值使用。如下所示:
//: SpringDetector.java
// Looks plausible, but doesn't work right.
import java.util.*;
class Groundhog {
int ghNumber;
Groundhog(int n) { ghNumber = n; }
}
class Prediction {
boolean shadow = Math.random() > 0.5;
public String toString() {
if(shadow)
return "Six more weeks of Winter!";
else
return "Early Spring!";
}
}
public class SpringDetector {
public static void main(String[] args) {
Hashtable ht = new Hashtable();
for(int i = 0; i < 10; i++)
ht.put(new Groundhog(i), new Prediction());
System.out.println("ht = " + ht + "\n");
System.out.println(
"Looking up prediction for groundhog #3:");
Groundhog gh = new Groundhog(3);
if(ht.containsKey(gh))
System.out.println((Prediction)ht.get(gh));
}
} ///:~每个Groundhog都具有一个标识号码,所以赤了在散列表中查找一个Prediction,只需指示它“告诉我与Groundhog号码3相关的Prediction”。Prediction类包含了一个布尔值,用Math.random()进行初始化,以及一个toString()为我们解释结果。在main()中,用Groundhog以及与它们相关的Prediction填充一个散列表。散列表被打印出来,以便我们看到它们确实已被填充。随后,用标识号码为3的一个Groundhog查找与Groundhog #3对应的预报。
看起来似乎非常简单,但实际是不可行的。问题在于Groundhog是从通用的Object根类继承的(若当初未指定基础类,则所有类最终都是从Object继承的)。事实上是用Object的hashCode()方法生成每个对象的散列码,而且默认情况下只使用它的对象的地址。所以,Groundhog(3)的第一个实例并不会产生与Groundhog(3)第二个实例相等的散列码,而我们用第二个实例进行检索。
大家或许认为此时要做的全部事情就是正确地覆盖hashCode()。但这样做依然行不能,除非再做另一件事情:覆盖也属于Object一部分的equals()。当散列表试图判断我们的键是否等于表内的某个键时,就会用到这个方法。同样地,默认的Object.equals()只是简单地比较对象地址,所以一个Groundhog(3)并不等于另一个Groundhog(3)。
因此,为了在散列表中将自己的类作为键使用,必须同时覆盖hashCode()和equals(),就象下面展示的那样:
//: SpringDetector2.java
// If you create a class that's used as a key in
// a Hashtable, you must override hashCode()
// and equals().
import java.util.*;
class Groundhog2 {
int ghNumber;
Groundhog2(int n) { ghNumber = n; }
public int hashCode() { return ghNumber; }
public boolean equals(Object o) {
return (o instanceof Groundhog2)
&& (ghNumber == ((Groundhog2)o).ghNumber);
}
}
public class SpringDetector2 {
public static void main(String[] args) {
Hashtable ht = new Hashtable();
for(int i = 0; i < 10; i++)
ht.put(new Groundhog2(i),new Prediction());
System.out.println("ht = " + ht + "\n");
System.out.println(
"Looking up prediction for groundhog #3:");
Groundhog2 gh = new Groundhog2(3);
if(ht.containsKey(gh))
System.out.println((Prediction)ht.get(gh));
}
} ///:~注意这段代码使用了来自前一个例子的Prediction,所以SpringDetector.java必须首先编译,否则就会在试图编译SpringDetector2.java时得到一个编译期错误。
Groundhog2.hashCode()将土拔鼠号码作为一个标识符返回(在这个例子中,程序员需要保证没有两个土拔鼠用同样的ID号码并存)。为了返回一个独一无二的标识符,并不需要hashCode(),equals()方法必须能够严格判断两个对象是否相等。
equals()方法要进行两种检查:检查对象是否为null;若不为null,则继续检查是否为Groundhog2的一个实例(要用到instanceof关键字,第11章会详加论述)。即使为了继续执行equals(),它也应该是一个Groundhog2。正如大家看到的那样,这种比较建立在实际ghNumber的基础上。这一次一旦我们运行程序,就会看到它终于产生了正确的输出(许多Java库的类都覆盖了hashcode()和equals()方法,以便与自己提供的内容适应)。
2. 属性:Hashtable的一种类型
在本书的第一个例子中,我们使用了一个名为Properties(属性)的Hashtable类型。在那个例子中,下述程序行:
Properties p = System.getProperties();
p.list(System.out);
调用了一个名为getProperties()的static方法,用于获得一个特殊的Properties对象,对系统的某些特征进行描述。list()属于Properties的一个方法,可将内容发给我们选择的任何流式输出。也有一个save()方法,可用它将属性列表写入一个文件,以便日后用load()方法读取。
尽管Properties类是从Hashtable继承的,但它也包含了一个散列表,用于容纳“默认”属性的列表。所以假如没有在主列表里找到一个属性,就会自动搜索默认属性。
Properties类亦可在我们的程序中使用(第17章的ClassScanner.java便是一例)。在Java库的用户文档中,往往可以找到更多、更详细的说明。
8.4.5 再论枚举器
我们现在可以开始演示Enumeration(枚举)的真正威力:将穿越一个序列的操作与那个序列的基础结构分隔开。在下面的例子里,PrintData类用一个Enumeration在一个序列中移动,并为每个对象都调用toString()方法。此时创建了两个不同类型的集合:一个Vector和一个Hashtable。并且在它们里面分别填充Mouse和Hamster对象(本章早些时候已定义了这些类;注意必须先编译HamsterMaze.java和WorksAnyway.java,否则下面的程序不能编译)。由于Enumeration隐藏了基层集合的结构,所以PrintData不知道或者不关心Enumeration来自于什么类型的集合:
//: Enumerators2.java
// Revisiting Enumerations
import java.util.*;
class PrintData {
static void print(Enumeration e) {
while(e.hasMoreElements())
System.out.println(
e.nextElement().toString());
}
}
class Enumerators2 {
public static void main(String[] args) {
Vector v = new Vector();
for(int i = 0; i < 5; i++)
v.addElement(new Mouse(i));
Hashtable h = new Hashtable();
for(int i = 0; i < 5; i++)
h.put(new Integer(i), new Hamster(i));
System.out.println("Vector");
PrintData.print(v.elements());
System.out.println("Hashtable");
PrintData.print(h.elements());
}
} ///:~注意PrintData.print()利用了这些集合中的对象属于Object类这一事实,所以它调用了toString()。但在解决自己的实际问题时,经常都要保证自己的Enumeration穿越某种特定类型的集合。例如,可能要求集合中的所有元素都是一个Shape(几何形状),并含有draw()方法。若出现这种情况,必须从Enumeration.nextElement()返回的Object进行下溯造型,以便产生一个Shape。
8.5 排序
Java 1.0和1.1库都缺少的一样东西是算术运算,甚至没有最简单的排序运算方法。因此,我们最好创建一个Vector,利用经典的Quicksort(快速排序)方法对其自身进行排序。
编写通用的排序代码时,面临的一个问题是必须根据对象的实际类型来执行比较运算,从而实现正确的排序。当然,一个办法是为每种不同的类型都写一个不同的排序方法。然而,应认识到假若这样做,以后增加新类型时便不易实现代码的重复利用。
程序设计一个主要的目标就是“将发生变化的东西同保持不变的东西分隔开”。在这里,保持不变的代码是通用的排序算法,而每次使用时都要变化的是对象的实际比较方法。因此,我们不可将比较代码“硬编码”到多个不同的排序例程内,而是采用“回调”技术。利用回调,经常发生变化的那部分代码会封装到它自己的类内,而总是保持相同的代码则“回调”发生变化的代码。这样一来,不同的对象就可以表达不同的比较方式,同时向它们传递相同的排序代码。
下面这个“接口”(Interface)展示了如何比较两个对象,它将那些“要发生变化的东西”封装在内:
//: Compare.java
// Interface for sorting callback:
package c08;
interface Compare {
boolean lessThan(Object lhs, Object rhs);
boolean lessThanOrEqual(Object lhs, Object rhs);
} ///:~对这两种方法来说,lhs代表本次比较中的“左手”对象,而rhs代表“右手”对象。
可创建Vector的一个子类,通过Compare实现“快速排序”。对于这种算法,包括它的速度以及原理等等,在此不具体说明。欲知详情,可参考Binstock和Rex编著的《Practical Algorithms for Programmers》,由Addison-Wesley于1995年出版。
//: SortVector.java
// A generic sorting vector
package c08;
import java.util.*;
public class SortVector extends Vector {
private Compare compare; // To hold the callback
public SortVector(Compare comp) {
compare = comp;
}
public void sort() {
quickSort(0, size() - 1);
}
private void quickSort(int left, int right) {
if(right > left) {
Object o1 = elementAt(right);
int i = left - 1;
int j = right;
while(true) {
while(compare.lessThan(
elementAt(++i), o1))
;
while(j > 0)
if(compare.lessThanOrEqual(
elementAt(--j), o1))
break; // out of while
if(i >= j) break;
swap(i, j);
}
swap(i , right);
quickSort(left, i-1);
quickSort(i+1, right);
}
}
private void swap(int loc1, int loc2) {
Object tmp = elementAt(loc1);
setElementAt(elementAt(loc2), loc1);
setElementAt(tmp, loc2);
}
} ///:~现在,大家可以明白“回调”一词的来历,这是由于quickSort()方法“往回调用”了Compare中的方法。从中亦可理解这种技术如何生成通用的、可重复利用(再生)的代码。
为使用SortVector,必须创建一个类,令其为我们准备排序的对象实现Compare。此时内部类并不显得特别重要,但对于代码的组织却是有益的。下面是针对String对象的一个例子:
//: StringSortTest.java
