
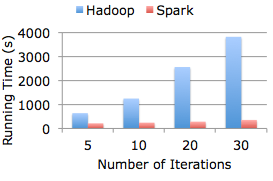
Apache Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoo 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
一个简单的计算:
file = spark.textFile("hdfs://...")
file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)-
Apache Spark 简介 Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写
-
Spark产生的原因: 1、MapReduce具有很多的局限性,仅支持Map和Reduce两种操作,还有迭代效率比较低,不适合交互式的处理,不擅长流式处理。 2、现有的各种计算框架各自为战。 Spark就是在一个统一的框架下能够进行批处理,流式计算和交互式计算。 Spark的核心概念就是RDD(弹性分布式数据集)分布在集群中的对象集合,存储在磁盘或内存中。通过并行“转换”操作构造,失效后自动重
-
目前Cloud-ML生态云只有武清集群。这个集群的基本配置如下: 武清集群 集群目前包括若干台CPU和GPU节点。 集群的Endpoint为:https://cnbj2.cloudml.api.xiaomi.com
-
本文向大家介绍集群计算与网格计算之间的区别,包括了集群计算与网格计算之间的区别的使用技巧和注意事项,需要的朋友参考一下 集群计算 群集计算机是指目标是作为同一单元工作的相同类型计算机的网络。当资源匮乏的任务需要较高的计算能力或内存时,可以使用这种网络。将两个或更多相同类型的计算机组合在一起以组成集群并执行任务。 网格计算 网格计算是指由相同或不同类型的计算机组成的网络,其目标是提供一种环境,在该环
-
有没有一种方法可以暂停Dataproc群集,这样当我不积极运行火花外壳或火花提交作业时就不会收到账单?此链接处的群集管理说明:https://cloud.google.com/sdk/gcloud/reference/beta/dataproc/clusters/ 仅演示如何销毁群集,但我安装了spark cassandra连接器API。这是我创建每次都需要安装的映像的唯一选择吗?
-
多集群资源即统一管理集群的命名空间、角色、集群角色等资源并将其映射到多个集群中。 命名空间 命名空间用于逻辑上隔离Kubernetes集群中的资源。 角色 角色定义了对集群的指定命名空间下资源的权限。 集群角色 集群角色定义了对集群下资源的权限。 角色绑定 角色绑定定义了角色绑定和服务账户的绑定关系。 集群角色绑定 集群角色绑定定义了集群角色和服务账户的绑定关系。
-
一、集群规划 这里搭建一个 3 节点的 HBase 集群,其中三台主机上均为 Regin Server。同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop002 上部署备用的 Master 服务。Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Master。 二、前置条件
-
一、集群规划 这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus 服务外,还在 hadoop002 上部署备用的 Nimbus 服务。Nimbus 服务由 Zookeeper 集群进行协调管理,如果主 Nimbus 不可用,则备用 Nimbus 会成为新的主 Nim
-
一、集群规划 这里搭建一个 3 节点的 Hadoop 集群,其中三台主机均部署 DataNode 和 NodeManager 服务,但只有 hadoop001 上部署 NameNode 和 ResourceManager 服务。 二、前置条件 Hadoop 的运行依赖 JDK,需要预先安装。其安装步骤单独整理至: Linux 下 JDK 的安装 三、配置免密登录 3.1 生成密匙 在每台主机上使用
-
为了管理异构和不同配置的主机,为了便于Pod的运维管理,Kubernetes中提供了很多集群管理的配置和管理功能,通过namespace划分的空间,通过为node节点创建label和taint用于pod的调度等。