
Spark Streaming
Spark streaming是Spark核心API的一个扩展,它对实时流式数据的处理具有可扩展性、高吞吐量、可容错性等特点。我们可以从kafka、flume、Twitter、 ZeroMQ、Kinesis等源获取数据,也可以通过由 高阶函数map、reduce、join、window等组成的复杂算法计算出数据。最后,处理后的数据可以推送到文件系统、数据库、实时仪表盘中。事实上,你可以将处理后的数据应用到Spark的机器学习算法、 图处理算法中去。

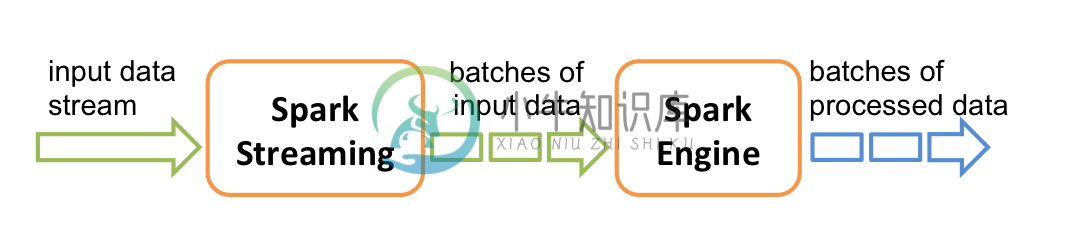
在内部,它的工作原理如下图所示。Spark Streaming接收实时的输入数据流,然后将这些数据切分为批数据供Spark引擎处理,Spark引擎将数据生成最终的结果数据。
Spark Streaming支持一个高层的抽象,叫做离散流(discretized stream)或者DStream,它代表连续的数据流。DStream既可以利用从Kafka, Flume和Kinesis等源获取的输入数据流创建,也可以 在其他DStream的基础上通过高阶函数获得。在内部,DStream是由一系列RDDs组成。
本指南指导用户开始利用DStream编写Spark Streaming程序。用户能够利用scala、java或者Python来编写Spark Streaming程序。
注意:Spark 1.2已经为Spark Streaming引入了Python API。它的所有DStream transformations和几乎所有的输出操作可以在scala和java接口中使用。然而,它只支持基本的源如文本文件或者套接字上 的文本数据。诸如flume、kafka等外部的源的API会在将来引入。
- 一个快速的例子
- 基本概念
- 关联
- 初始化StreamingContext
- 离散流
- 输入DStreams
- DStream中的转换
- DStream的输出操作
- 缓存或持久化
- Checkpointing
- 部署应用程序
- 监控应用程序
- 性能调优
- 减少批数据的执行时间
- 设置正确的批容量
- 内存调优
- 容错语义