// Testing the generic sorting Vector
package c08;
import java.util.*;
public class StringSortTest {
static class StringCompare implements Compare {
public boolean lessThan(Object l, Object r) {
return ((String)l).toLowerCase().compareTo(
((String)r).toLowerCase()) < 0;
}
public boolean
lessThanOrEqual(Object l, Object r) {
return ((String)l).toLowerCase().compareTo(
((String)r).toLowerCase()) <= 0;
}
}
public static void main(String[] args) {
SortVector sv =
new SortVector(new StringCompare());
sv.addElement("d");
sv.addElement("A");
sv.addElement("C");
sv.addElement("c");
sv.addElement("b");
sv.addElement("B");
sv.addElement("D");
sv.addElement("a");
sv.sort();
Enumeration e = sv.elements();
while(e.hasMoreElements())
System.out.println(e.nextElement());
}
} ///:~内部类是“静态”(Static)的,因为它毋需连接一个外部类即可工作。
大家可以看到,一旦设置好框架,就可以非常方便地重复使用象这样的一个设计——只需简单地写一个类,将“需要发生变化”的东西封装进去,然后将一个对象传给SortVector即可。
比较时将字串强制为小写形式,所以大写A会排列于小写a的旁边,而不会移动一个完全不同的地方。然而,该例也显示了这种方法的一个不足,因为上述测试代码按照出现顺序排列同一个字母的大写和小写形式:A a b B c C d D。但这通常不是一个大问题,因为经常处理的都是更长的字串,所以上述效果不会显露出来(Java 1.2的集合提供了排序功能,已解决了这个问题)。
继承(extends)在这儿用于创建一种新类型的Vector——也就是说,SortVector属于一种Vector,并带有一些附加的功能。继承在这里可发挥很大的作用,但了带来了问题。它使一些方法具有了final属性(已在第7章讲述),所以不能覆盖它们。如果想创建一个排好序的Vector,令其只接收和生成String对象,就会遇到麻烦。因为addElement()和elementAt()都具有final属性,而且它们都是我们必须覆盖的方法,否则便无法实现只能接收和产生String对象。
但在另一方面,请考虑采用“合成”方法:将一个对象置入一个新类的内部。此时,不是改写上述代码来达到这个目的,而是在新类里简单地使用一个SortVector。在这种情况下,用于实现Compare接口的内部类就可以“匿名”地创建。如下所示:
//: StrSortVector.java
// Automatically sorted Vector that
// accepts and produces only Strings
package c08;
import java.util.*;
public class StrSortVector {
private SortVector v = new SortVector(
// Anonymous inner class:
new Compare() {
public boolean
lessThan(Object l, Object r) {
return
((String)l).toLowerCase().compareTo(
((String)r).toLowerCase()) < 0;
}
public boolean
lessThanOrEqual(Object l, Object r) {
return
((String)l).toLowerCase().compareTo(
((String)r).toLowerCase()) <= 0;
}
}
);
private boolean sorted = false;
public void addElement(String s) {
v.addElement(s);
sorted = false;
}
public String elementAt(int index) {
if(!sorted) {
v.sort();
sorted = true;
}
return (String)v.elementAt(index);
}
public Enumeration elements() {
if(!sorted) {
v.sort();
sorted = true;
}
return v.elements();
}
// Test it:
public static void main(String[] args) {
StrSortVector sv = new StrSortVector();
sv.addElement("d");
sv.addElement("A");
sv.addElement("C");
sv.addElement("c");
sv.addElement("b");
sv.addElement("B");
sv.addElement("D");
sv.addElement("a");
Enumeration e = sv.elements();
while(e.hasMoreElements())
System.out.println(e.nextElement());
}
} ///:~这样便可快速再生来自SortVector的代码,从而获得希望的功能。然而,并不是来自SortVector和Vector的所有public方法都能在StrSortVector中出现。若按这种形式再生代码,可在新类里为包含类内的每一个方法都生成一个定义。当然,也可以在刚开始时只添加少数几个,以后根据需要再添加更多的。新类的设计最终会稳定下来。
这种方法的好处在于它仍然只接纳String对象,也只产生String对象。而且相应的检查是在编译期间进行的,而非在运行期。当然,只有addElement()和elementAt()才具备这一特性;elements()仍然会产生一个Enumeration(枚举),它在编译期的类型是未定的。当然,对Enumeration以及在StrSortVector中的类型检查会照旧进行;如果真的有什么错误,运行期间会简单地产生一个违例。事实上,我们在编译或运行期间能保证一切都正确无误吗?(也就是说,“代码测试时也许不能保证”,以及“该程序的用户有可能做一些未经我们测试的事情”)。尽管存在其他选择和争论,使用继承都要容易得多,只是在造型时让人深感不便。同样地,一旦为Java加入参数化类型,就有望解决这个问题。
大家在这个类中可以看到有一个名为“sorted”的标志。每次调用addElement()时,都可对Vector进行排序,而且将其连续保持在一个排好序的状态。但在开始读取之前,人们总是向一个Vector添加大量元素。所以与其在每个addElement()后排序,不如一直等到有人想读取Vector,再对其进行排序。后者的效率要高得多。这种除非绝对必要,否则就不采取行动的方法叫作“懒惰求值”(还有一种类似的技术叫作“懒惰初始化”——除非真的需要一个字段值,否则不进行初始化)。
8.6 通用集合库
通过本章的学习,大家已知道标准Java库提供了一些特别有用的集合,但距完整意义的集合尚远。除此之外,象排序这样的算法根本没有提供支持。C++出色的一个地方就是它的库,特别是“标准模板库”(STL)提供了一套相当完整的集合,以及许多象排序和检索这样的算法,可以非常方便地对那些集合进行操作。有感这一现状,并以这个模型为基础,ObjectSpace公司设计了Java版本的“通用集合库”(从前叫作“Java通用库”,即JGL;但JGL这个缩写形式侵犯了Sun公司的版权——尽管本书仍然沿用这个简称)。这个库尽可能遵照STL的设计(照顾到两种语言间的差异)。JGL实现了许多功能,可满足对一个集合库的大多数常规需求,它与C++的模板机制非常相似。JGL包括相互链接起来的列表、设置、队列、映射、堆栈、序列以及反复器,它们的功能比Enumeration(枚举)强多了。同时提供了一套完整的算法,如检索和排序等。在某些方面,ObjectSpace的设计也显得比Sun的库设计方案“智能”一些。举个例子来说,JGL集合中的方法不会进入final状态,所以很容易继承和改写那些方法。
JGL已包括到一些厂商发行的Java套件中,而且ObjectSpace公司自己也允许所有用户免费使用JGL,包括商业性的使用。详细情况和软件下载可访问http://www.ObjectSpace.com。与JGL配套提供的联机文档做得非常好,可作为自己的一个绝佳起点使用。
8.7 新集合
对我来说,集合类属于最强大的一种工具,特别适合在原创编程中使用。大家可能已感觉到我对Java 1.1提供的集合多少有点儿失望。因此,看到Java 1.2对集合重新引起了正确的注意后,确实令人非常愉快。这个版本的集合也得到了完全的重新设计(由Sun公司的Joshua Bloch)。我认为新设计的集合是Java 1.2中两项最主要的特性之一(另一项是Swing库,将在第13章叙述),因为它们极大方便了我们的编程,也使Java变成一种更成熟的编程系统。
有些设计使得元素间的结合变得更紧密,也更容易让人理解。例如,许多名字都变得更短、更明确了,而且更易使用;类型同样如此。有些名字进行了修改,更接近于通俗:我感觉特别好的一个是用“反复器”(Inerator)代替了“枚举”(Enumeration)。
此次重新设计也加强了集合库的功能。现在新增的行为包括链接列表、队列以及撤消组队(即“双终点队列”)。
集合库的设计是相当困难的(会遇到大量库设计问题)。在C++中,STL用多个不同的类来覆盖基础。这种做法比起STL以前是个很大的进步,那时根本没做这方面的考虑。但仍然没有很好地转换到Java里面。结果就是一大堆特别容易混淆的类。在另一个极端,我曾发现一个集合库由单个类构成:colleciton,它同时作为Vector和Hashtable使用。新集合库的设计者则希望达到一种新的平衡:实现人们希望从一个成熟集合库上获得的完整功能,同时又要比STL和其他类似的集合库更易学习和使用。这样得到的结果在某些场合显得有些古怪。但和早期Java库的一些决策不同,这些古怪之处并非偶然出现的,而是以复杂性作为代价,在进行仔细权衡之后得到的结果。这样做也许会延长人们掌握一些库概念的时间,但很快就会发现自己很乐于使用那些新工具,而且变得越来越离不了它。
新的集合库考虑到了“容纳自己对象”的问题,并将其分割成两个明确的概念:
(1) 集合(Collection):一组单独的元素,通常应用了某种规则。在这里,一个List(列表)必须按特定的顺序容纳元素,而一个Set(集)不可包含任何重复的元素。相反,“包”(Bag)的概念未在新的集合库中实现,因为“列表”已提供了类似的功能。
(2) 映射(Map):一系列“键-值”对(这已在散列表身上得到了充分的体现)。从表面看,这似乎应该成为一个“键-值”对的“集合”,但假若试图按那种方式实现它,就会发现实现过程相当笨拙。这进一步证明了应该分离成单独的概念。另一方面,可以方便地查看Map的某个部分。只需创建一个集合,然后用它表示那一部分即可。这样一来,Map就可以返回自己键的一个Set、一个包含自己值的List或者包含自己“键-值”对的一个List。和数组相似,Map可方便扩充到多个“维”,毋需涉及任何新概念。只需简单地在一个Map里包含其他Map(后者又可以包含更多的Map,以此类推)。
Collection和Map可通过多种形式实现,具体由编程要求决定。下面列出的是一个帮助大家理解的新集合示意图:
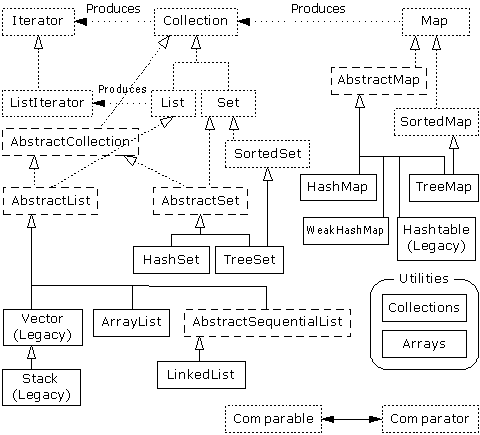
这张图刚开始的时候可能让人有点儿摸不着头脑,但在通读了本章以后,相信大家会真正理解它实际只有三个集合组件:Map,List和Set。而且每个组件实际只有两、三种实现方式(注释⑥),而且通常都只有一种特别好的方式。只要看出了这一点,集合就不会再令人生畏。
⑥:写作本章时,Java 1.2尚处于β测试阶段,所以这张示意图没有包括以后会加入的TreeSet。
虚线框代表“接口”,点线框代表“抽象”类,而实线框代表普通(实际)类。点线箭头表示一个特定的类准备实现一个接口(在抽象类的情况下,则是“部分”实现一个接口)。双线箭头表示一个类可生成箭头指向的那个类的对象。例如,任何集合都可以生成一个反复器(Iterator),而一个列表可以生成一个ListIterator(以及原始的反复器,因为列表是从集合继承的)。
致力于容纳对象的接口是Collection,List,Set和Map。在传统情况下,我们需要写大量代码才能同这些接口打交道。而且为了指定自己想使用的准确类型,必须在创建之初进行设置。所以可能创建下面这样的一个List:
List x = new LinkedList();
当然,也可以决定将x作为一个LinkedList使用(而不是一个普通的List),并用x负载准确的类型信息。使用接口的好处就是一旦决定改变自己的实施细节,要做的全部事情就是在创建的时候改变它,就象下面这样:
List x = new ArrayList();
其余代码可以保持原封不动。
在类的分级结构中,可看到大量以“Abstract”(抽象)开头的类,这刚开始可能会使人感觉迷惑。它们实际上是一些工具,用于“部分”实现一个特定的接口。举个例子来说,假如想生成自己的Set,就不是从Set接口开始,然后自行实现所有方法。相反,我们可以从AbstractSet继承,只需极少的工作即可得到自己的新类。尽管如此,新集合库仍然包含了足够的功能,可满足我们的几乎所有需求。所以考虑到我们的目的,可忽略所有以“Abstract”开头的类。
因此,在观看这张示意图时,真正需要关心的只有位于最顶部的“接口”以及普通(实际)类——均用实线方框包围。通常需要生成实际类的一个对象,将其上溯造型为对应的接口。以后即可在代码的任何地方使用那个接口。下面是一个简单的例子,它用String对象填充一个集合,然后打印出集合内的每一个元素:
//: SimpleCollection.java
// A simple example using the new Collections
package c08.newcollections;
import java.util.*;
public class SimpleCollection {
public static void main(String[] args) {
Collection c = new ArrayList();
for(int i = 0; i < 10; i++)
c.add(Integer.toString(i));
Iterator it = c.iterator();
while(it.hasNext())
System.out.println(it.next());
}
} ///:~新集合库的所有代码示例都置于子目录newcollections下,这样便可提醒自己这些工作只对于Java 1.2有效。这样一来,我们必须用下述代码来调用程序:
java c08.newcollections.SimpleCollection
采用的语法与其他程序是差不多的。
大家可以看到新集合属于java.util库的一部分,所以在使用时不需要再添加任何额外的import语句。
main()的第一行创建了一个ArrayList对象,然后将其上溯造型成为一个集合。由于这个例子只使用了Collection方法,所以从Collection继承的一个类的任何对象都可以正常工作。但ArrayList是一个典型的Collection,它代替了Vector的位置。
显然,add()方法的作用是将一个新元素置入集合里。然而,用户文档谨慎地指出add()“保证这个集合包含了指定的元素”。这一点是为Set作铺垫的,后者只有在元素不存在的前提下才会真的加入那个元素。对于ArrayList以及其他任何形式的List,add()肯定意味着“直接加入”。
利用iterator()方法,所有集合都能生成一个“反复器”(Iterator)。反复器其实就象一个“枚举”(Enumeration),是后者的一个替代物,只是:
(1) 它采用了一个历史上默认、而且早在OOP中得到广泛采纳的名字(反复器)。
(2) 采用了比Enumeration更短的名字:hasNext()代替了hasMoreElement(),而next()代替了nextElement()。
(3) 添加了一个名为remove()的新方法,可删除由Iterator生成的上一个元素。所以每次调用next()的时候,只需调用remove()一次。
在SimpleCollection.java中,大家可看到创建了一个反复器,并用它在集合里遍历,打印出每个元素。
8.7.1 使用Collections
下面这张表格总结了用一个集合能做的所有事情(亦可对Set和List做同样的事情,尽管List还提供了一些额外的功能)。Map不是从Collection继承的,所以要单独对待。
Boolean add(Object) | *Ensures that the Collection contains the argument. Returns false if it doesn’t add the argument. |
Boolean addAll(Collection) | *Adds all the elements in the argument. Returns true if any elements were added. |
void clear( ) | *Removes all the elements in the Collection. |
Boolean contains(Object) | True if the Collection contains the argument. |
Boolean containsAll(Collection) | True if the Collection contains all the elements in the argument. |
Boolean isEmpty( ) | True if the Collection has no elements. |
Iterator iterator( ) | Returns an Iterator that you can use to move through the elements in the Collection. |
Boolean remove(Object) | *If the argument is in the Collection, one instance of that element is removed. Returns true if a removal occurred. |
Boolean removeAll(Collection) | *Removes all the elements that are contained in the argument. Returns true if any removals occurred. |
Boolean retainAll(Collection) | *Retains only elements that are contained in the argument (an “intersection” from set theory). Returns true if any changes occurred. |
int size( ) | Returns the number of elements in the Collection. |
Object[] toArray( ) | Returns an array containing all the elements in the Collection. |
Object[] toArray(Object[] a) | Returns an array containing all the elements in the Collection, whose type is that of the arraya rather than plainObject (you must cast the array to the right type). |
*This is an “optional” method, which means it might not be implemented by a particular Collection. If not, that method throws anUnsupportedOperationException. Exceptions will be covered in Chapter 9. |
boolean add(Object) *保证集合内包含了自变量。如果它没有添加自变量,就返回false(假)
boolean addAll(Collection) *添加自变量内的所有元素。如果没有添加元素,则返回true(真)
void clear() *删除集合内的所有元素
boolean contains(Object) 若集合包含自变量,就返回“真”
boolean containsAll(Collection) 若集合包含了自变量内的所有元素,就返回“真”
boolean isEmpty() 若集合内没有元素,就返回“真”
Iterator iterator() 返回一个反复器,以用它遍历集合的各元素
boolean remove(Object) *如自变量在集合里,就删除那个元素的一个实例。如果已进行了删除,就返回“真”
boolean removeAll(Collection) *删除自变量里的所有元素。如果已进行了任何删除,就返回“真”
boolean retainAll(Collection) *只保留包含在一个自变量里的元素(一个理论的“交集”)。如果已进行了任何改变,就返回“真”
int size() 返回集合内的元素数量
Object[] toArray() 返回包含了集合内所有元素的一个数组
*这是一个“可选的”方法,有的集合可能并未实现它。若确实如此,该方法就会遇到一个UnsupportedOperatiionException,即一个“操作不支持”违例,详见第9章。
下面这个例子向大家演示了所有方法。同样地,它们只对从集合继承的东西有效,一个ArrayList作为一种“不常用的分母”使用:
//: Collection1.java
// Things you can do with all Collections
package c08.newcollections;
import java.util.*;
public class Collection1 {
// Fill with 'size' elements, start
// counting at 'start':
public static Collection
fill(Collection c, int start, int size) {
for(int i = start; i < start + size; i++)
c.add(Integer.toString(i));
return c;
}
// Default to a "start" of 0:
public static Collection
fill(Collection c, int size) {
return fill(c, 0, size);
}
// Default to 10 elements:
public static Collection fill(Collection c) {
return fill(c, 0, 10);
}
// Create & upcast to Collection:
public static Collection newCollection() {
return fill(new ArrayList());
// ArrayList is used for simplicity, but it's
// only seen as a generic Collection
// everywhere else in the program.
}
// Fill a Collection with a range of values:
public static Collection
newCollection(int start, int size) {
return fill(new ArrayList(), start, size);
}
// Moving through a List with an iterator:
public static void print(Collection c) {
for(Iterator x = c.iterator(); x.hasNext();)
System.out.print(x.next() + " ");
System.out.println();
}
public static void main(String[] args) {
Collection c = newCollection();
c.add("ten");
c.add("eleven");
print(c);
// Make an array from the List:
Object[] array = c.toArray();
// Make a String array from the List:
String[] str =
(String[])c.toArray(new String[1]);
// Find max and min elements; this means
// different things depending on the way
// the Comparable interface is implemented:
System.out.println("Collections.max(c) = " +
Collections.max(c));
System.out.println("Collections.min(c) = " +
Collections.min(c));
// Add a Collection to another Collection
c.addAll(newCollection());
print(c);
c.remove("3"); // Removes the first one
print(c);
c.remove("3"); // Removes the second one
print(c);
// Remove all components that are in the
// argument collection:
c.removeAll(newCollection());
print(c);
c.addAll(newCollection());
print(c);
// Is an element in this Collection?
System.out.println(
"c.contains(\"4\") = " + c.contains("4"));
// Is a Collection in this Collection?
System.out.println(
"c.containsAll(newCollection()) = " +
c.containsAll(newCollection()));
Collection c2 = newCollection(5, 3);
// Keep all the elements that are in both
// c and c2 (an intersection of sets):
c.retainAll(c2);
print(c);
// Throw away all the elements in c that
// also appear in c2:
c.removeAll(c2);
System.out.println("c.isEmpty() = " +
c.isEmpty());
c = newCollection();
print(c);
c.clear(); // Remove all elements
System.out.println("after c.clear():");
print(c);
}
} ///:~通过第一个方法,我们可用测试数据填充任何集合。在当前这种情况下,只是将int转换成String。第二个方法将在本章其余的部分经常采用。
newCollection()的两个版本都创建了ArrayList,用于包含不同的数据集,并将它们作为集合对象返回。所以很明显,除了Collection接口之外,不会再用到其他什么。
print()方法也会在本节经常用到。由于它用一个反复器(Iterator)在一个集合内遍历,而任何集合都可以产生这样的一个反复器,所以它适用于List和Set,也适用于由一个Map生成的Collection。
main()用简单的手段显示出了集合内的所有方法。
在后续的小节里,我们将比较List,Set和Map的不同实现方案,同时指出在各种情况下哪一种方案应成为首选(带有星号的那个)。大家会发现这里并未包括一些传统的类,如Vector,Stack以及Hashtable等。因为不管在什么情况下,新集合内都有自己首选的类。
8.7.2 使用Lists
List (interface) | Order is the most important feature of aList; it promises to maintain elements in a particular sequence.List adds a number of methods toCollection that allowinsertion and removal of elements in the middle of aList.(This is recommended only for aLinkedList.)AListwill produce aListIterator, and using this you can traverse theList in both directions, as well as insert and remove elements in the middle of the list (again, recommended only for aLinkedList). |
ArrayList* | AListbacked by an array. Use instead ofVector as a general-purpose object holder. Allows rapid random access to elements, but is slow when inserting and removing elements from the middle of a list.ListIterator should be used only for back-and-forth traversal of anArrayList, but not for inserting and removing elements, which is expensive compared toLinkedList. |
LinkedList | Provides optimal sequential access, with inexpensive insertions and deletions from the middle of the list. Relatively slow for random access. (UseArrayList instead.) Also hasaddFirst( ),addLast( ),getFirst( ),getLast( ),removeFirst( ), andremoveLast( ) (which are not defined in any interfaces or base classes) to allow it to be used as a stack, a queue, and a dequeue. |
List(接口) 顺序是List最重要的特性;它可保证元素按照规定的顺序排列。List为Collection添加了大量方法,以便我们在List中部插入和删除元素(只推荐对LinkedList这样做)。List也会生成一个ListIterator(列表反复器),利用它可在一个列表里朝两个方向遍历,同时插入和删除位于列表中部的元素(同样地,只建议对LinkedList这样做)
ArrayList* 由一个数组后推得到的List。作为一个常规用途的对象容器使用,用于替换原先的Vector。允许我们快速访问元素,但在从列表中部插入和删除元素时,速度却嫌稍慢。一般只应该用ListIterator对一个ArrayList进行向前和向后遍历,不要用它删除和插入元素;与LinkedList相比,它的效率要低许多
LinkedList 提供优化的顺序访问性能,同时可以高效率地在列表中部进行插入和删除操作。但在进行随机访问时,速度却相当慢,此时应换用ArrayList。也提供了addFirst(),addLast(),getFirst(),getLast(),removeFirst()以及removeLast()(未在任何接口或基础类中定义),以便将其作为一个规格、队列以及一个双向队列使用
下面这个例子中的方法每个都覆盖了一组不同的行为:每个列表都能做的事情(basicTest()),通过一个反复器遍历(iterMotion())、用一个反复器改变某些东西(iterManipulation())、体验列表处理的效果(testVisual())以及只有LinkedList才能做的事情等:
//: List1.java
// Things you can do with Lists
package c08.newcollections;
import java.util.*;
public class List1 {
// Wrap Collection1.fill() for convenience:
public static List fill(List a) {
return (List)Collection1.fill(a);
}
// You can use an Iterator, just as with a
// Collection, but you can also use random
// access with get():
public static void print(List a) {
for(int i = 0; i < a.size(); i++)
System.out.print(a.get(i) + " ");
System.out.println();
}
static boolean b;
static Object o;
static int i;
static Iterator it;
static ListIterator lit;
public static void basicTest(List a) {
a.add(1, "x"); // Add at location 1
a.add("x"); // Add at end
// Add a collection:
a.addAll(fill(new ArrayList()));
// Add a collection starting at location 3:
a.addAll(3, fill(new ArrayList()));
b = a.contains("1"); // Is it in there?
// Is the entire collection in there?
b = a.containsAll(fill(new ArrayList()));
// Lists allow random access, which is cheap
// for ArrayList, expensive for LinkedList:
o = a.get(1); // Get object at location 1
i = a.indexOf("1"); // Tell index of object
// indexOf, starting search at location 2:
i = a.indexOf("1", 2);
b = a.isEmpty(); // Any elements inside?
it = a.iterator(); // Ordinary Iterator
lit = a.listIterator(); // ListIterator
lit = a.listIterator(3); // Start at loc 3
i = a.lastIndexOf("1"); // Last match
i = a.lastIndexOf("1", 2); // ...after loc 2
a.remove(1); // Remove location 1
a.remove("3"); // Remove this object
a.set(1, "y"); // Set location 1 to "y"
// Keep everything that's in the argument
// (the intersection of the two sets):
a.retainAll(fill(new ArrayList()));
// Remove elements in this range:
a.removeRange(0, 2);
// Remove everything that's in the argument:
a.removeAll(fill(new ArrayList()));
i = a.size(); // How big is it?
a.clear(); // Remove all elements
}
public static void iterMotion(List a) {
ListIterator it = a.listIterator();
b = it.hasNext();
b = it.hasPrevious();
o = it.next();
i = it.nextIndex();
o = it.previous();
i = it.previousIndex();
}
public static void iterManipulation(List a) {
ListIterator it = a.listIterator();
it.add("47");
// Must move to an element after add():
it.next();
// Remove the element that was just produced:
it.remove();
// Must move to an element after remove():
it.next();
// Change the element that was just produced:
it.set("47");
}
public static void testVisual(List a) {
print(a);
List b = new ArrayList();
fill(b);
System.out.print("b = ");
print(b);
a.addAll(b);
a.addAll(fill(new ArrayList()));
print(a);
// Shrink the list by removing all the
// elements beyond the first 1/2 of the list
System.out.println(a.size());
System.out.println(a.size()/2);
a.removeRange(a.size()/2, a.size()/2 + 2);
print(a);
// Insert, remove, and replace elements
// using a ListIterator:
ListIterator x = a.listIterator(a.size()/2);
x.add("one");
print(a);
System.out.println(x.next());
x.remove();
System.out.println(x.next());
x.set("47");
print(a);
// Traverse the list backwards:
x = a.listIterator(a.size());
while(x.hasPrevious())
System.out.print(x.previous() + " ");
System.out.println();
System.out.println("testVisual finished");
}
// There are some things that only
// LinkedLists can do:
public static void testLinkedList() {
LinkedList ll = new LinkedList();
Collection1.fill(ll, 5);
print(ll);
// Treat it like a stack, pushing:
ll.addFirst("one");
ll.addFirst("two");
print(ll);
// Like "peeking" at the top of a stack:
System.out.println(ll.getFirst());
// Like popping a stack:
System.out.println(ll.removeFirst());
System.out.println(ll.removeFirst());
// Treat it like a queue, pulling elements
// off the tail end:
System.out.println(ll.removeLast());
// With the above operations, it's a dequeue!
print(ll);
}
public static void main(String args[]) {
// Make and fill a new list each time:
basicTest(fill(new LinkedList()));
basicTest(fill(new ArrayList()));
iterMotion(fill(new LinkedList()));
iterMotion(fill(new ArrayList()));
iterManipulation(fill(new LinkedList()));
iterManipulation(fill(new ArrayList()));
testVisual(fill(new LinkedList()));
testLinkedList();
}
} ///:~在basicTest()和iterMotiion()中,只是简单地发出调用,以便揭示出正确的语法。而且尽管捕获了返回值,但是并未使用它。在某些情况下,之所以不捕获返回值,是由于它们没有什么特别的用处。在正式使用它们前,应仔细研究一下自己的联机文档,掌握这些方法完整、正确的用法。
8.7.3 使用Sets
Set拥有与Collection完全相同的接口,所以和两种不同的List不同,它没有什么额外的功能。相反,Set完全就是一个Collection,只是具有不同的行为(这是实例和多形性最理想的应用:用于表达不同的行为)。在这里,一个Set只允许每个对象存在一个实例(正如大家以后会看到的那样,一个对象的“值”的构成是相当复杂的)。
Set(interface) | Each element that you add to theSet must be unique; otherwise theSet doesn’t add the duplicate element. Objects added to aSet must defineequals( ) to establish object uniqueness.Set has exactly the same interface asCollection. TheSet interface does not guarantee it will maintain its elements in any particular order. |
HashSet* | ForSets where fast lookup time is important. Objects must also definehashCode( ). |
TreeSet | An orderedSet backed by a red-black tree. This way, you can extract an ordered sequence from aSet. |
Set(接口) 添加到Set的每个元素都必须是独一无二的;否则Set就不会添加重复的元素。添加到Set里的对象必须定义equals(),从而建立对象的唯一性。Set拥有与Collection完全相同的接口。一个Set不能保证自己可按任何特定的顺序维持自己的元素
HashSet* 用于除非常小的以外的所有Set。对象也必须定义hashCode()
ArraySet 由一个数组后推得到的Set。面向非常小的Set设计,特别是那些需要频繁创建和删除的。对于小Set,与HashSet相比,ArraySet创建和反复所需付出的代价都要小得多。但随着Set的增大,它的性能也会大打折扣。不需要HashCode()
TreeSet 由一个“红黑树”后推得到的顺序Set(注释⑦)。这样一来,我们就可以从一个Set里提到一个顺序集合
⑦:直至本书写作的时候,TreeSet仍然只是宣布,尚未正式实现。所以这里没有提供使用TreeSet的例子。
下面这个例子并没有列出用一个Set能够做的全部事情,因为接口与Collection是相同的,前例已经练习过了。相反,我们要例示的重点在于使一个Set独一无二的行为:
//: Set1.java
// Things you can do with Sets
package c08.newcollections;
import java.util.*;
public class Set1 {
public static void testVisual(Set a) {
Collection1.fill(a);
Collection1.fill(a);
Collection1.fill(a);
Collection1.print(a); // No duplicates!
// Add another set to this one:
a.addAll(a);
a.add("one");
a.add("one");
a.add("one");
Collection1.print(a);
// Look something up:
System.out.println("a.contains(\"one\"): " +
a.contains("one"));
}
public static void main(String[] args) {
testVisual(new HashSet());
testVisual(new TreeSet());
}
} ///:~重复的值被添加到Set,但在打印的时候,我们会发现Set只接受每个值的一个实例。
运行这个程序时,会注意到由HashSet维持的顺序与ArraySet是不同的。这是由于它们采用了不同的方法来保存元素,以便它们以后的定位。ArraySet保持着它们的顺序状态,而HashSet使用一个散列函数,这是特别为快速检索设计的)。创建自己的类型时,一定要注意Set需要通过一种方式来维持一种存储顺序,就象本章早些时候展示的“groundhog”(土拔鼠)例子那样。下面是一个例子:
//: Set2.java
// Putting your own type in a Set
package c08.newcollections;
import java.util.*;
class MyType implements Comparable {
private int i;
public MyType(int n) { i = n; }
public boolean equals(Object o) {
return
(o instanceof MyType)
&& (i == ((MyType)o).i);
}
public int hashCode() { return i; }
public String toString() { return i + " "; }
public int compareTo(Object o) {
int i2 = ((MyType) o).i;
return (i2 < i ? -1 : (i2 == i ? 0 : 1));
}
}
public class Set2 {
public static Set fill(Set a, int size) {
for(int i = 0; i < size; i++)
a.add(new MyType(i));
return a;
}
public static Set fill(Set a) {
return fill(a, 10);
}
public static void test(Set a) {
fill(a);
fill(a); // Try to add duplicates
fill(a);
a.addAll(fill(new TreeSet()));
System.out.println(a);
}
public static void main(String[] args) {
test(new HashSet());
test(new TreeSet());
}
} ///:~对equals()及hashCode()的定义遵照“groundhog”例子已经给出的形式。在两种情况下都必须定义一个equals()。但只有要把类置入一个HashSet的前提下,才有必要使用hashCode()——这种情况是完全有可能的,因为通常应先选择作为一个Set实现。
8.7.4 使用Maps
Map(interface) | Maintains key-value associations (pairs), so you can look up a value using a key. |
HashMap* | Implementation based on a hash table. (Use this instead ofHashtable.) Provides constant-time performance for inserting and locating pairs. Performance can be adjusted via constructors that allow you to set thecapacity andload factor of the hash table. |
TreeMap | Implementation based on a red-black tree. When you view the keys or the pairs, they will be in sorted order (determined byComparable orComparator, discussed later). The point of aTreeMap is that you get the results in sorted order.TreeMapis the onlyMapwith thesubMap( ) method, which allows you to return a portion of the tree. |
Map(接口) 维持“键-值”对应关系(对),以便通过一个键查找相应的值
HashMap* 基于一个散列表实现(用它代替Hashtable)。针对“键-值”对的插入和检索,这种形式具有最稳定的性能。可通过构建器对这一性能进行调整,以便设置散列表的“能力”和“装载因子”
ArrayMap 由一个ArrayList后推得到的Map。对反复的顺序提供了精确的控制。面向非常小的Map设计,特别是那些需要经常创建和删除的。对于非常小的Map,创建和反复所付出的代价要比HashMap低得多。但在Map变大以后,性能也会相应地大幅度降低
TreeMap 在一个“红-黑”树的基础上实现。查看键或者“键-值”对时,它们会按固定的顺序排列(取决于Comparable或Comparator,稍后即会讲到)。TreeMap最大的好处就是我们得到的是已排好序的结果。TreeMap是含有subMap()方法的唯一一种Map,利用它可以返回树的一部分
下例包含了两套测试数据以及一个fill()方法,利用该方法可以用任何两维数组(由Object构成)填充任何Map。这些工具也会在其他Map例子中用到。
//: Map1.java
// Things you can do with Maps
package c08.newcollections;
import java.util.*;
public class Map1 {
public final static String[][] testData1 = {
{ "Happy", "Cheerful disposition" },
{ "Sleepy", "Prefers dark, quiet places" },
{ "Grumpy", "Needs to work on attitude" },
{ "Doc", "Fantasizes about advanced degree"},
{ "Dopey", "'A' for effort" },
{ "Sneezy", "Struggles with allergies" },
{ "Bashful", "Needs self-esteem workshop"},
};
public final static String[][] testData2 = {
{ "Belligerent", "Disruptive influence" },
{ "Lazy", "Motivational problems" },
{ "Comatose", "Excellent behavior" }
};
public static Map fill(Map m, Object[][] o) {
for(int i = 0; i < o.length; i++)
m.put(o[i][0], o[i][1]);
return m;
}
// Producing a Set of the keys:
public static void printKeys(Map m) {
System.out.print("Size = " + m.size() +", ");
System.out.print("Keys: ");
Collection1.print(m.keySet());
}
// Producing a Collection of the values:
public static void printValues(Map m) {
System.out.print("Values: ");
Collection1.print(m.values());
}
// Iterating through Map.Entry objects (pairs):
public static void print(Map m) {
Collection entries = m.entries();
Iterator it = entries.iterator();
while(it.hasNext()) {
Map.Entry e = (Map.Entry)it.next();
System.out.println("Key = " + e.getKey() +
", Value = " + e.getValue());
}
}
public static void test(Map m) {
fill(m, testData1);
// Map has 'Set' behavior for keys:
fill(m, testData1);
printKeys(m);
printValues(m);
print(m);
String key = testData1[4][0];
String value = testData1[4][1];
System.out.println("m.containsKey(\"" + key +
"\"): " + m.containsKey(key));
System.out.println("m.get(\"" + key + "\"): "
+ m.get(key));
System.out.println("m.containsValue(\""
+ value + "\"): " +
m.containsValue(value));
Map m2 = fill(new TreeMap(), testData2);
m.putAll(m2);
printKeys(m);
m.remove(testData2[0][0]);
printKeys(m);
m.clear();
System.out.println("m.isEmpty(): "
+ m.isEmpty());
fill(m, testData1);
// Operations on the Set change the Map:
m.keySet().removeAll(m.keySet());
System.out.println("m.isEmpty(): "
+ m.isEmpty());
}
public static void main(String args[]) {
System.out.println("Testing HashMap");
test(new HashMap());
System.out.println("Testing TreeMap");
test(new TreeMap());
}
} ///:~printKeys(),printValues()以及print()方法并不只是有用的工具,它们也清楚地揭示了一个Map的Collection“景象”的产生过程。keySet()方法会产生一个Set,它由Map中的键后推得来。在这儿,它只被当作一个Collection对待。values()也得到了类似的对待,它的作用是产生一个List,其中包含了Map中的所有值(注意键必须是独一无二的,而值可以有重复)。由于这些Collection是由Map后推得到的,所以一个Collection中的任何改变都会在相应的Map中反映出来。
print()方法的作用是收集由entries产生的Iterator(反复器),并用它同时打印出每个“键-值”对的键和值。程序剩余的部分提供了每种Map操作的简单示例,并对每种类型的Map进行了测试。
当创建自己的类,将其作为Map中的一个键使用时,必须注意到和以前的Set相同的问题。
8.7.5 决定实施方案
从早些时候的那幅示意图可以看出,实际上只有三个集合组件:Map,List和Set。而且每个接口只有两种或三种实施方案。若需使用由一个特定的接口提供的功能,如何才能决定到底采取哪一种方案呢?
为理解这个问题,必须认识到每种不同的实施方案都有自己的特点、优点和缺点。比如在那张示意图中,可以看到Hashtable,Vector和Stack的“特点”是它们都属于“传统”类,所以不会干扰原有的代码。但在另一方面,应尽量避免为新的(Java 1.2)代码使用它们。
其他集合间的差异通常都可归纳为它们具体是由什么“后推”的。换言之,取决于物理意义上用于实施目标接口的数据结构是什么。例如,ArrayList,LinkedList以及Vector(大致等价于ArrayList)都实现了List接口,所以无论选用哪一个,我们的程序都会得到类似的结果。然而,ArrayList(以及Vector)是由一个数组后推得到的;而LinkedList是根据常规的双重链接列表方式实现的,因为每个单独的对象都包含了数据以及指向列表内前后元素的句柄。正是由于这个原因,假如想在一个列表中部进行大量插入和删除操作,那么LinkedList无疑是最恰当的选择(LinkedList还有一些额外的功能,建立于AbstractSequentialList中)。若非如此,就情愿选择ArrayList,它的速度可能要快一些。
作为另一个例子,Set既可作为一个ArraySet实现,亦可作为HashSet实现。ArraySet是由一个ArrayList后推得到的,设计成只支持少量元素,特别适合要求创建和删除大量Set对象的场合使用。然而,一旦需要在自己的Set中容纳大量元素,ArraySet的性能就会大打折扣。写一个需要Set的程序时,应默认选择HashSet。而且只有在某些特殊情况下(对性能的提升有迫切的需求),才应切换到ArraySet。
1. 决定使用何种List
为体会各种List实施方案间的差异,最简便的方法就是进行一次性能测验。下述代码的作用是建立一个内部基础类,将其作为一个测试床使用。然后为每次测验都创建一个匿名内部类。每个这样的内部类都由一个test()方法调用。利用这种方法,可以方便添加和删除测试项目。
//: ListPerformance.java
// Demonstrates performance differences in Lists
package c08.newcollections;
import java.util.*;
public class ListPerformance {
private static final int REPS = 100;
private abstract static class Tester {
String name;
int size; // Test quantity
Tester(String name, int size) {
this.name = name;
this.size = size;
}
abstract void test(List a);
}
private static Tester[] tests = {
new Tester("get", 300) {
void test(List a) {
for(int i = 0; i < REPS; i++) {
for(int j = 0; j < a.size(); j++)
a.get(j);
}
}
},
new Tester("iteration", 300) {
void test(List a) {
for(int i = 0; i < REPS; i++) {
Iterator it = a.iterator();
while(it.hasNext())
it.next();
}
}
},
new Tester("insert", 1000) {
void test(List a) {
int half = a.size()/2;
String s = "test";
ListIterator it = a.listIterator(half);
for(int i = 0; i < size * 10; i++)
it.add(s);
}
},
new Tester("remove", 5000) {
void test(List a) {
ListIterator it = a.listIterator(3);
while(it.hasNext()) {
it.next();
it.remove();
}
}
},
};
public static void test(List a) {
// A trick to print out the class name:
System.out.println("Testing " +
a.getClass().getName());
for(int i = 0; i < tests.length; i++) {
Collection1.fill(a, tests[i].size);
System.out.print(tests[i].name);
long t1 = System.currentTimeMillis();
tests[i].test(a);
long t2 = System.currentTimeMillis();
System.out.println(": " + (t2 - t1));
}
}
public static void main(String[] args) {
test(new ArrayList());
test(new LinkedList());
}
} ///:~内部类Tester是一个抽象类,用于为特定的测试提供一个基础类。它包含了一个要在测试开始时打印的字串、一个用于计算测试次数或元素数量的size参数、用于初始化字段的一个构建器以及一个抽象方法test()。test()做的是最实际的测试工作。各种类型的测试都集中到一个地方:tests数组。我们用继承于Tester的不同匿名内部类来初始化该数组。为添加或删除一个测试项目,只需在数组里简单地添加或移去一个内部类定义即可,其他所有工作都是自动进行的。
首先用元素填充传递给test()的List,然后对tests数组中的测试计时。由于测试用机器的不同,结果当然也会有所区别。这个程序的宗旨是揭示出不同集合类型的相对性能比较。下面是某一次运行得到的结果:
类型 获取 反复 插入 删除
ArrayList 110 270 1920 4780
LinkedList 1870 7580 170 110
可以看出,在ArrayList中进行随机访问(即get())以及循环反复是最划得来的;但对于LinkedList却是一个不小的开销。但另一方面,在列表中部进行插入和删除操作对于LinkedList来说却比ArrayList划算得多。我们最好的做法也许是先选择一个ArrayList作为自己的默认起点。以后若发现由于大量的插入和删除造成了性能的降低,再考虑换成LinkedList不迟。
2. 决定使用何种Set
可在ArraySet以及HashSet间作出选择,具体取决于Set的大小(如果需要从一个Set中获得一个顺序列表,请用TreeSet;注释⑧)。下面这个测试程序将有助于大家作出这方面的抉择:
//: SetPerformance.java
package c08.newcollections;
import java.util.*;
public class SetPerformance {
private static final int REPS = 200;
private abstract static class Tester {
String name;
Tester(String name) { this.name = name; }
abstract void test(Set s, int size);
}
private static Tester[] tests = {
new Tester("add") {
void test(Set s, int size) {
for(int i = 0; i < REPS; i++) {
s.clear();
Collection1.fill(s, size);
}
}
},
new Tester("contains") {
void test(Set s, int size) {
for(int i = 0; i < REPS; i++)
for(int j = 0; j < size; j++)
s.contains(Integer.toString(j));
}
},
new Tester("iteration") {
void test(Set s, int size) {
for(int i = 0; i < REPS * 10; i++) {
Iterator it = s.iterator();
while(it.hasNext())
it.next();
}
}
},
};
public static void test(Set s, int size) {
// A trick to print out the class name:
System.out.println("Testing " +
s.getClass().getName() + " size " + size);
Collection1.fill(s, size);
for(int i = 0; i < tests.length; i++) {
System.out.print(tests[i].name);
long t1 = System.currentTimeMillis();
tests[i].test(s, size);
long t2 = System.currentTimeMillis();
System.out.println(": " +
((double)(t2 - t1)/(double)size));
}
}
public static void main(String[] args) {
// Small:
test(new TreeSet(), 10);
test(new HashSet(), 10);
// Medium:
test(new TreeSet(), 100);
test(new HashSet(), 100);
// Large:
test(new HashSet(), 1000);
test(new TreeSet(), 1000);
}
} ///:~⑧:TreeSet在本书写作时尚未成为一个正式的特性,但在这个例子中可以很轻松地为其添加一个测试。
最后对ArraySet的测试只有500个元素,而不是1000个,因为它太慢了。
类型 测试大小 添加 包含 反复
Type | Test size | Add | Contains | Iteration |
10 | 22.0 | 11.0 | 16.0 | |
TreeSet | 100 | 22.5 | 13.2 | 12.1 |
1000 | 31.1 | 18.7 | 11.8 | |
10 | 5.0 | 6.0 | 27.0 | |
HashSet | 100 | 6.6 | 6.6 | 10.9 |
1000 | 7.4 | 6.6 | 9.5 |
进行add()以及contains()操作时,HashSet显然要比ArraySet出色得多,而且性能明显与元素的多寡关系不大。一般编写程序的时候,几乎永远用不着使用ArraySet。
3. 决定使用何种Map
选择不同的Map实施方案时,注意Map的大小对于性能的影响是最大的,下面这个测试程序清楚地阐示了这一点:
//: MapPerformance.java
// Demonstrates performance differences in Maps
package c08.newcollections;
import java.util.*;
public class MapPerformance {
private static final int REPS = 200;
public static Map fill(Map m, int size) {
for(int i = 0; i < size; i++) {
String x = Integer.toString(i);
m.put(x, x);
}
return m;
}
private abstract static class Tester {
String name;
Tester(String name) { this.name = name; }
abstract void test(Map m, int size);
}
private static Tester[] tests = {
new Tester("put") {
void test(Map m, int size) {
for(int i = 0; i < REPS; i++) {
m.clear();
fill(m, size);
}
}
},
new Tester("get") {
void test(Map m, int size) {
for(int i = 0; i < REPS; i++)
for(int j = 0; j < size; j++)
m.get(Integer.toString(j));
}
},
new Tester("iteration") {
void test(Map m, int size) {
for(int i = 0; i < REPS * 10; i++) {
Iterator it = m.entries().iterator();
while(it.hasNext())
it.next();
}
}
},
};
public static void test(Map m, int size) {
// A trick to print out the class name:
System.out.println("Testing " +
m.getClass().getName() + " size " + size);
fill(m, size);
for(int i = 0; i < tests.length; i++) {
System.out.print(tests[i].name);
long t1 = System.currentTimeMillis();
tests[i].test(m, size);
long t2 = System.currentTimeMillis();
System.out.println(": " +
((double)(t2 - t1)/(double)size));
}
}
public static void main(String[] args) {
// Small:
test(new Hashtable(), 10);
test(new HashMap(), 10);
test(new TreeMap(), 10);
// Medium:
test(new Hashtable(), 100);
test(new HashMap(), 100);
test(new TreeMap(), 100);
// Large:
test(new HashMap(), 1000);
test(new Hashtable(), 1000);
test(new TreeMap(), 1000);
}
} ///:~由于Map的大小是最严重的问题,所以程序的计时测试按Map的大小(或容量)来分割时间,以便得到令人信服的测试结果。下面列出一系列结果(在你的机器上可能不同):
类型 测试大小 置入 取出 反复
Type | Test size | Put | Get | Iteration |
|---|---|---|---|---|
10 | 11.0 | 5.0 | 44.0 | |
Hashtable | 100 | 7.7 | 7.7 | 16.5 |
1000 | 8.0 | 8.0 | 14.4 | |
10 | 16.0 | 11.0 | 22.0 | |
TreeMap | 100 | 25.8 | 15.4 | 13.2 |
1000 | 33.8 | 20.9 | 13.6 | |
10 | 11.0 | 6.0 | 33.0 | |
HashMap | 100 | 8.2 | 7.7 | 13.7 |
1000 | 8.0 | 7.8 | 11.9 |
即使大小为10,ArrayMap的性能也要比HashMap差——除反复循环时以外。而在使用Map时,反复的作用通常并不重要(get()通常是我们时间花得最多的地方)。TreeMap提供了出色的put()以及反复时间,但get()的性能并不佳。但是,我们为什么仍然需要使用TreeMap呢?这样一来,我们可以不把它作为Map使用,而作为创建顺序列表的一种途径。树的本质在于它总是顺序排列的,不必特别进行排序(它的排序方式马上就要讲到)。一旦填充了一个TreeMap,就可以调用keySet()来获得键的一个Set“景象”。然后用toArray()产生包含了那些键的一个数组。随后,可用static方法Array.binarySearch()快速查找排好序的数组中的内容。当然,也许只有在HashMap的行为不可接受的时候,才需要采用这种做法。因为HashMap的设计宗旨就是进行快速的检索操作。最后,当我们使用Map时,首要的选择应该是HashMap。只有在极少数情况下才需要考虑其他方法。
此外,在上面那张表里,有另一个性能问题没有反映出来。下述程序用于测试不同类型Map的创建速度:
//: MapCreation.java
// Demonstrates time differences in Map creation
package c08.newcollections;
import java.util.*;
public class MapCreation {
public static void main(String[] args) {
final long REPS = 100000;
long t1 = System.currentTimeMillis();
System.out.print("Hashtable");
for(long i = 0; i < REPS; i++)
new Hashtable();
long t2 = System.currentTimeMillis();
System.out.println(": " + (t2 - t1));
t1 = System.currentTimeMillis();
System.out.print("TreeMap");
for(long i = 0; i < REPS; i++)
new TreeMap();
t2 = System.currentTimeMillis();
System.out.println(": " + (t2 - t1));
t1 = System.currentTimeMillis();
System.out.print("HashMap");
for(long i = 0; i < REPS; i++)
new HashMap();
t2 = System.currentTimeMillis();
System.out.println(": " + (t2 - t1));
}
} ///:~在写这个程序期间,TreeMap的创建速度比其他两种类型明显快得多(但你应亲自尝试一下,因为据说新版本可能会改善ArrayMap的性能)。考虑到这方面的原因,同时由于前述TreeMap出色的put()性能,所以如果需要创建大量Map,而且只有在以后才需要涉及大量检索操作,那么最佳的策略就是:创建和填充TreeMap;以后检索量增大的时候,再将重要的TreeMap转换成HashMap——使用HashMap(Map)构建器。同样地,只有在事实证明确实存在性能瓶颈后,才应关心这些方面的问题——先用起来,再根据需要加快速度。
8.7.6 未支持的操作
利用static(静态)数组Arrays.toList(),也许能将一个数组转换成List,如下所示:
//: Unsupported.java
// Sometimes methods defined in the Collection
// interfaces don't work!
package c08.newcollections;
import java.util.*;
public class Unsupported {
private static String[] s = {
"one", "two", "three", "four", "five",
"six", "seven", "eight", "nine", "ten",
};
static List a = Arrays.toList(s);
static List a2 = Arrays.toList(
new String[] { s[3], s[4], s[5] });
public static void main(String[] args) {
Collection1.print(a); // Iteration
System.out.println(
"a.contains(" + s[0] + ") = " +
a.contains(s[0]));
System.out.println(
"a.containsAll(a2) = " +
a.containsAll(a2));
System.out.println("a.isEmpty() = " +
a.isEmpty());
System.out.println(
"a.indexOf(" + s[5] + ") = " +
a.indexOf(s[5]));
// Traverse backwards:
ListIterator lit = a.listIterator(a.size());
while(lit.hasPrevious())
System.out.print(lit.previous());
System.out.println();
// Set the elements to different values:
for(int i = 0; i < a.size(); i++)
a.set(i, "47");
Collection1.print(a);
// Compiles, but won't run:
lit.add("X"); // Unsupported operation
a.clear(); // Unsupported
a.add("eleven"); // Unsupported
a.addAll(a2); // Unsupported
a.retainAll(a2); // Unsupported
a.remove(s[0]); // Unsupported
a.removeAll(a2); // Unsupported
}
} ///:~从中可以看出,实际只实现了Collection和List接口的一部分。剩余的方法导致了不受欢迎的一种情况,名为UnsupportedOperationException。在下一章里,我们会讲述违例的详细情况,但在这里有必要进行一下简单说明。这里的关键在于“集合接口”,以及新集合库内的另一些接口,它们都包含了“可选的”方法。在实现那些接口的集合类中,或者提供、或者没有提供对那些方法的支持。若调用一个未获支持的方法,就会导致一个UnsupportedOperationException(操作未支持违例),这表明出现了一个编程错误。
大家或许会觉得奇怪,不是说“接口”和基础类最大的“卖点”就是它们许诺这些方法能产生一些有意义的行为吗?上述违例破坏了那个许诺——它调用的一部分方法不仅不能产生有意义的行为,而且还会中止程序的运行。在这些情况下,类型的所谓安全保证似乎显得一钱不值!但是,情况并没有想象的那么坏。通过Collection,List,Set或者Map,编译器仍然限制我们只能调用那个接口中的方法,所以它和Smalltalk还是存在一些区别的(在Smalltalk中,可为任何对象调用任何方法,而且只有在运行程序时才知道这些调用是否可行)。除此以外,以Collection作为自变量的大多数方法只能从那个集合中读取数据——Collection的所有“read”方法都不是可选的。
这样一来,系统就可避免在设计期间出现接口的冲突。而在集合库的其他设计方案中,最终经常都会得到数量过多的接口,用它们描述基本方案的每一种变化形式,所以学习和掌握显得非常困难。有些时候,甚至难于捕捉接口中的所有特殊情况,因为人们可能设计出任何新接口。但Java的“不支持的操作”方法却达到了新集合库的一个重要设计目标:易于学习和使用。但是,为了使这一方法真正有效,却需满足下述条件:
(1) UnsupportedOperationException必须属于一种“非常”事件。也就是说,对于大多数类来说,所有操作都应是可行的。只有在一些特殊情况下,一、两个操作才可能未获支持。新集合库满足了这一条件,因为绝大多数时候用到的类——ArrayList,LinkedList,HashList和HashMap,以及其他集合方案——都提供了对所有操作的支持。但是,如果想新建一个集合,同时不想为集合接口中的所有方法都提供有意义的定义,同时令其仍与现有库配合,这种设计方法也确实提供了一个“后门”可以利用。
(2) 若一个操作未获支持,那么UnsupportedOperationException(未支持的操作违例)极有可能在实现期间出现,则不是在产品已交付给客户以后才会出现。它毕竟指出的是一个编程错误——不正确地使用了一个类。这一点不能十分确定,通过也可以看出这种方案的“试验”特征——只有经过多次试验,才能找出最理想的工作方式。
在上面的例子中,Arrays.toList()产生了一个List(列表),该列表是由一个固定长度的数组后推出来的。因此唯一能够支持的就是那些不改变数组长度的操作。在另一方面,若请求一个新接口表达不同种类的行为(可能叫作“FixedSizeList”——固定长度列表),就有遭遇更大的复杂程度的危险。这样一来,以后试图使用库的时候,很快就会发现自己不知从何处下手。
对那些采用Collection,List,Set或者Map作为参数的方法,它们的文档应当指出哪些可选的方法是必须实现的。举个例子来说,排序要求实现set()和Iterator.set()方法,但不包括add()和remove()。
8.7.7 排序和搜索
Java 1.2添加了自己的一套实用工具,可用来对数组或列表进行排列和搜索。这些工具都属于两个新类的“静态”方法。这两个类分别是用于排序和搜索数组的Arrays,以及用于排序和搜索列表的Collections。
1. 数组
Arrays类为所有基本数据类型的数组提供了一个过载的sort()和binarySearch(),它们亦可用于String和Object。下面这个例子显示出如何排序和搜索一个字节数组(其他所有基本数据类型都是类似的)以及一个String数组:
//: Array1.java
// Testing the sorting & searching in Arrays
package c08.newcollections;
import java.util.*;
public class Array1 {
static Random r = new Random();
static String ssource =
"ABCDEFGHIJKLMNOPQRSTUVWXYZ" +
"abcdefghijklmnopqrstuvwxyz";
static char[] src = ssource.toCharArray();
// Create a random String
public static String randString(int length) {
char[] buf = new char[length];
int rnd;
for(int i = 0; i < length; i++) {
rnd = Math.abs(r.nextInt()) % src.length;
buf[i] = src[rnd];
}
return new String(buf);
}
// Create a random array of Strings:
public static
String[] randStrings(int length, int size) {
String[] s = new String[size];
for(int i = 0; i < size; i++)
s[i] = randString(length);
return s;
}
public static void print(byte[] b) {
for(int i = 0; i < b.length; i++)
System.out.print(b[i] + " ");
System.out.println();
}
public static void print(String[] s) {
for(int i = 0; i < s.length; i++)
System.out.print(s[i] + " ");
System.out.println();
}
public static void main(String[] args) {
byte[] b = new byte[15];
r.nextBytes(b); // Fill with random bytes
print(b);
Arrays.sort(b);
print(b);
int loc = Arrays.binarySearch(b, b[10]);
System.out.println("Location of " + b[10] +
" = " + loc);
// Test String sort & search:
String[] s = randStrings(4, 10);
print(s);
Arrays.sort(s);
print(s);
loc = Arrays.binarySearch(s, s[4]);
System.out.println("Location of " + s[4] +
" = " + loc);
}
} ///:~类的第一部分包含了用于产生随机字串对象的实用工具,可供选择的随机字母保存在一个字符数组中。randString()返回一个任意长度的字串;而readStrings()创建随机字串的一个数组,同时给定每个字串的长度以及希望的数组大小。两个print()方法简化了对示范数组的显示。在main()中,Random.nextBytes()用随机选择的字节填充数组自变量(没有对应的Random方法用于创建其他基本数据类型的数组)。获得一个数组后,便可发现为了执行sort()或者binarySearch(),只需发出一次方法调用即可。与binarySearch()有关的还有一个重要的警告:若在执行一次binarySearch()之前不调用sort(),便会发生不可预测的行为,其中甚至包括无限循环。
对String的排序以及搜索是相似的,但在运行程序的时候,我们会注意到一个有趣的现象:排序遵守的是字典顺序,亦即大写字母在字符集中位于小写字母的前面。因此,所有大写字母都位于列表的最前面,后面再跟上小写字母——Z居然位于a的前面。似乎连电话簿也是这样排序的。
2. 可比较与比较器
但假若我们不满足这一排序方式,又该如何处理呢?例如本书后面的索引,如果必须对以A或a开头的词条分别到两处地方查看,那么肯定会使读者颇不耐烦。
若想对一个Object数组进行排序,那么必须解决一个问题。根据什么来判定两个Object的顺序呢?不幸的是,最初的Java设计者并不认为这是一个重要的问题,否则就已经在根类Object里定义它了。这样造成的一个后果便是:必须从外部进行Object的排序,而且新的集合库提供了实现这一操作的标准方式(最理想的是在Object里定义它)。
针对Object数组(以及String,它当然属于Object的一种),可使用一个sort(),并令其接纳另一个参数:实现了Comparator接口(即“比较器”接口,新集合库的一部分)的一个对象,并用它的单个compare()方法进行比较。这个方法将两个准备比较的对象作为自己的参数使用——若第一个参数小于第二个,返回一个负整数;若相等,返回零;若第一个参数大于第二个,则返回正整数。基于这一规则,上述例子的String部分便可重新写过,令其进行真正按字母顺序的排序:
//: AlphaComp.java
// Using Comparator to perform an alphabetic sort
package c08.newcollections;
import java.util.*;
public class AlphaComp implements Comparator {
public int compare(Object o1, Object o2) {
// Assume it's used only for Strings...
String s1 = ((String)o1).toLowerCase();
String s2 = ((String)o2).toLowerCase();
return s1.compareTo(s2);
}
public static void main(String[] args) {
String[] s = Array1.randStrings(4, 10);
Array1.print(s);
AlphaComp ac = new AlphaComp();
Arrays.sort(s, ac);
Array1.print(s);
// Must use the Comparator to search, also:
int loc = Arrays.binarySearch(s, s[3], ac);
System.out.println("Location of " + s[3] +
" = " + loc);
}
} ///:~通过造型为String,compare()方法会进行“暗示”性的测试,保证自己操作的只能是String对象——运行期系统会捕获任何差错。将两个字串都强迫换成小写形式后,String.compareTo()方法会产生预期的结果。
若用自己的Comparator来进行一次sort(),那么在使用binarySearch()时必须使用那个相同的Comparator。
Arrays类提供了另一个sort()方法,它会采用单个自变量:一个Object数组,但没有Comparator。这个sort()方法也必须用同样的方式来比较两个Object。通过实现Comparable接口,它采用了赋予一个类的“自然比较方法”。这个接口含有单独一个方法——compareTo(),能分别根据它小于、等于或者大于自变量而返回负数、零或者正数,从而实现对象的比较。下面这个例子简单地阐示了这一点:
//: CompClass.java
// A class that implements Comparable
package c08.newcollections;
import java.util.*;
public class CompClass implements Comparable {
private int i;
public CompClass(int ii) { i = ii; }
public int compareTo(Object o) {
// Implicitly tests for correct type:
int argi = ((CompClass)o).i;
if(i == argi) return 0;
if(i < argi) return -1;
return 1;
}
public static void print(Object[] a) {
for(int i = 0; i < a.length; i++)
System.out.print(a[i] + " ");
System.out.println();
}
public String toString() { return i + ""; }
public static void main(String[] args) {
CompClass[] a = new CompClass[20];
for(int i = 0; i < a.length; i++)
a[i] = new CompClass(
(int)(Math.random() *100));
print(a);
Arrays.sort(a);
print(a);
int loc = Arrays.binarySearch(a, a[3]);
System.out.println("Location of " + a[3] +
" = " + loc);
}
} ///:~当然,我们的compareTo()方法亦可根据实际情况增大复杂程度。
3. 列表
可用与数组相同的形式排序和搜索一个列表(List)。用于排序和搜索列表的静态方法包含在类Collections中,但它们拥有与Arrays中差不多的签名:sort(List)用于对一个实现了Comparable的对象列表进行排序;binarySearch(List,Object)用于查找列表中的某个对象;sort(List,Comparator)利用一个“比较器”对一个列表进行排序;而binarySearch(List,Object,Comparator)则用于查找那个列表中的一个对象(注释⑨)。下面这个例子利用了预先定义好的CompClass和AlphaComp来示范Collections中的各种排序工具:
//: ListSort.java
// Sorting and searching Lists with 'Collections'
package c08.newcollections;
import java.util.*;
public class ListSort {
public static void main(String[] args) {
final int SZ = 20;
// Using "natural comparison method":
List a = new ArrayList();
for(int i = 0; i < SZ; i++)
a.add(new CompClass(
(int)(Math.random() *100)));
Collection1.print(a);
Collections.sort(a);
Collection1.print(a);
Object find = a.get(SZ/2);
int loc = Collections.binarySearch(a, find);
System.out.println("Location of " + find +
" = " + loc);
// Using a Comparator:
List b = new ArrayList();
for(int i = 0; i < SZ; i++)
b.add(Array1.randString(4));
Collection1.print(b);
AlphaComp ac = new AlphaComp();
Collections.sort(b, ac);
Collection1.print(b);
find = b.get(SZ/2);
// Must use the Comparator to search, also:
loc = Collections.binarySearch(b, find, ac);
System.out.println("Location of " + find +
" = " + loc);
}
} ///:~ ⑨:在本书写作时,已宣布了一个新的Collections.stableSort(),可用它进行合并式排序,但还没有它的测试版问世。
这些方法的用法与在Arrays中的用法是完全一致的,只是用一个列表代替了数组。
TreeMap也必须根据Comparable或者Comparator对自己的对象进行排序。
8.7.8 实用工具
Collections类中含有其他大量有用的实用工具:
enumeration(Collection) | Produces an old-styleEnumeration for the argument. |
max(Collection) min(Collection) | Produces the maximum or minimum element in the argument using the natural comparison method of the objects in theCollection. |
max(Collection, Comparator) min(Collection, Comparator) | Produces the maximum or minimum element in theCollection using theComparator. |
nCopies(int n, Object o) | Returns an immutableList of sizen whose handles all point too. |
subList(List, int min, int max) | Returns a newList backed by the specified argumentList that is a window into that argument with indexes starting atmin and stopping just beforemax. |
enumeration(Collection) 为自变量产生原始风格的Enumeration(枚举)
max(Collection),min(Collection) 在自变量中用集合内对象的自然比较方法产生最大或最小元素
max(Collection,Comparator),min(Collection,Comparator) 在集合内用比较器产生最大或最小元素
nCopies(int n, Object o) 返回长度为n的一个不可变列表,它的所有句柄均指向o
subList(List,int min,int max) 返回由指定参数列表后推得到的一个新列表。可将这个列表想象成一个“窗口”,它自索引为min的地方开始,正好结束于max的前面
注意min()和max()都是随同Collection对象工作的,而非随同List,所以不必担心Collection是否需要排序(就象早先指出的那样,在执行一次binarySearch()——即二进制搜索——之前,必须对一个List或者一个数组执行sort())。
1. 使Collection或Map不可修改
通常,创建Collection或Map的一个“只读”版本显得更有利一些。Collections类允许我们达到这个目标,方法是将原始容器传递进入一个方法,并令其传回一个只读版本。这个方法共有四种变化形式,分别用于Collection(如果不想把集合当作一种更特殊的类型对待)、List、Set以及Map。下面这个例子演示了为它们分别构建只读版本的正确方法:
//: ReadOnly.java
// Using the Collections.unmodifiable methods
package c08.newcollections;
import java.util.*;
public class ReadOnly {
public static void main(String[] args) {
Collection c = new ArrayList();
Collection1.fill(c); // Insert useful data
c = Collections.unmodifiableCollection(c);
Collection1.print(c); // Reading is OK
//! c.add("one"); // Can't change it
List a = new ArrayList();
Collection1.fill(a);
a = Collections.unmodifiableList(a);
ListIterator lit = a.listIterator();
System.out.println(lit.next()); // Reading OK
//! lit.add("one"); // Can't change it
Set s = new HashSet();
Collection1.fill(s);
s = Collections.unmodifiableSet(s);
Collection1.print(s); // Reading OK
//! s.add("one"); // Can't change it
Map m = new HashMap();
Map1.fill(m, Map1.testData1);
m = Collections.unmodifiableMap(m);
Map1.print(m); // Reading OK
//! m.put("Ralph", "Howdy!");
}
} ///:~对于每种情况,在将其正式变为只读以前,都必须用有有效的数据填充容器。一旦载入成功,最佳的做法就是用“不可修改”调用产生的句柄替换现有的句柄。这样做可有效避免将其变成不可修改后不慎改变其中的内容。在另一方面,该工具也允许我们在一个类中将能够修改的容器保持为private状态,并可从一个方法调用中返回指向那个容器的一个只读句柄。这样一来,虽然我们可在类里修改它,但其他任何人都只能读。
为特定类型调用“不可修改”的方法不会造成编译期间的检查,但一旦发生任何变化,对修改特定容器的方法的调用便会产生一个UnsupportedOperationException违例。
2. Collection或Map的同步
synchronized关键字是“多线程”机制一个非常重要的部分。我们到第14章才会对这一机制作深入的探讨。在这儿,大家只需注意到Collections类提供了对整个容器进行自动同步的一种途径。它的语法与“不可修改”的方法是类似的:
//: Synchronization.java
// Using the Collections.synchronized methods
package c08.newcollections;
import java.util.*;
public class Synchronization {
public static void main(String[] args) {
Collection c =
Collections.synchronizedCollection(
new ArrayList());
List list = Collections.synchronizedList(
new ArrayList());
Set s = Collections.synchronizedSet(
new HashSet());
Map m = Collections.synchronizedMap(
new HashMap());
}
} ///:~在这种情况下,我们通过适当的“同步”方法直接传递新容器;这样做可避免不慎暴露出未同步的版本。
新集合也提供了能防止多个进程同时修改一个容器内容的机制。若在一个容器里反复,同时另一些进程介入,并在那个容器中插入、删除或修改一个对象,便会面临发生冲突的危险。我们可能已传递了那个对象,可能它位位于我们前面,可能容器的大小在我们调用size()后已发生了收缩——我们面临各种各样可能的危险。针对这个问题,新的集合库集成了一套解决的机制,能查出除我们的进程自己需要负责的之外的、对容器的其他任何修改。若探测到有其他方面也准备修改容器,便会立即产生一个ConcurrentModificationException(并发修改违例)。我们将这一机制称为“立即失败”——它并不用更复杂的算法在“以后”侦测问题,而是“立即”产生违例。
8.8 总结
下面复习一下由标准Java(1.0和1.1)库提供的集合(BitSet未包括在这里,因为它更象一种负有特殊使命的类):
(1) 数组包含了对象的数字化索引。它容纳的是一种已知类型的对象,所以在查找一个对象时,不必对结果进行造型处理。数组可以是多维的,而且能够容纳基本数据类型。但是,一旦把它创建好以后,大小便不能变化了。
(2) Vector(矢量)也包含了对象的数字索引——可将数组和Vector想象成随机访问集合。当我们加入更多的元素时,Vector能够自动改变自身的大小。但Vector只能容纳对象的句柄,所以它不可包含基本数据类型;而且将一个对象句柄从集合中取出来的时候,必须对结果进行造型处理。
(3) Hashtable(散列表)属于Dictionary(字典)的一种类型,是一种将对象(而不是数字)同其他对象关联到一起的方式。散列表也支持对对象的随机访问,事实上,它的整个设计方案都在突出访问的“高速度”。
(4) Stack(堆栈)是一种“后入先出”(LIFO)的队列。
若你曾经熟悉数据结构,可能会疑惑为何没看到一套更大的集合。从功能的角度出发,你真的需要一套更大的集合吗?对于Hashtable,可将任何东西置入其中,并以非常快的速度检索;对于Enumeration(枚举),可遍历一个序列,并对其中的每个元素都采取一个特定的操作。那是一种功能足够强劲的工具。
但Hashtable没有“顺序”的概念。Vector和数组为我们提供了一种线性顺序,但若要把一个元素插入它们任何一个的中部,一般都要付出“惨重”的代价。除此以外,队列、拆散队列、优先级队列以及树都涉及到元素的“排序”——并非仅仅将它们置入,以便以后能按线性顺序查找或移动它们。这些数据结构也非常有用,这也正是标准C++中包含了它们的原因。考虑到这个原因,只应将标准Java库的集合看作自己的一个起点。而且倘若必须使用Java 1.0或1.1,则可在需要超越它们的时候使用JGL。
如果能使用Java 1.2,那么只使用新集合即可,它一般能满足我们的所有需要。注意本书在Java 1.1身上花了大量篇幅,所以书中用到的大量集合都是只能在Java1.1中用到的那些:Vector和Hashtable。就目前来看,这是一个不得以而为之的做法。但是,这样处理亦可提供与老Java代码更出色的向后兼容能力。若要用Java1.2写新代码,新的集合往往能更好地为你服务。
8.9 练习
(1) 新建一个名为Gerbil的类,在构建器中初始化一个int gerbilNumber(类似本章的Mouse例子)。为其写一个名为hop()的方法,用它打印出符合hop()条件的Gerbil的编号。建一个Vector,并为Vector添加一系列Gerbil对象。现在,用elementAt()方法在Vector中遍历,并为每个Gerbil都调用hop()。
(2) 修改练习1,用Enumeration在调用hop()的同时遍历Vector。
(3) 在AssocArray.java中,修改这个例子,令其使用一个Hashtable,而不是AssocArray。
(4) 获取练习1用到的Gerbil类,改为把它置入一个Hashtable,然后将Gerbil的名称作为一个String(键)与置入表格的每个Gerbil(值)都关联起来。获得用于keys()的一个Enumeration,并用它在Hashtable里遍历,查找每个键的Gerbil,打印出键,然后将gerbil告诉给hop()。
(5) 修改第7章的练习1,用一个Vector容纳Rodent(啮齿动物),并用Enumeration在Rodent序列中遍历。记住Vector只能容纳对象,所以在访问单独的Rodent时必须采用一个造型(如RTTI)。
(6) 转到第7章的中间位置,找到那个GreenhouseControls.java(温室控制)例子,该例应该由三个文件构成。在Controller.java中,类EventSet仅是一个集合。修改它的代码,用一个Stack代替EventSet。当然,这时可能并不仅仅用Stack取代EventSet这样简单;也需要用一个Enumeration遍历事件集。可考虑在某些时候将集合当作Stack对待,另一些时候则当作Vector对待——这样或许能使事情变得更加简单。
(7) (有一定挑战性)在与所有Java发行包配套提供的Java源码库中找出用于Vector的源码。复制这些代码,制作名为intVector的一个特殊版本,只在其中包含int数据。思考是否能为所有基本数据类型都制作Vector的一个特殊版本。接下来,考虑假如制作一个链接列表类,令其能随同所有基本数据类型使用,那么会发生什么情况。若在Java中提供了参数化类型,利用它们便可自动完成这一工作(还有其他许多好处)。